文章目录
- 2020
-
- [UAV Maneuvering Target Tracking in Uncertain Environments Based on Deep Reinforcement Learning and Meta-Learning](#UAV Maneuvering Target Tracking in Uncertain Environments Based on Deep Reinforcement Learning and Meta-Learning)
- [UAV Target Tracking in Urban Environments Using Deep Reinforcement Learning](#UAV Target Tracking in Urban Environments Using Deep Reinforcement Learning)
- 2021
-
- [Research on Vehicle Dispatch Problem Based on Kuhn-Munkres and Reinforcement Learning Algorithm](#Research on Vehicle Dispatch Problem Based on Kuhn-Munkres and Reinforcement Learning Algorithm)
- [Multi-Agent Reinforcement Learning Aided Intelligent UAV Swarm for Target Tracking](#Multi-Agent Reinforcement Learning Aided Intelligent UAV Swarm for Target Tracking)
- [Active Learning for Deep Visual Tracking](#Active Learning for Deep Visual Tracking)
- 2022
-
- [Remote Sensing Object Tracking With Deep Reinforcement Learning Under Occlusion](#Remote Sensing Object Tracking With Deep Reinforcement Learning Under Occlusion)
- 2023
-
- [Deep Reinforcement Learning for Vision-Based Navigation of UAVs in Avoiding Stationary and Mobile Obstacles](#Deep Reinforcement Learning for Vision-Based Navigation of UAVs in Avoiding Stationary and Mobile Obstacles)
- [SRL-TR2: A Safe Reinforcement Learning Based TRajectory TRacker Framework](#SRL-TR2: A Safe Reinforcement Learning Based TRajectory TRacker Framework)
- [Adaptive chaotic sampling particle filter to handle occlusion and fast motion in visual object tracking](#Adaptive chaotic sampling particle filter to handle occlusion and fast motion in visual object tracking)
2020
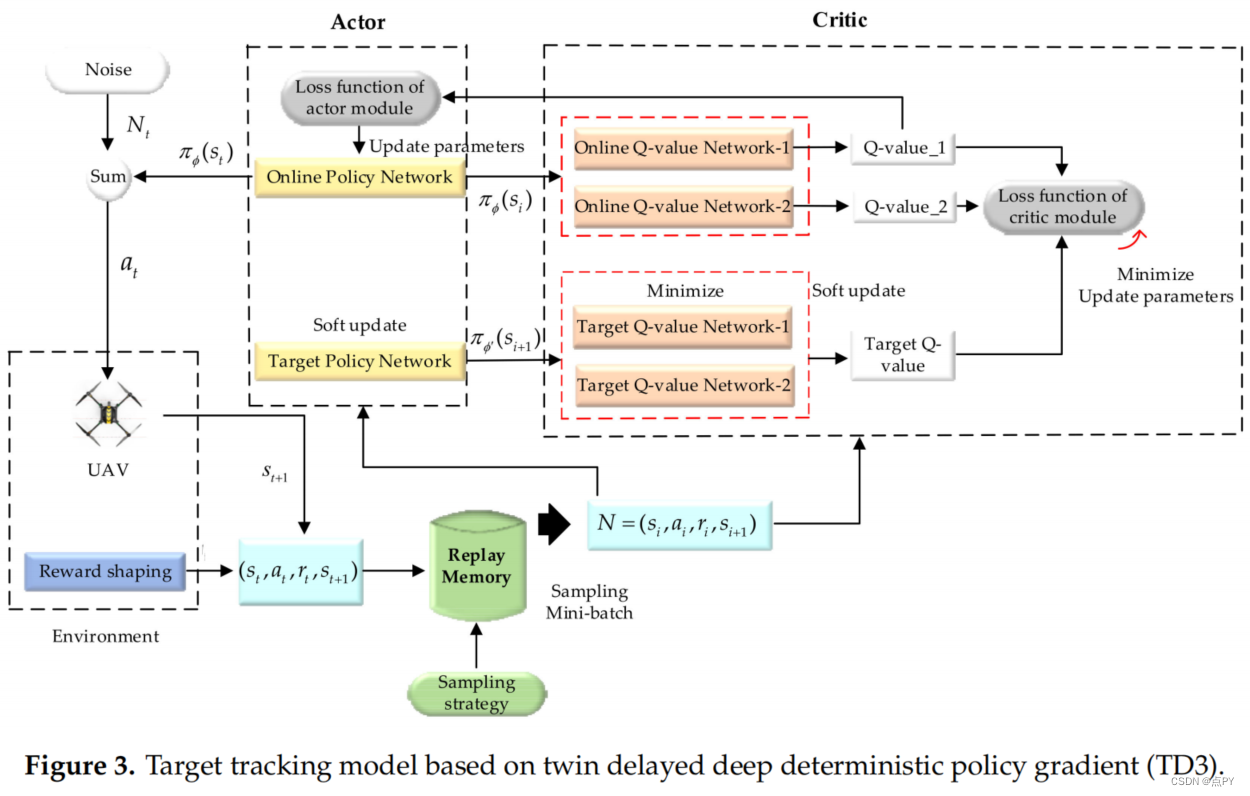
UAV Maneuvering Target Tracking in Uncertain Environments Based on Deep Reinforcement Learning and Meta-Learning
摘要: 本文结合深度强化学习(DRL)与元学习,提出了一种新颖的方法,名为元双延迟深度确定性政策梯度(Meta-TD3),实现无人机(UAV)的控制,允许无人机快速跟踪目标环境的目标是不确定的。这种方法可应用于各种情况,如野生动物保护、紧急援助和遥感。我们考虑一个多任务经验重放缓冲区为DRL算法的多任务学习提供数据,并结合元学习开发了一种多任务强化学习更新方法,以确保强化学习的泛化能力。与现有的深度确定性策略梯度(DDPG)和双延迟深度确定性策略梯度(TD3)算法相比,实验结果表明,Meta-TD3算法在收敛值和收敛速度方面都取得了很大的提高。在无人机目标跟踪问题中,Meta-TD3只需要几个步骤来训练,使无人机能够快速适应新的目标运动模式,并保持更好的跟踪效果。
