图在内存中存储⽅式有很多种,最经典的包括邻接矩阵、邻接表、逆邻接表和⼗字链表。

1.图的存储
1.1邻接矩阵
图的邻接矩阵是⽤两个数组来表示,⼀个⼀维数组存储图中的顶点信息,⼀个⼆维数组(我们将这 个数组称之为邻接矩阵)存储图中的边的信息。
1.1.1⽆向图邻接矩阵
我们可以设置两个数组,顶点数组为vertex4={V0,V1,V2,V3},边数组arc4 4为对称矩阵(0表示 不存在顶点间的边, 1表示顶点间存在边)。
对称矩阵
所谓对称矩阵就是n阶矩阵的元素满⾜ai j = aj i (0<=i,j<=n)。即从矩阵的左上⻆到右下⻆的主 对⻆线为轴,右上⻆的元与左下⻆相对应的元全都是相等的。

1.1.2有向图邻接矩阵
⽆向图的边构成了⼀个对称矩阵,貌似浪费了⼀半的空间,那如果是有向图来存放,会不会把资源 都利⽤得很好呢?

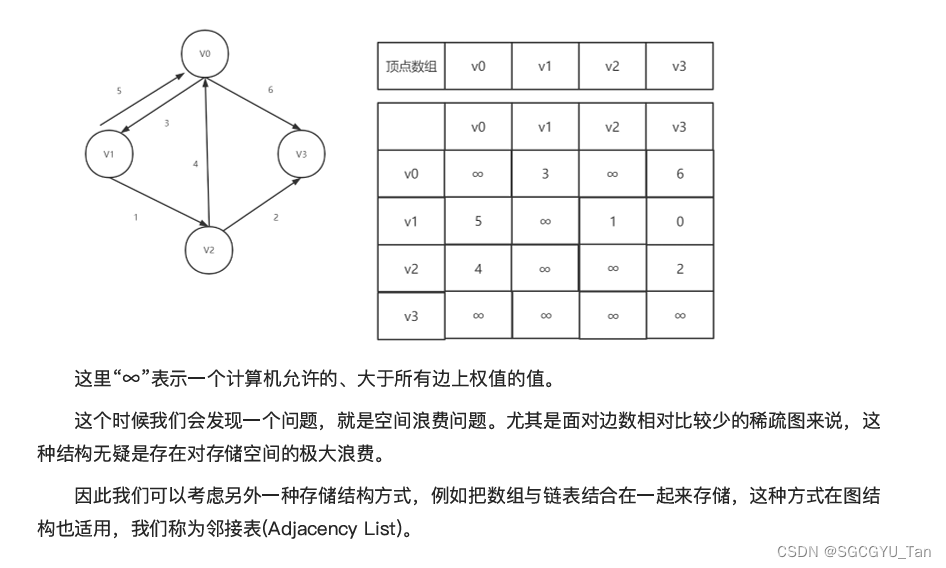
1.1.3带权图(网)的邻接矩阵
带权图中的每⼀条边上带有权值,邻接矩阵中的值则为权值,当两个顶点之间没有弧时,则⽤⽆穷 ⼤表示。
1.1.4优缺点

1.2邻接表
邻接表的处理⽅法是这样:
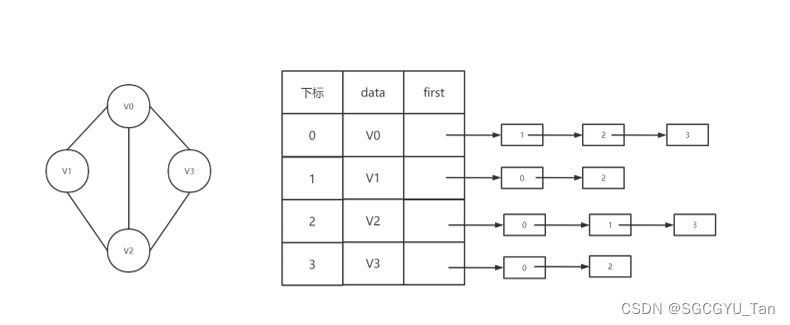
图中顶点⽤⼀个⼀维数组存储,当然,顶点也可以⽤单链表来存储,不过数组可以较容易地读取顶 点信息,更加⽅便。
图中每个顶点Vi的所有邻接点构成⼀个线性表,由于邻接点的个数不确定,所以我们选择⽤单链表 来存储。

