原生分辨率在前期介绍了多期,相比固定分辨率,原生分辨率在多种任务上尤其是OCR任务上效果显著。那么如何在一些现有的视觉模型(如:SigLIP、AIMv2)上继续训练让多模态视觉语言模型支持原生支持任意分辨率图像输入?下面简单看一下一个多模态继续预训练框架-COMP(Continual Multimodal Pre-training)。
往期关于分辨率相关:
方法架构
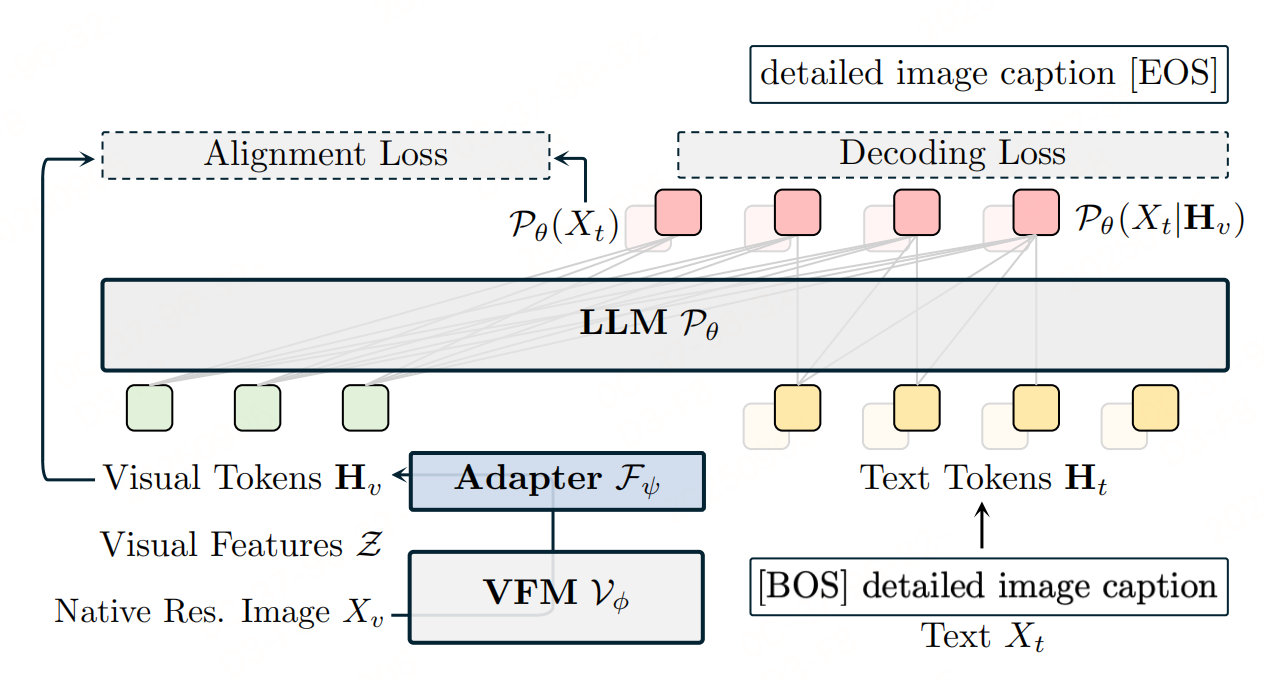
COMP的目标是让现有视觉基础模型(VFMs)原生支持任意分辨率图像输入,并将其视觉表征与大语言模型(LLMs)的语言表征直接对齐。整体流程如上图:原生分辨率图像经VFMs(含C-ROPE)生成视觉特征,文本经LLM生成文本特征,通过双损失函数联合训练,最终输出增强后的VFMs。方法如下:
1 原生分辨率适配
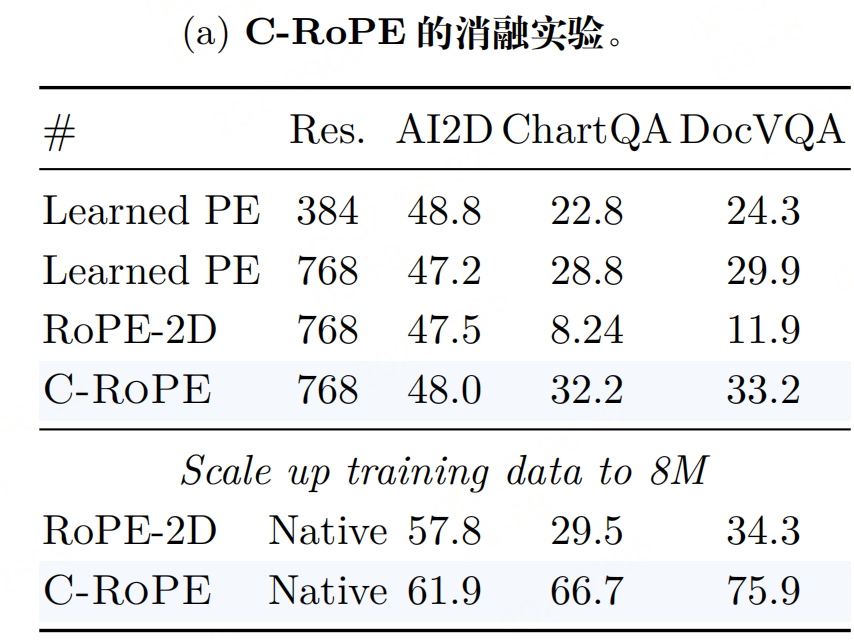