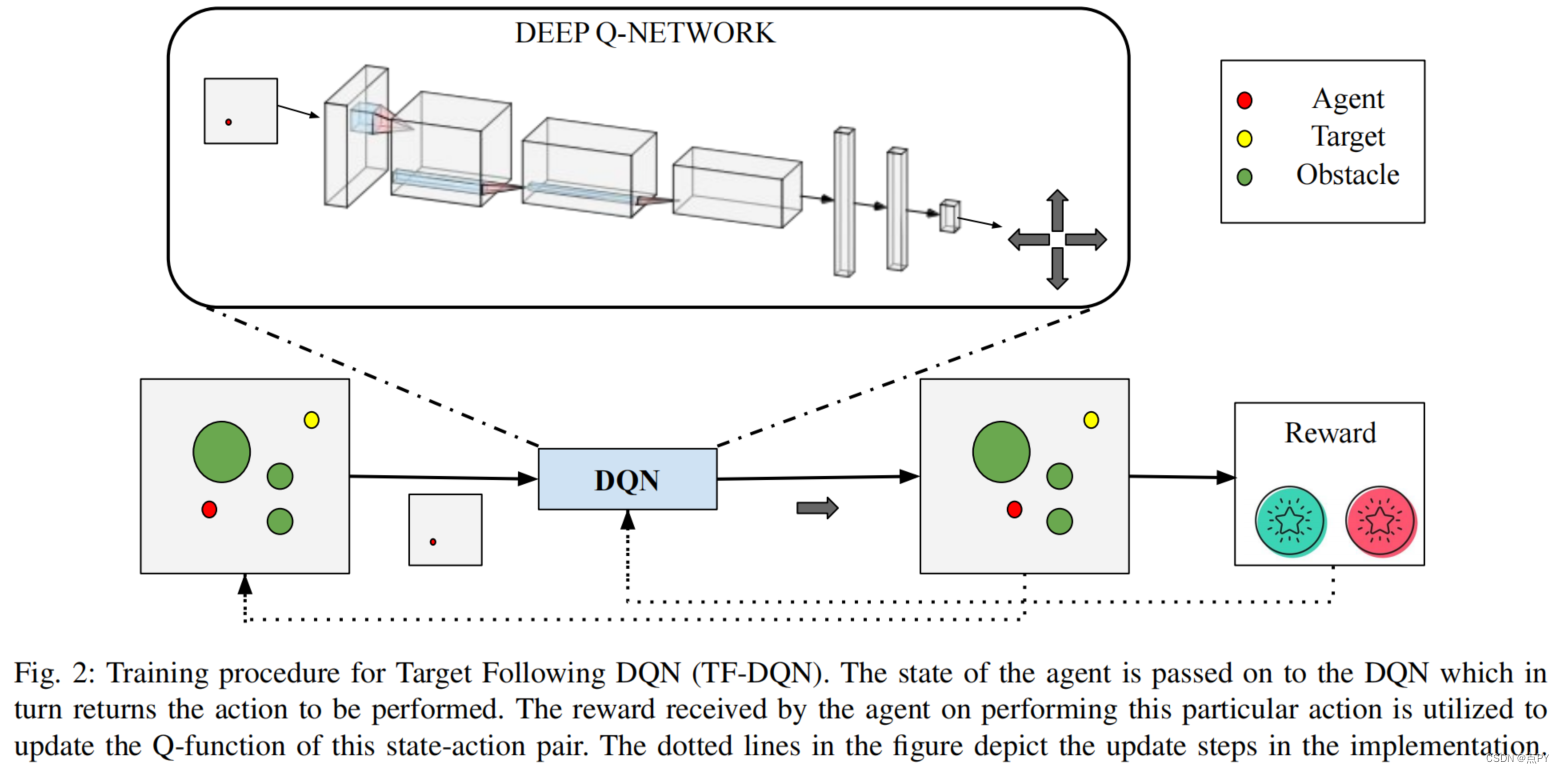
UAV Target Tracking in Urban Environments Using Deep Reinforcement Learning
code: https://github.com/sarthak268/Target-Tracking-Simulator
摘要: 由于视野有限、障碍物能见度障碍、目标运动不确定,无人机在城市环境中进行持续目标跟踪是一项困难的任务。车辆需要在三维空间中进行智能规划,以使目标可见性最大化。在本文中,我们介绍了一种基于深度q网络(TF-DQN)的深度强化学习技术,具有课程训练框架,用于无人机在存在障碍物和目标运动不确定性的情况下持续跟踪目标。通过多次仿真实验,对该算法进行了定性和定量的评价。结果表明,无人机在不同的环境中持续跟踪目标,同时在训练好的环境和看不见的环境中避开障碍物。
2021
Research on Vehicle Dispatch Problem Based on Kuhn-Munkres and Reinforcement Learning Algorithm
摘要: 随着人工智能和5G通信技术的发展,自动驾驶汽车的可实现性越来越大。城市交通汽车提供出租车服务,有效降低了劳动力成本,实现了智能交通系统。结合5G技术的车辆系统可以快速获取交通信息,为车辆调度提供了决策依据。因此,有必要开发一种有效的方法来分配和分配这些车辆,以最大化系统的潜在收入。本文基于2016年纽约市绿色出租车数据的出行数据进行了车辆调度研究,并提出了两种调度方法。首先,我们将调度问题作为一个最大权值匹配问题。然后,利用库恩和Munkres(KM)算法,提出了一种以减少乘客等候时间为目标的基于距离调度方法。最后,我们用马尔可夫决策过程(MDP)制定了车辆调度决策,并引入了一种基于强化学习(RL)的调度方法,该方法结合了RL算法和KM算法来解决调度问题,使潜水员的长期收入最大化。实验将KM算法与全置换算法进行了比较,证明了KM算法的有效性。介绍了基于远程的调度方法和基于rl的调度方法在小型调度和大规模调度中的性能。首先,我们将调度问题作为一个最大权值匹配问题。然后,利用库恩和Munkres(KM)算法,提出了一种以减少乘客等候时间为目标的基于距离调度方法。