1.2.1⽆向图邻接表
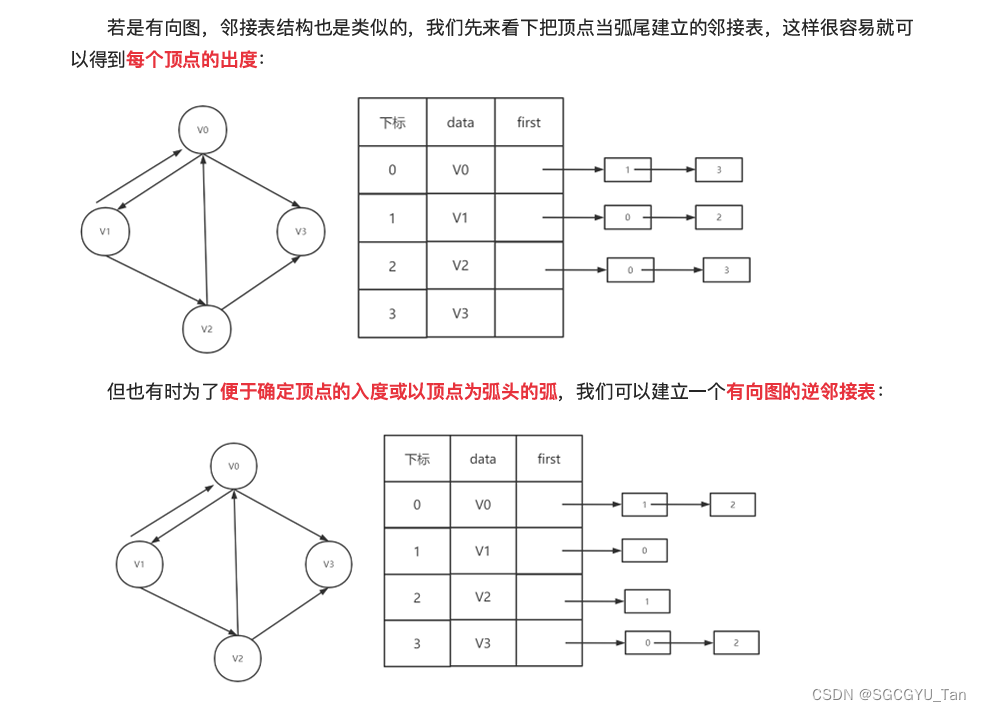
1.2.2有向图邻接表
1.2.3带权⽹络的邻接表

1.2.4优缺点

1.2.5代码展示
cpp
#include <iostream>
using namespace std;
/*
邻接表:一堆顶点结构体数组存点,用链表存边(结构体数组)
无向图两个点之间互相挂
有向图只挂出度的点,出度就统计该点链表长度,入度得遍历所有链表计算指向该点的个数
如果只想找入度,就建立逆邻接表(入度挂在链表后面)看情况建立两种邻接链表
缺点:只能单独方便找出度(入度)
如果邻接表和逆邻接表结合->十字链表(有向图)
整合邻接表->多重邻接表(无向图)
*/
typedef struct EdgeNode
{
char adj;//邻接点 可以是序号,可以就是本身数据,这里以数据为例
struct EdgeNode *next;
int w;//权值 ->图的权值是在边上
}Edge;
//顶点结构体数组
typedef struct VertexNode
{
char data;
struct EdgeNode * first;
}Vertex;
int n, m;//n是点的个数,m是无向边的个数
Vertex v[105];
int find(char x)
{
for (int i = 1; i <= n; i++)
{
if (v[i].data == x)
{
return i;
}
}
}
int main()
{
cin >> n >> m;
//初始化每个点的数据和下标
for (int i = 1; i <= n; i++)
{
cin >> v[i].data;
v[i].first = NULL;
}
char x, y;
int xi, yi;//x,y的下标
int w;
for (int i = 1; i <= m; i++)
{
cin >> x >> y >> w;//此示例为无向图,表示x和y有边
Edge * s = new EdgeNode;
s->adj = y;
s->w = w;
xi = find(x);
s->next = v[xi].first;
v[xi].first = s;
Edge * s = new EdgeNode;
s->adj = x;
s->w = w;
yi = find(y);
s->next = v[yi].first;
v[yi].first = s;
}
system("pause");
return 0;
}1.2.6邻接表与邻接矩阵的异同

