论文链接:
VGGT:https://arxiv.org/abs/2503.11651
Code:https://github.com/facebookresearch/vggt
参考:https://zhuanlan.zhihu.com/p/31907061782
1 研究背景与动机
之前上学时,一般用的 Bundle Adjustment(BA)迭代优化。近年来,深度学习方法在3D重建中逐渐发挥重要作用。VGGT 实现通过一个前馈神经网络直接从图像中推断出场景的所有关键3D属性,从而避免复杂的后处理步骤,提高效率和性能。
重点:
-
提出VGGT模型:VGGT(Visual Geometry Grounded Transformer)是一个大型前馈Transformer网络,能够直接从单张、几张或数百张图像中推断出场景的所有关键3D属性,包括相机参数、点云图、深度图和3D点轨迹。
-
高效的架构设计:VGGT采用了交替注意力(Alternating-Attention)机制。帧内自注意力(frame-wise self-attention)和全局自注意力(global self-attention),以平衡帧内信息的整合和跨帧信息的交互。
3. Method
Architecture Overview
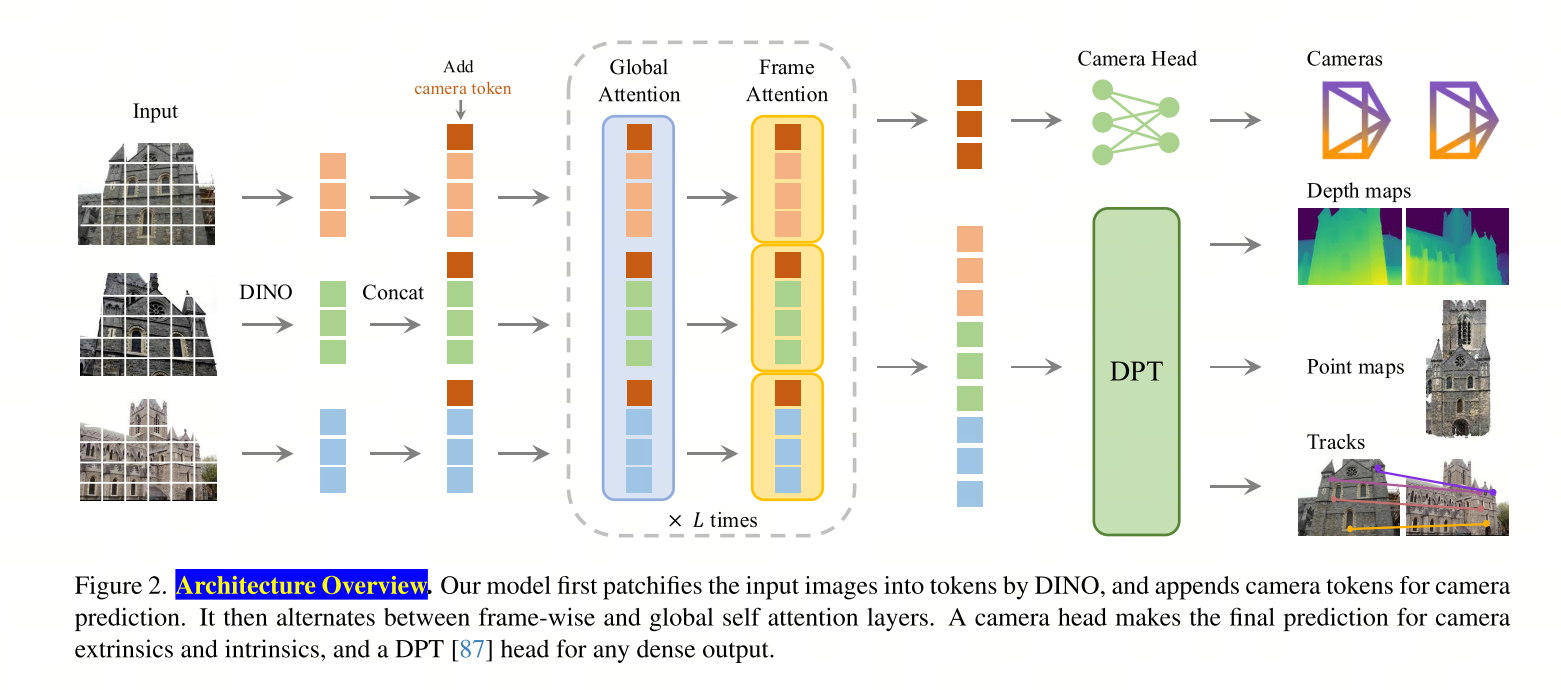
The input is a sequence images, and VGGT gives us the results of camera parameters (intrinsics and extrinsics), depth, points and C-dimensional features for tracking.