最后,我们用马尔可夫决策过程(MDP)制定了车辆调度决策,并引入了一种基于强化学习(RL)的调度方法,该方法结合了RL算法和KM算法来解决调度问题,使潜水员的长期收入最大化。实验将KM算法与全置换算法进行了比较,证明了KM算法的有效性。介绍了基于远程的调度方法和基于rl的调度方法在小型调度和大规模调度中的性能。

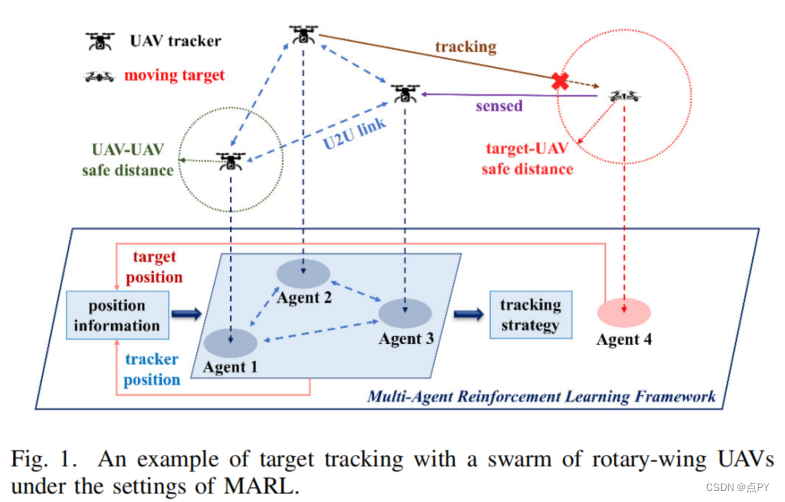
Multi-Agent Reinforcement Learning Aided Intelligent UAV Swarm for Target Tracking
摘要: 过去几年,无人机(uav)被广泛应用于目标跟踪的区域监测和打击。大多数现有的目标跟踪方法依赖于由所装备的相机获得的目标运动帧,或理想地假设一个预先设定的目标轨迹。但在实际应用中,无人机不能事先完全知道目标的真实轨迹,目标也可以根据环境智能地调整其飞行策略。此外,单架无人机有限的飞行性能以及信息捕获和处理能力,难以满足高跟踪成功率的要求。针对上述问题,本文提出了一种端到端协同多智能体强化学习(MARL)方案,该方案使无人机能够根据目标过去和当前的状态,做出协同目标跟踪的智能飞行决策。为了降低功耗,延长无人机跟踪系统的使用寿命,介绍了推进功耗模型和节能策略。此外,为了进一步提高检测的覆盖范围,在跟踪算法中引入了空间信息熵。仿真结果表明,我们提出的算法在平均事件奖励方面优于深度强化学习基线,同时在跟踪成功率、省电效率和检测覆盖率方面也具有较高的性能。
Active Learning for Deep Visual Tracking
摘要: 卷积神经网络(CNNs)近年来已成功地应用于单目标跟踪任务。一般来说,训练一个深度CNN模型需要大量标记的训练样本,这些样本的数量和质量直接影响训练模型的表征能力。然而,这种方法在实践中是限制性的,因为手动标记如此大量的训练样本是耗时的和非常昂贵的。在本文中,我们提出了一种深度视觉跟踪的主动学习方法,它选择和标注未标记的样本来训练深度cnn模型。在主动学习的指导下,基于训练好的深度cnn模型的跟踪器可以在降低标记成本的同时实现具有竞争力的跟踪性能。更具体地说,为了确保所选样本的多样性,我们提出了一种基于多帧协作的主动学习方法来选择那些应该标注和需要标注的训练样本。同时,考虑到所选样本的代表性,我们采用基于平均最近邻距离的最近邻鉴别方法来筛选孤立的样本和低质量的样本。