1.3⼗字链表表示
⼗字链表的好处就是因为把邻接表和逆邻接表整合在了⼀起,这样既容易找到以Vi为尾的弧,也容 易找到以Vi为头的弧,因⽽容易求得顶点的出度和⼊度。
⼗字链表除了结构复杂⼀点外,其实创建图算法的时间复杂度是和邻接表相同的,因此,在有向图 的应⽤中,⼗字链表也是⾮常好的数据结构模型。
这个时候,还有⼀个问题,如果使⽤邻接表存储结构,但是对边的操作⽐较频繁,怎么办?
如果我们在⽆向图的应⽤中,关注的重点是顶点的话,那么邻接表是不错的选择,但如果我们更关注的是边的操作,⽐如对已经访问过的边做标记,或者删除某⼀条边等操作,邻接表的确显得不那么⽅便了。
代码展示:
cpp
#include <iostream>
using namespace std;
/*
如果邻接表和逆邻接表结合->十字链表(有向图)
整合邻接表->多重邻接表(无向图)
*/
//十字链表的结点结构
typedef struct ArcBox
{
int tailvex;//弧尾
int headvex;//弧头--->这里以下标为例
struct ArcBox * tnext;//相同弧尾对应的链表的指针
struct ArcBox * hnext;//相同弧头对应的链表的指针
int w;
}Edge;
//图顶点的结构体数组
typedef struct
{
int data;
Edge * firstin;
Edge * firstout;
}Vertex;
Vertex v[105];
int n, m;
void vertex_init()
{
cin >> n >> m;
for (int i = 1; i <= n; i++)
{
cin >> v[i].data;//数据是int类型的
v[i].firstin = v[i].firstout = NULL;
}
}
int main()
{
vertex_init();
int x, y, w;
for (int i = 1; i <= m; i++)//输入边的关系(这边为了方便,不查找直接用的下标)
{
cin >> x >> y >> w;// x(弧尾)--->y(弧头)
Edge * s = new ArcBox;
s->w = w;
s->tailvex = x;
s->headvex = y;
s->tnext = v[x].firstout;
v[x].firstout = s;//插入到弧尾的 出边链表中(该顶点的出度链表)
s->hnext = v[y].firstin;
v[y].firstin = s;//插入到弧头的 入边链表中(该顶点的入度链表)
}
system("pause");
return 0;
}1.4邻接多重表
邻接表对边的操作显然很不⽅便,因此,我们可以仿照⼗字链表的⽅式,对边表结构进⾏改装(将边的关系变为结点),重 新定义的边表结构如下:
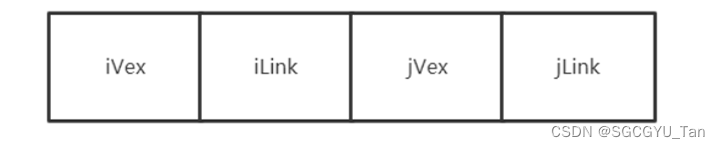
其中iVex和jVex是与某条边依附的两个顶点在顶点表中的下标。 iLink指向依附顶点iVex的下⼀条 边, jLink指向依附顶点jVex的下⼀条边。