3.2 特征主干网络(Feature Backbone)
VGGT的主干网络是一个大型Transformer,其设计遵循以下原则:
- 最小化3D归纳偏置:模型不依赖于任何特定的3D几何假设,而是通过大量的3D标注数据学习。
- 交替注意力机制(Alternating-Attention, AA):Transformer在帧内和全局之间交替进行自注意力操作。帧内自注意力关注单帧内的信息,而全局自注意力则整合所有帧的信息。这种设计平衡了局部和全局信息的融合。
具体来说,输入图像首先通过DINO模型被分割成tokens,然后这些tokens被送入Transformer网络。Transformer包含L=24层交替的帧内和全局自注意力层。
Loss
3.4 训练
训练损失。 我们使用多任务损失对VGVT模型 fff 进行端到端训练:
L=Lcamera+Ldepth+Lpmap+λLtrack(2) \mathcal{L} = \mathcal{L}{\text{camera}} + \mathcal{L}{\text{depth}} + \mathcal{L}{\text{pmap}} + \lambda \mathcal{L}{\text{track}} \quad (2) L=Lcamera+Ldepth+Lpmap+λLtrack(2)
我们发现相机损失 (Lcamera\mathcal{L}{\text{camera}}Lcamera)、深度损失 (Ldepth\mathcal{L}{\text{depth}}Ldepth) 和点图损失 (Lpmap\mathcal{L}{\text{pmap}}Lpmap) 的范围相似,不需要相互加权。跟踪损失 Ltrack\mathcal{L}{\text{track}}Ltrack 的权重因子 λ=0.05\lambda = 0.05λ=0.05。我们依次描述每个损失项。
相机损失 Lcamera\mathcal{L}{\text{camera}}Lcamera 监督预测的相机参数 g^\hat{\mathbf{g}}g^:Lcamera=∑i=1N∥g^i−gi∥e\mathcal{L}{\text{camera}} = \sum_{i=1}^{N} \|\hat{\mathbf{g}}_i - \mathbf{g}_i\|_eLcamera=∑i=1N∥g^i−gi∥e,使用 Huber 损失 ∣⋅∣e|\cdot|_e∣⋅∣e 将预测的相机参数 g^i\hat{\mathbf{g}}_ig^i 与真实值 gi\mathbf{g}_igi 进行比较。
深度损失 Ldepth\mathcal{L}_{\text{depth}}Ldepth 参考 DUST3R 129,并采用偶然不确定性损失 59, 75,用预测的不确定性图 Σ^iD\hat{\Sigma}_i^DΣ^iD 权衡预测深度 D^i\hat{D}_iD^i 与真实深度 DiD_iDi 之间的差异。与 DUST3R 不同的是,我们还应用了一项基于梯度的项,这在单目深度估计中被广泛使用。因此,深度损失为
Ldepth=∑i=1N∥ΣiD⊙(D^i−Di)∥+∥ΣiD⊙(∇D^i−∇Di)∥−αlogΣiD \mathcal{L}{\text{depth}} = \sum{i=1}^{N} \|\Sigma_i^D \odot (\hat{D}_i - D_i)\| + \|\Sigma_i^D \odot (\nabla \hat{D}_i - \nabla D_i)\| - \alpha \log \Sigma_i^D Ldepth=i=1∑N∥ΣiD⊙(D^i−Di)∥+∥ΣiD⊙(∇D^i−∇Di)∥−αlogΣiD
其中 ⊙\odot⊙ 是通道广播的逐元素乘积。点图损失的定义类似,但使用点图不确定性 ΣiP\Sigma_i^PΣiP:
Lpmap=∑i=1N∥ΣiP⊙(P^i−Pi)∥+∥ΣiP⊙(∇P^i−∇Pi)∥−αlogΣiP \mathcal{L}{\text{pmap}} = \sum{i=1}^{N} \|\Sigma_i^P \odot (\hat{P}_i - P_i)\| + \|\Sigma_i^P \odot (\nabla \hat{P}_i - \nabla P_i)\| - \alpha \log \Sigma_i^P Lpmap=i=1∑N∥ΣiP⊙(P^i−Pi)∥+∥ΣiP⊙(∇P^i−∇Pi)∥−αlogΣiP