因此,基于我们的方法选择的训练样本子集只需要一个给定的预算来保持整个样本集的多样性和代表性。此外,我们采用了一个Tversky损失来改进我们的跟踪器的边界盒估计,这可以确保跟踪器实现更准确的目标状态。大量的实验结果证实,我们的基于主动学习的跟踪器(ALT)在7个最具挑战性的评估基准上,与最先进的跟踪器相比,实现了具有竞争力的跟踪精度和速度。
论文的贡献
- 我们提出了一种新的主动学习方法来训练样本选择,以训练跟踪器中的深度cnn模型。该方法将在给定的预算下选择最多样化和最具代表性的训练样本,在大大降低标记这些训练样本的同时,确保可接受的跟踪性能的成本。
- 考虑到视频序列中移动目标的时间关系,我们提出了使用多帧合作策略的主动学习方法来选择这些训练样本,以确保所选样本的多样性。
- 此外,我们采用基于平均最近邻距离的最近邻识别方法对孤立样本进行筛选,保证所选训练样本的代表性,有效保证训练后的深度cnn模型的鲁棒性。
- 此外,我们采用Tversky损失来改进所提出的跟踪器的边界盒估计策略,使我们的ALT跟踪器能够获得更准确的目标状态。

2022
Remote Sensing Object Tracking With Deep Reinforcement Learning Under Occlusion
摘要: 目标跟踪是遥感领域空间地球观测的重要研究方向。虽然现有的基于相关滤波器和基于深度学习(DL)的目标跟踪算法取得了很大的成功,但对于目标遮挡问题仍然不能令人满意。由于背景的复杂变化而造成的遮挡和跟踪镜头的偏差,导致物体信息丢失,从而导致检测的遗漏。传统上,被遮挡下的目标跟踪方法大多采用复杂的网络模型,对被遮挡对象进行重新检测。为了解决这个问题,我们提出了一种新的目标跟踪方法。首先,建立了一个基于深度强化学习(DRL)的动作决策-遮挡处理网络(AD-OHNet),以实现遮挡下目标跟踪的低计算复杂度。其次,采用时空背景、物体外观模型和运动矢量来提供遮挡信息,从而驱动完全遮挡下强化学习的动作,有助于在保持速度的同时提高跟踪的准确性。最后,在吉林-1商业遥感卫星的波哥大、香港和圣地亚哥的三个遥感视频数据集上,对提出的AD-OHNet进行了评估。这些视频数据集都有低空间分辨率、背景杂波和小物体等共同问题。在三个视频数据集上的实验结果验证了该跟踪器的有效性和有效性。
论文的贡献:
- 首先,采用DRL的框架,在不附加网络结构的情况下进行目标跟踪,以提高算法在遮挡条件下的速度。DRL中的状态和动作参数可以与目标跟踪中的连续帧信息相关联。据我们所知,这是第一次使用DRL的想法来解决目标跟踪中的遮挡问题。
- 其次,我们提出了一种新的方法,通过在跟踪任务中使用目标遮挡信息来驱动动作,这与传统的逐次跟踪检测方法不同。时间和空间上下文之间的连续帧遥感序列,对象外观模型学习网络,和运动向量从动作参数在强化学习采用提供遮挡信息,显著提高了对象跟踪算法的鲁棒性和精度。
- 其次,我们提出了一种新的方法,通过在跟踪任务中使用目标遮挡信息来驱动动作,这与传统的逐次跟踪检测方法不同。时间和空间上下文之间的连续帧遥感序列,对象外观模型学习网络,和运动向量从动作参数在强化学习采用提供遮挡信息,显著提高了对象跟踪算法的鲁棒性和精度。

2023
Deep Reinforcement Learning for Vision-Based Navigation of UAVs in Avoiding Stationary and Mobile Obstacles
摘要: 无人机(uav),也被称为无人机,近年来有了很大的进步。无人机的使用方式有很多种,包括交通运输、摄影、气候监测和救灾。其原因是它们在所有操作中都具有很高的效率和安全性。虽然无人机的设计力求完美,但它还没有完美无缺。在探测和预防碰撞方面,无人机仍然面临着许多挑战。在此背景下,本文描述了一种方法,开发无人机系统自主操作,不需要人工干预。本研究应用强化学习算法训练无人机,在仅基于图像数据的离散和连续的动作空间中自动避免障碍。本研究的新颖之处在于,利用不同的强化学习技术,对无人机的障碍物探测和躲避的优势、局限性和未来的研究方向进行了综合评估。本研究比较了三种不同的强化学习策略,即深度q网络(DQN)、近端策略优化(PPO)和软行动者评论家(SAC),它们可以帮助避免障碍,包括静止和移动;然而,这些策略在无人机上更为成功。该实验是在AirSim提供的虚拟环境中进行的。使用虚幻引擎4,创建了各种训练和测试场景,以理解和分析无人机的RL算法的行为。根据训练结果可知,SAC的性能优于其他两种算法。PPO是所有算法中最不成功的,这表明策略上的算法在具有动态参与者的广泛三维环境中是无效的。DQN和SAC,两种非策略算法,产生了令人鼓舞的结果。然而,由于其有限的离散作用空间,DQN在狭窄的路径和扭曲方面可能不如SAC有利。关于进一步的发现,当涉及到自主无人机时,DQN和SAC等非策略算法比PPO等非策略算法表现得更有效。这些发现可能对未来开发更安全、更高效的无人机具有实际意义。