现有VFMs的位置嵌入是为固定分辨率设计的,处理不同尺寸图像时常用"插值调整位置嵌入",但会丢失细节;纯RoPE2D(旋转位置嵌入)虽支持分辨率外推,但数据效率低、训练不稳定。因此C-ROPE的核心是 结合绝对位置嵌入的"稳定性"和相对RoPE2D的"分辨率适应性"。
C-ROPE的设计核心是 "结合绝对位置嵌入的稳定性 + RoPE2D的分辨率适应性",实现原生分辨率支持。
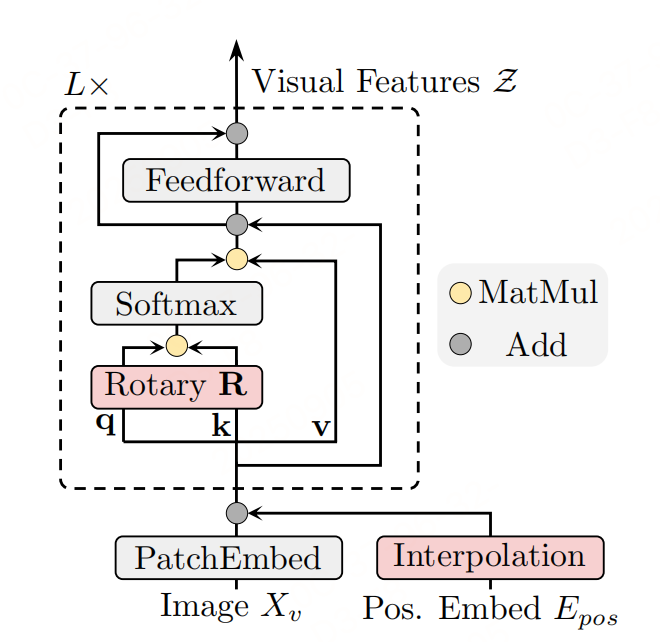
C-ROPE的流程如上图所示:
- 图像分块(Patchify) :将原生分辨率为 ( H , W ) (H,W) (H,W)的图像分割为 N = H W / P 2 N=HW/P^2 N=HW/P2个patch( P P P为patch尺寸, C C C为图像通道数),得到patch特征 x p ∈ R N × ( P 2 ⋅ C ) x_p \in \mathbb{R}^{N \times (P^2 \cdot C)} xp∈RN×(P2⋅C);