代码展示:
cpp
#include <iostream>
using namespace std;
/*
整合邻接表->多重邻接表(无向图)
*/
//多重邻接表的结点结构
typedef struct ArcBox
{
int vi, vj;//结点下标
struct ArcBox *inext;
struct ArcBox *jnext;
int w;
}Edge;
//图顶点的结构体数组
typedef struct
{
int data;
Edge * first;
}Vertex;
Vertex v[105];
int n, m;
void vertex_init()
{
cin >> n >> m;
for (int i = 1; i <= n; i++)
{
cin >> v[i].data;//数据是int类型的
v[i].first= NULL;
}
}
int main()
{
vertex_init();
int x, y, w;
for (int i = 1; i <= m; i++)//输入边的关系(这边为了方便,不查找直接用的下标)
{
cin >> x >> y >> w;
Edge * s = new ArcBox;
s->w = w;
s->vi = x;
s->vj = y;
//一个结点插入到两个链表里面 --》普通的邻接表就是开辟两个结点,每个first后面都连着对应的顶点下标(值本身)
s->inext = v[x].first;
v[x].first = s;
s->jnext = v[y].first;
v[y].first = s;
}
system("pause");
return 0;
}1.5边集数组
边集数组是由两个⼀维数组构成,⼀个是存储顶点的信息,另⼀个是存储边的信息,这个边数组每 个数据元素由⼀条边的起点下标(begin)、终点下标(end)和权(weight)组成。
2.图的遍历
**遍历定义:**从图中某顶点出发访遍图中所有顶点,且每个顶 点仅被访问一次,此过程称为图的遍历。
图的遍历算法是求解图的连通性问题、拓扑排序和求 关键路径等算法的基础
**遍历实质:**找每个顶点的邻接点的过程。
**图的特点:**图中可能存在回路,且图的任一顶点都可能与其它顶点相通,在访问完某个顶点之后可能会沿着某些边又回到了曾经访问过的顶点。
怎样避免重复访问?
解决思路:设置辅助数组visitedn,用来标记每个被访问过的顶 点。初始状态为0,i 被访问,改visitedi为1,防止被多次访问

2.1深度优先遍历(DFS)
2.1.1方法总结
1、⾸先选定⼀个未被访问过的顶点V作为起始顶点(或者访问指定的起始顶点V),并将其 标记为已访问过;
2、然后搜索与顶点V邻接的所有顶点,判断这些顶点是否被访问过,如果有未被访问过的顶 点W;再选取与顶点W邻接的未被访问过的⼀个顶点并进⾏访问,依次重复进⾏。当⼀个顶点的所有的 邻接顶点都被访问过时,则依次回退到最近被访问的顶点。若该顶点还有其他邻接顶点未被访问,则从 这些未被访问的顶点中取出⼀个并重复上述过程,直到与起始顶点V相邻接的所有顶点都被访问过为⽌。
3、若此时图中依然有顶点未被访问,则再选取其中⼀个顶点作为起始顶点并进⾏遍历,转 ②。反之,则遍历结束。



2.1.2代码展示(邻接矩阵例子)
cpp
#include <iostream>
using namespace std;
//邻接矩阵存图:无权无相图
char v[105];
int g[105][105];
int n, m;
int vis[105];//标记是否被访问 v[x]=1 -->被访问过 想v[x]=0 -->未被访问
void vertex_build()
{
for (int i = 0; i < n; i++)
{
cin >> v[i];
}
//为了方便直接存下标了(如果存入字符多一个find找下标的函数)
int x, y;
for (int i = 1; i <= m; i++)
{
cin >> x >> y;
g[x][y] = g[y][x] = 1;//无向图传双向边
}
}
void DFS(int x)
{
//访问x
cout << v[x] << " ";
vis[x] = 1;//标记x,说明x被访问
for (int i = 0; i < n; i++)
{
if (g[x][i] == 1 && vis[i] == 0)
{//v[i]没有被访问
DFS(i);
}
}
}
int main()
{
cin >> n >> m;
vertex_build();
for (int i = 0; i < n; i++)//防止非连通图
{
if (vis[i] == 0)
{//说明i结点没有被访问,以i为起点进行DFS
DFS(i);
}
}
system("pause");
return 0;
}
/*
9
15
ABCDEFGHI
0 1
0 5
1 6
5 6
2 1
1 8
2 8
6 7
2 3
3 8
3 7
3 4
4 7
4 5
3 6
*/2.1.3算法效率分析