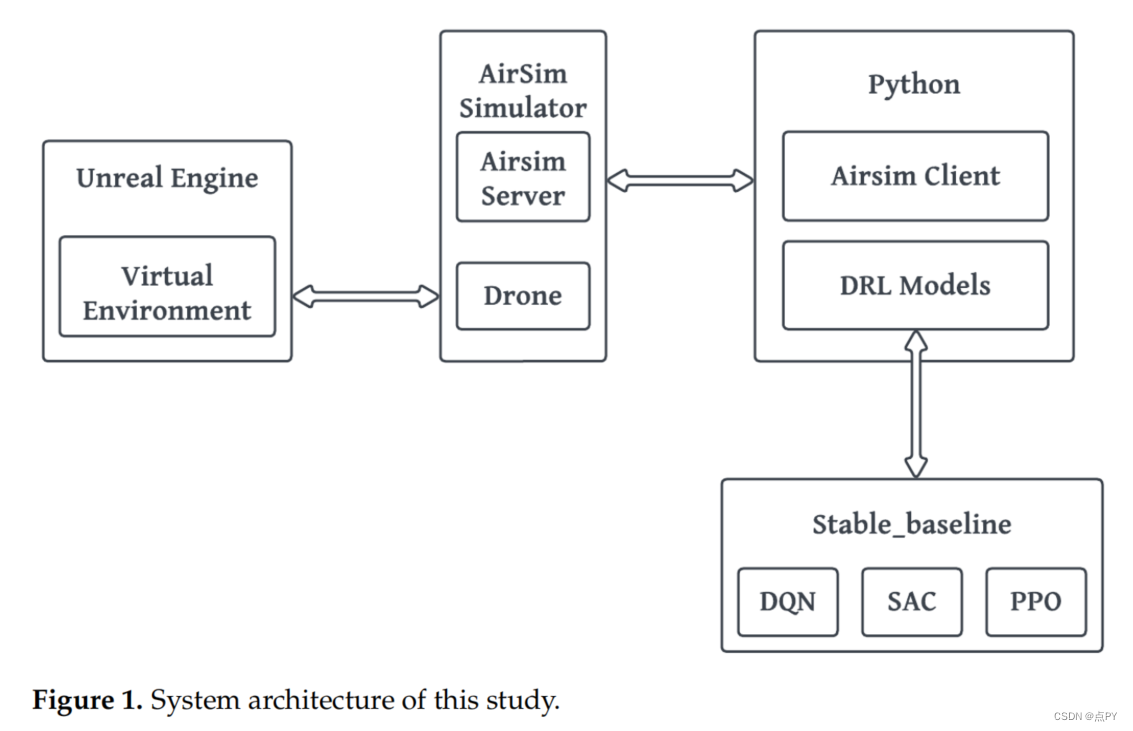
SRL-TR2: A Safe Reinforcement Learning Based TRajectory TRacker Framework
摘要: 本文旨在解决一种基于强化学习方法的自动驾驶车辆的轨迹跟踪控制问题。现有的强化学习方法在现实世界中在安全关键任务上的成功应用有限,主要是由于两个挑战: 1)模拟到真实的转移;2)闭环稳定性和安全问题。在本文中,我们提出了一个演员-评论家风格的框架SRL-TR2,其中基于rl的跟踪跟踪器在安全约束下进行训练,然后部署到全尺寸车辆作为横向控制器。为了提高泛化能力,我们采用了一个轻量级的适配器状态和动作空间对齐(SASA)来建立仿真与现实之间的映射关系。为了解决安全问题,当安全约束不得到满足时,我们利用专家策略来接管控制。因此,我们在培训过程中进行了安全的探索,并提高了政策的稳定性。实验表明,在12 km/h~18 km/h的模拟场景下,在12 km/h~18 km/h的情况下,以平均运行时间小于10ms/步,平均横向误差小于0.1 m完成现场测试。

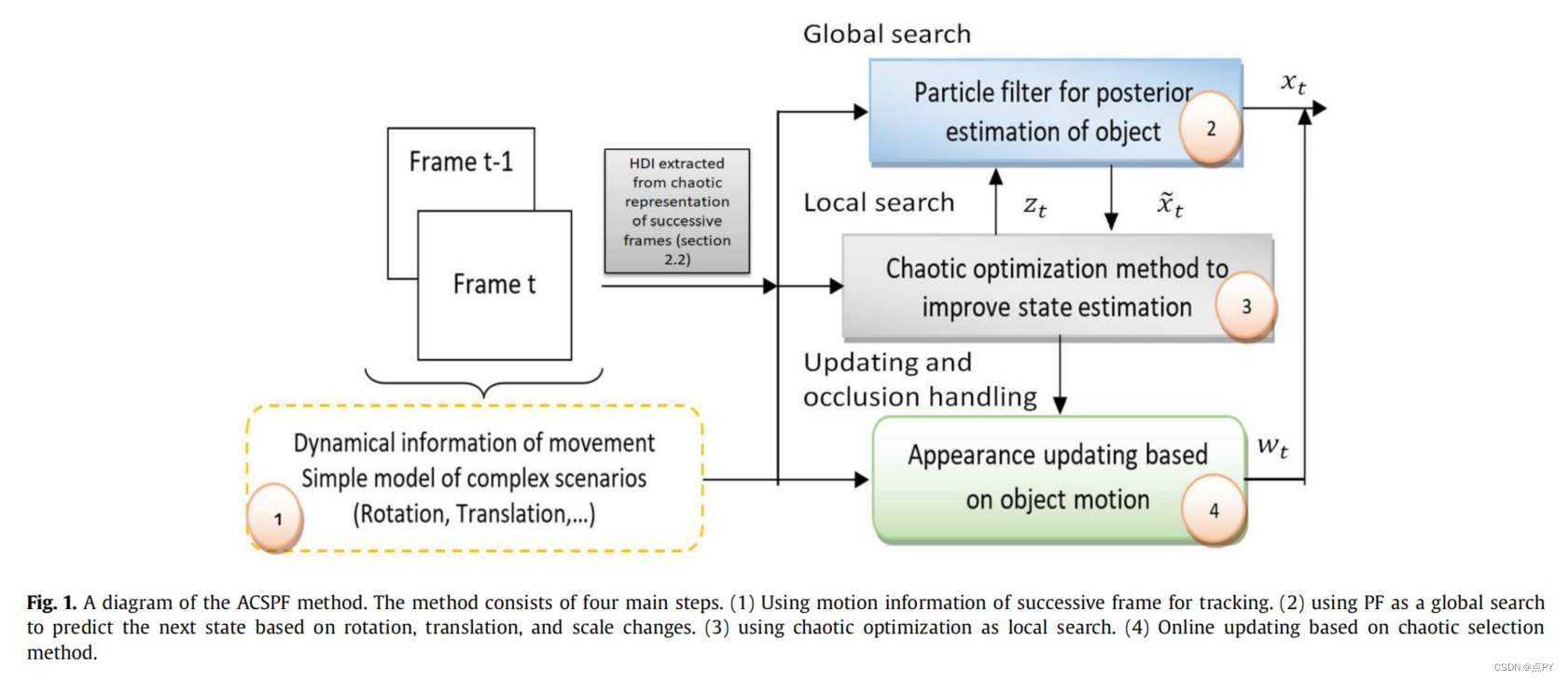
Adaptive chaotic sampling particle filter to handle occlusion and fast motion in visual object tracking
摘要:本文提出了一种新的视觉目标跟踪粒子滤波方法,可以有效地处理遮挡和快速运动。该方法采用混沌局部搜索来模拟不规则运动,与普通的粒子滤波方法相比,该方法需要更少的粒子数量。此外,采用一种新的混沌采样方法将粒子强制施加到具有最大多样性似然函数的特定区域,并引入基于状态空间重建的动态信息直方图来表示连续帧上的运动。最后,提出了一种新的区分遮挡和视野外外观更新的准则。我们提出了数值实验证明,所开发的框架优于其他最先进的方法处理不规则运动和不确定性。根据BOBOT、OTB100、OTB2013和VOT2018的研究结果,与基于深度和强化学习、相关滤波器和暹罗神经网络等方法的传统方法相比,提出的策略更接近真实目标状态,提高了跟踪精度。最后,我们解析地证明了该方法的收敛性。