- 绝对位置嵌入插值 :将预训练好的固定尺寸位置嵌入 E p o s E_{pos} Epos通过双线性插值( I n t ( ⋅ ) Int(\cdot) Int(⋅))调整到当前patch数量 N N N,加到patch特征中,提供基础位置信息;
- RoPE2D旋转 :对Transformer的query(q)和key(k)应用2D旋转矩阵 R R R,捕捉patch间的相对位置关系(适配任意分辨率);
- 后续通过投影层( P r o j ( ⋅ ) Proj(\cdot) Proj(⋅))和前馈网络( F F N ( ⋅ ) FFN(\cdot) FFN(⋅))输出视觉特征 Z Z Z。
通过上述流程:无需固定图像输入尺寸,原生支持高分辨率图像(如1024px、2048px);
相比纯RoPE2D,数据效率更高(消融实验显示,C-ROPE在相同数据下性能提升显著)
2 Alignment Loss:跨模态表征对齐损失
传统方法通过适配器(Adapter)将视觉特征投影到语言空间,但监督信号(如next-token预测)过于间接,尤其是纯视觉预训练的VFMs(如DINOv2),表征差距难以缩小。Alignment Loss的核心是 直接对齐视觉与语言特征,且无需大batch或额外文本编码器。
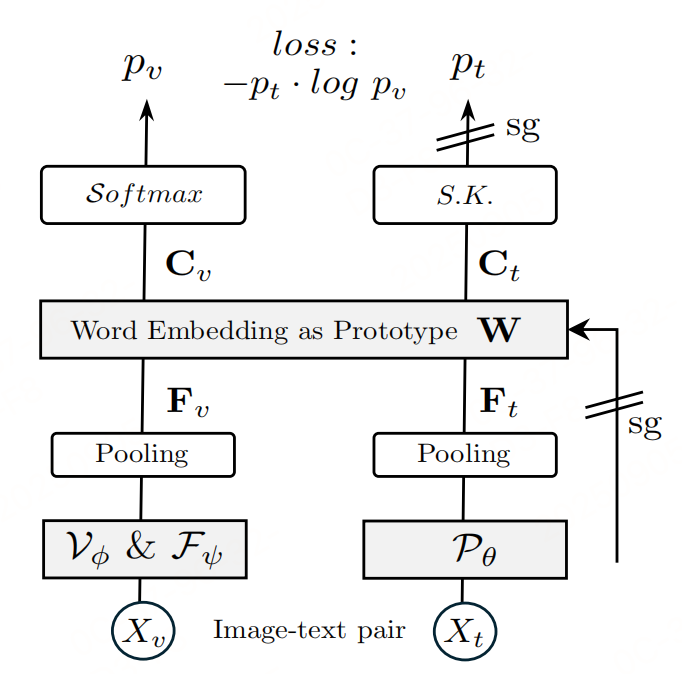
Alignment Loss的操作流程如上图右所示:
- 提取全局特征 :
- 视觉全局特征 F v F_v Fv:对VFMs输出的视觉特征 Z Z Z做无参数全局平均池化;
- 文本全局特征 F t F_t Ft:对LLMs处理文本后的特征做全局平均池化(不含图像前缀,避免信息泄露);
- 原型映射 :将 F v F_v Fv和 F t F_t Ft通过LLM的词嵌入矩阵 W W W(作为固定原型,不更新梯度)映射到语言空间,得到 C v = F v ⋅ W C_v = F_v \cdot