2.2广度优先遍历(BFS)
2.2.1算法思想
从图中某个顶点v出发,访问v,并置visitedv的值为 true,然后将v进队。
只要队列不空,则重复下述过程
1.队头顶点u出队。
2.依次检查u的所有邻接点w,如果visitedw的值为false,则访问w,并置visitedw的值为true,然后将w进队。
2.2.2代码展示
cpp
#include <iostream>
using namespace std;
//邻接表存图:无权无相图
//BFS 可以求无权图中 起点到其他点的最短路径(层级就是路程)
int n, m;
//链表的结点结构
typedef struct EdgeNode
{
int adj;//邻接点 可以是序号,可以就是本身数据,这里以下标为例
struct EdgeNode* next;
}Edgenode;
//图的结点结构
struct veNode
{
char data;
EdgeNode* first;
};
veNode v[105];
int flag[105];//1为已入过队(为了标记这个结点已经被访问过)
int dist[105];//起点到i的距离
//-----队列
//循环队列
typedef struct
{
int d[106];//结点s的数组
int f, r;
}SQueue;
void queue_init(SQueue* q)
{
q->f = q->r = 0;
}
void push_queue(SQueue* q, int x)
{
if ((q->r + 1) % 106 == q->f)
{
cout << "队满" << endl;
return;
}
q->d[q->r] = x;//初始的时候q->r是0,中括号里面的内容只是下标
q->r = (q->r + 1) % 106;
}
int isEmpty(SQueue* q)
{
if (q->f == q->r)
{
return 1;
}
else
{
return 0;
}
}
int pop_queue(SQueue* q)
{
if (isEmpty(q) == 1)
{
if ((q->r + 1) % 106 == q->f)
{
cout << "队空" << endl;
return -1;
}
}
int e = q->d[q->f];
q->f = (q->f + 1) % 106;
return e;
}
//-----
void vertex_build()
{
for (int i = 0; i < n; i++)
{
cin >> v[i].data;
v[i].first = NULL;
}
//为了方便直接存下标了(如果存入字符多一个find找下标的函数)
int x, y;
for (int i = 1; i <= m; i++)
{
cin >> x >> y;
EdgeNode* s = new EdgeNode;
s->adj = y;
s->next = v[x].first;
v[x].first = s;
EdgeNode* s1 = new EdgeNode;
s1->adj = x;
s1->next = v[y].first;
v[y].first = s1;
}
}
void BFS(int x)//x是起点下标起点
{
int e;//队首元素
SQueue q;
EdgeNode* p = NULL;
queue_init(&q);
//x(下标)入队
push_queue(&q, x);
flag[x] = 1;
while (isEmpty(&q) == 0)
{
e = pop_queue(&q);
cout << v[e].data << " ";
p = v[e].first;//队首元素pop出来后,找队首元素的first,看看这个结点后面有没有链表
while (p != NULL)
{
if (flag[p->adj] == 0)
{
push_queue(&q, p->adj);
dist[p->adj] = dist[e] + 1;
flag[p->adj] = 1;
}
p = p->next;
}
}
}
int main()
{
cin >> n >> m;
vertex_build();
for (int i = 0; i < n; i++)//防止非连通图
{
if (flag[i] == 0)
{
BFS(i);//将非连通图的起点下标传入
}
}
cout << endl;
for (int i = 0; i < n; i++)
{
cout << v[i].data << " " << dist[i] << endl;
}
system("pause");
return 0;
}
/*
9
15
ABCDEFGHI
0 1
0 5
1 6
5 6
2 1
1 8
2 8
6 7
2 3
3 8
3 7
3 4
4 7
4 5
3 6
*/2.2.3算法效率分析

2.3总结
图的遍历⽅式包括深度优先搜索(DFS)和⼴度优先搜索(BFS),其中 DFS 使⽤递归或栈进⾏ 实现,⽽ BFS 则采⽤队列进⾏实现。对⽐树的四种遍历⽅式,前序遍历、中序遍历和后序遍历均类似于 DFS,⽽层序遍历类似于 BFS,前中后序也均可采⽤栈的⽅式进⾏实现,层序遍历可以采⽤队列的⽅式 进⾏实现。
这样看来,知识的融会贯通多么重要,总体⽽⾔,掌握下⾯的两条链,你便可以解决好多问题。
DFS → 前中后序 → 栈 → 线性表
BFS → 层序遍历 → 队列 → 链表

