随着AI大模型的兴起,数字基础设施行业正面临前所未有的变革压力,尤其是作为"三大件"之一的存储领域。AI大模型,如ChatGPT和Sora,以其卓越的表现刷新了人们对人工智能的认知,但这些成就背后是对计算资源、网络连接和数据存储能力的极限挑战。
传统上,存储被视为数据的仓库,但在AI大模型的背景下,存储系统已转变为数据处理和分析的积极参与者。存储设备不仅要提供足够的空间来容纳快速增长的数据量,还要具备高效的数据管理能力,以确保数据可以被迅速地访问、处理和利用。特别是在数据预处理、模型训练和实时应用等关键环节,存储性能直接影响到AI模型的训练速度和最终的业务效果。
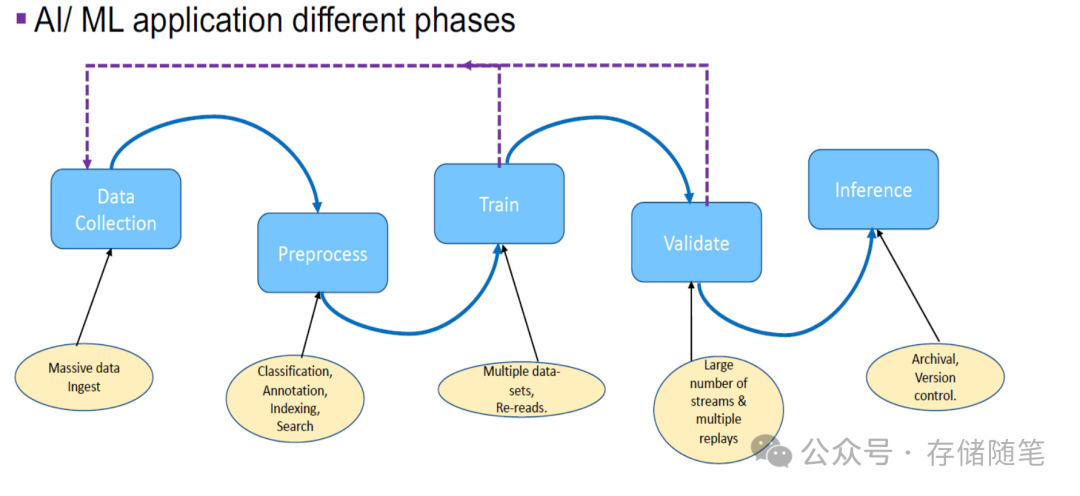
在整个AI生命周期中,存储扮演着至关重要的角色,其重要性体现在以下几个关键环节:
-
数据准备阶段:在AI应用的起始阶段,数据是基础。AI大模型的训练需要处理极大规模的原始数据,这些数据来自多元化的渠道,要求存储系统不仅要有大容量,还要能低成本、高效率地进行数据存储。在数据采集阶段,企业需要一个既能应对TB乃至PB级数据量,又能支持灵活扩展的存储解决方案,以适应数据的持续增长。存储系统需要能够高效地存储和管理海量的原始数据,并支持数据的清洗、标注和预处理工作。
-
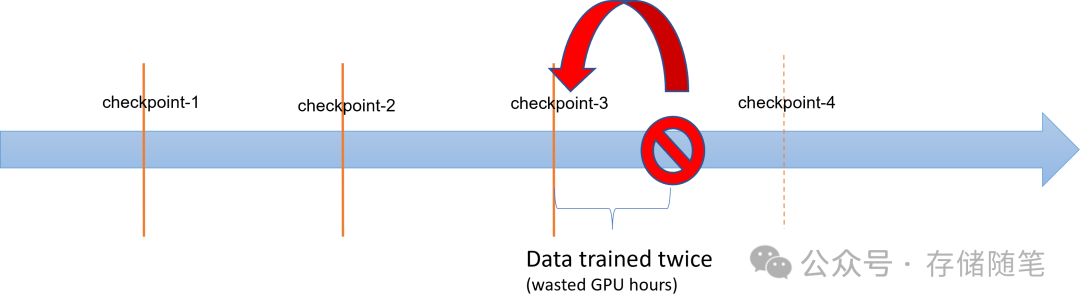
模型训练:AI模型训练过程中,需要频繁读取和写入大量数据。特别是对于深度学习模型,其训练往往涉及数百万甚至数十亿次的矩阵运算,为了充分利用昂贵的GPU资源,存储系统必须能迅速提供训练所需的数据,保证GPU始终忙碌于计算而非等待数据加载。此外,训练过程中周期性保存模型状态(检查点checkpoint),以保护训练投入。存储系统需要支持快速写入和读取这些检查点,减少训练中断时的恢复时间,同时也允许从特定点继续训练以实现更优模型。
-
模型调优与验证:在模型优化阶段,频繁的模型调整和验证同样需要快速的存储访问。存储系统应当支持快速读取不同的模型版本,以进行比较和评估,这要求存储系统具备良好的并发访问能力和低延迟特性。
-
模型部署与推理:模型训练完成后,需要部署到生产环境进行推理服务。在这一阶段,存储系统需要为模型文件和推理所需的数据提供快速可靠的访问,以确保服务的实时性。此外,对于在线服务,存储系统还需要支持高并发访问,满足大规模用户请求的快速响应。
-
数据生命周期管理:AI应用会产生大量数据,包括训练数据、模型文件、日志等。有效的存储管理策略能够帮助组织优化存储资源,如通过分层存储策略,将频繁访问的热数据存储在高性能的闪存上,而将较少访问的冷数据迁移到成本更低的硬盘或云存储中。同时,合理的数据备份和归档策略可以保护数据免受意外丢失,确保业务连续性。
存储不仅是AI生命周期中的基础架构组件,更是决定AI项目成功与否的关键因素之一。随着AI应用的深入发展,对存储系统的需求也在不断演变,推动着存储技术向更高性能、更大容量、更智能管理的方向发展。