最后,跟踪损失由 Ltrack=∑j=1M∑i=1N∥yj,i−y^j,i∥\mathcal{L}{\text{track}} = \sum{j=1}^{M} \sum_{i=1}^{N} \|\mathbf{y}{j,i} - \hat{\mathbf{y}}{j,i}\|Ltrack=∑j=1M∑i=1N∥yj,i−y^j,i∥ 给出。这里,外层求和遍历查询图像 IqI_qIq 中所有真实的查询点 yj\mathbf{y}jyj,yj,i\mathbf{y}{j,i}yj,i 是 yj\mathbf{y}jyj 在图像 IiI_iIi 中的真实对应点,y^j,i\hat{\mathbf{y}}{j,i}y^j,i 是应用跟踪模块 T((Ti)i=1N)\mathcal{T}((T_i)_{i=1}^{N})T((Ti)i=1N) 得到的相应预测。此外,遵循 CoTracker2 57,我们应用可见性损失(二元交叉熵)来估计一个点在给定帧中是否可见。
如何处理三维重建中的"尺度模糊性"(Scale Ambiguity)问题
简单来说,就是解决"不知道物体到底有多大"的问题。我们通过对数据进行归一化来消除这种歧义,从而做出一个规范的选择,并让Transformer输出这个特定的变化形式。
以下是分步拆解和通俗理解:
1. 核心问题:尺度模糊性
- 现象:如果你只有一张照片,你无法判断照片里的物体是"一个巨大的山"还是"一个放在桌上的小模型"。因为它们在照片上的成像可能是一模一样的。
- 后果:在三维重建中,如果不加限制,模型可能会输出一个正确的形状,但尺寸可能是任意的(比如把一个人重建成了10米高)。
2. 解决方案:归一化(Normalization)
为了消除这种歧义,作者们引入了一种归一化的方法,强制规定一个"标准尺寸"。
-
第一步:选一个参考系
作者选择第一张相机(g1g_1g1)的坐标系作为所有数据的参考基准。这意味着,所有后续的计算都以第一张照片的视角为基准。
-
第二步:计算"标准尺"
他们计算了点云图 PPP 中所有三维点到原点的平均欧几里得距离。
- 通俗理解:就是算一下所有重建出来的点,平均离镜头有多远。
- 这个"平均距离"就变成了一个尺度因子(Scale Factor)。
-
第三步:强制缩放
用这个算出来的"平均距离"作为标准,去缩放(归一化)第一相机的平移量 ttt、点图 PPP 和深度 DDD。
- 这样做之后,重建出来的物体大小就被固定了,不再随意缩放。
为了让你更直观地理解这个"归一化"过程,我们用一个**"乐高积木"**的例子来模拟三维重建的场景。
场景设定
假设你面前有一个真实的乐高积木,它长 10 厘米。你用手机拍了 3 张不同角度的照片,想通过算法重建出它的三维模型。
第一步:选参考系(第一张照片)
- 操作 :你选择第一张照片的视角作为"世界原点"。
- 比喻 :这就好比你在第一张照片的位置,用尺子量了一下,发现积木离你的手机镜头平均距离是 50 厘米。
第二步:计算"标准尺"(平均距离)
- 操作:算法计算所有重建出来的点(积木的各个角落)到原点的平均距离。
- 比喻 :算法算了一下,发现这些点离镜头的平均距离是 50 厘米。于是,它把 50 厘米 定为"标准尺"。
第三步:强制缩放(归一化)
这是最关键的一步,也是消除"尺度模糊"的核心。
情况 A:模型"看走眼"了(尺度模糊)
- 现象 :由于缺乏真实尺寸信息,模型可能会"看走眼"。它可能把积木重建成了一个巨大的模型 ,比如长 100 米,离镜头的平均距离变成了 500 米。
- 归一化操作 :算法发现平均距离是 500 米,而标准尺是 50 厘米(0.5米)。于是它计算缩放因子:0.5 / 500 = 0.001。
- 结果:模型把整个重建结果(积木大小、距离)都缩小了 1000 倍。最终,积木变回了 10 厘米,距离也变回了 50 厘米。
情况 B:模型"看扁了"
- 现象:模型也可能把积木重建得太小,比如长 1 厘米,平均距离 5 厘米。
- 归一化操作 :缩放因子 = 0.5 / 0.05 = 10。
- 结果:模型把整个结果放大了 10 倍,积木恢复为 10 厘米,距离恢复为 50 厘米。
无论模型最初"看走眼"还是"看扁了",通过**"计算平均距离"和 "强制缩放"这两步,最终都能把物体 拉回到以第一张照片为基准的真实物理尺度**上。
Performance
性能指标很好,具体看原论文。
(结束)