W Cv=Fv⋅W和 C t = F t ⋅ W C_t = F_t \cdot W Ct=Ft⋅W( K K K为LLM词汇表大小);
- 软归一化 :
- 视觉特征 C v C_v Cv用Softmax归一化得到 p v p_v pv;
- 文本特征 C t C_t Ct用 Sinkhorn-Knopp算法 归一化得到 p t p_t pt(利用词嵌入的先验分布,比Softmax更灵活);
- 交叉熵损失 :计算 p v p_v pv和 p t p_t pt的交叉熵,仅更新VFMs参数(LLM参数冻结),确保视觉特征向语言空间对齐。
训练方法
- 阶段一:视觉-语言适配器预热。冻结 VFM 和 LLM,仅在固定低图像分辨率下训练适配器,且不使用 RoPE-2D。
- 阶段二:原生分辨率适应。使用 RoPE-2D 在固定高图像分辨率下训练整个模型一段时间,随后在原生分辨率下继续训练。
- 阶段三:指令微调(可选)。在原生分辨率下使用 RoPE-2D 对整个模型进行指令数据集的微调,以适应不同类型的数据输入。
训练目标:
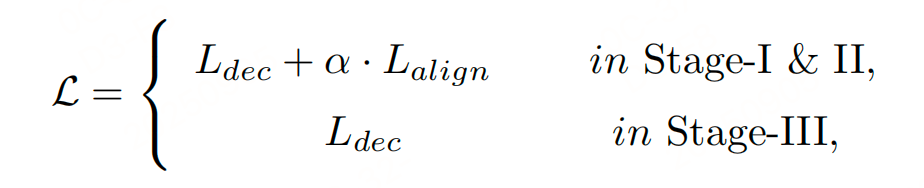
训练数据:
- 预训练数据:采用LLaVA-Pretrain + LLaVA-Mid-Stage数据,包含图像-文本对、高分辨率图表/文档数据;
- 指令微调数据:LLaVA-OV-SI SFT数据,覆盖多模态问答、图表理解等任务。
实验性能
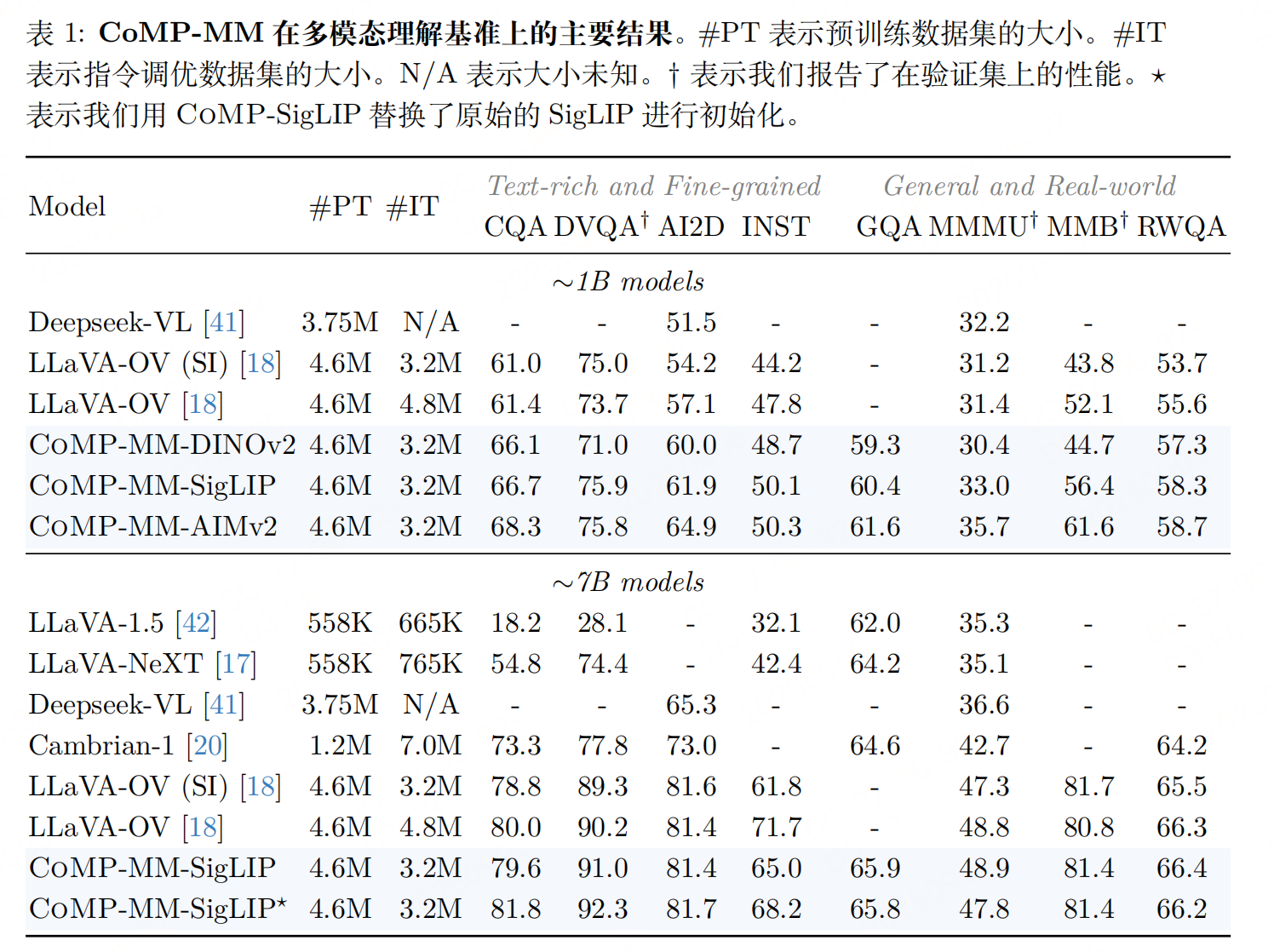
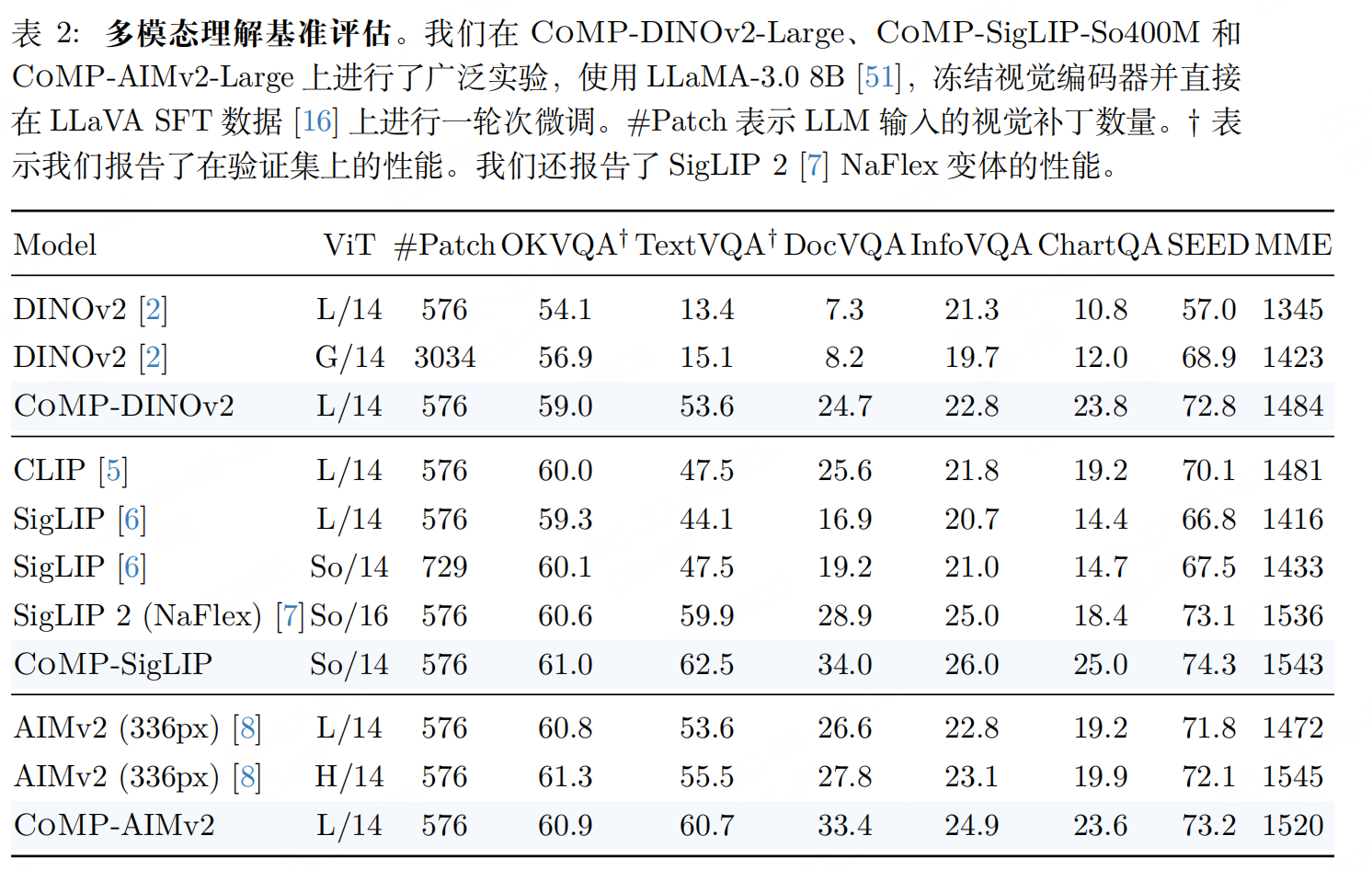
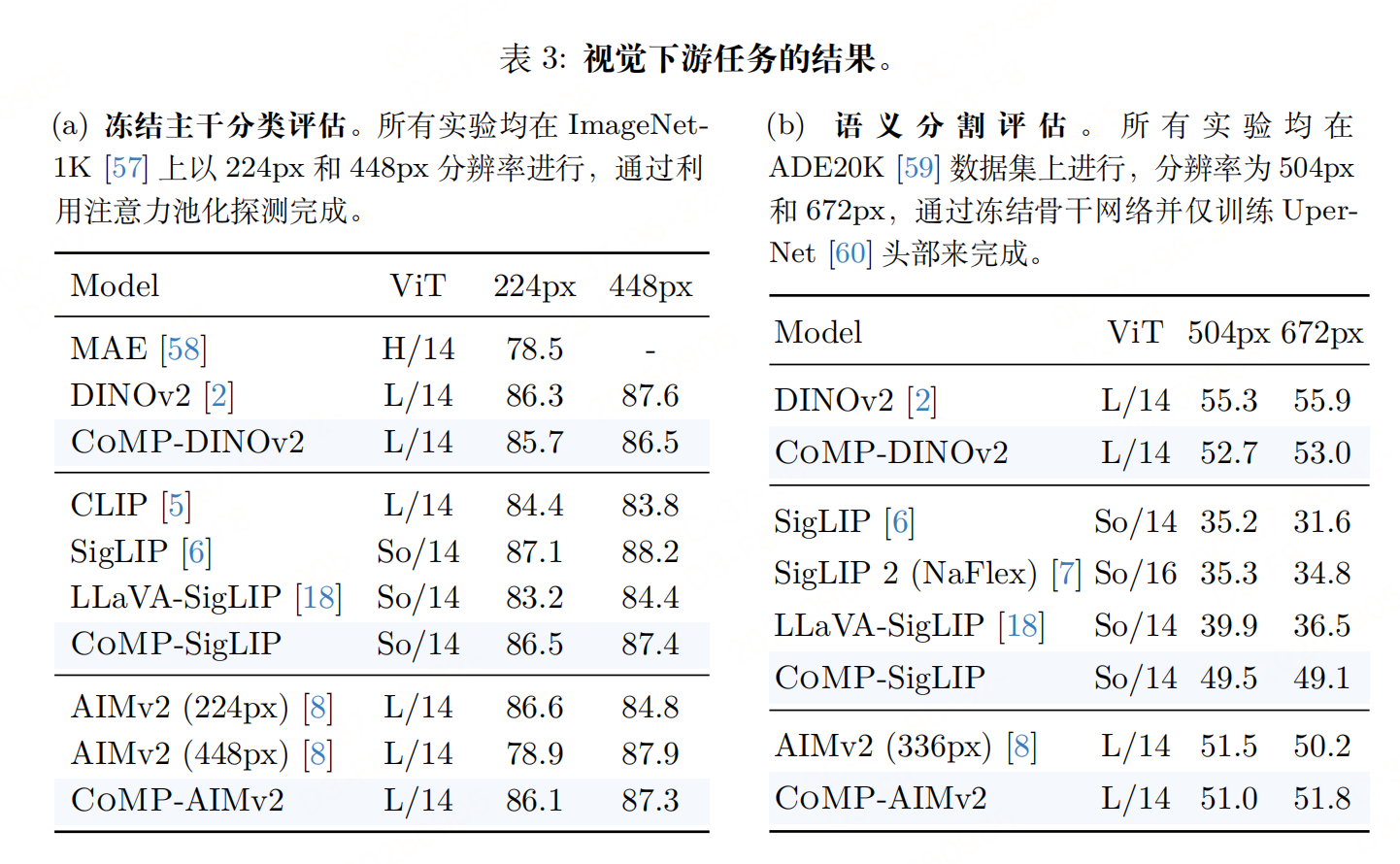
参考文献:paper:COMP: Continual Multimodal Pre-training
for Vision Foundation Models,https://arxiv.org/pdf/2503.18931