推理被高度认可为生成人工智能的下一个前沿领域。通过推理,我们可以将任务分解为更小的子集并单独解决这些子集。例如以前的论文:思维链、思维树、思维骨架和反射,都是最近解决LLM推理能力的一些技术。此外推理还涉及一些外围功能,例如访问外部数据或工具。在最近的几年里,我们已经看到模型在特定的推理技术中表现得非常好,但它们无法跨领域推广。这是Meta AI、Allen Institute of AI和University of Washington的研究人员在最近一篇论文中所要解决的问题。
HUSKY是一个开源语言代理,设计用于处理各种复杂的任务,包括数字、表格和基于知识的推理。与其他专注于特定任务或使用专有模型的代理不同,HUSKY在统一的框架内运行。它分为两个阶段:1、生成解决任务所需的下一个行动;2、它使用专家模型执行此操作,并在此过程中更新解决方案。
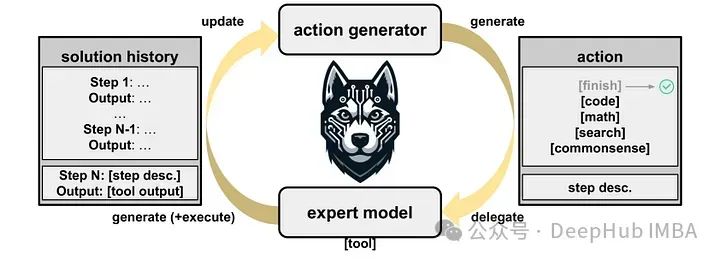
这个框架的名字来源于 "哈士奇"因为雪橇犬在拉雪橇时是一起来合作前进的,并且在前进的过程中要针对路面情况有自己的判断和决定,这非常符合这个代理的工作思路。但是看到这个名字我总感觉这个代理不太聪明的样子。

HUSKY
HUSKY采用详细的行动计划来处理复杂的任务,它先生成下一步,其中包括所需的操作和工具。然后使用专门的模型执行操作,更新解决方案状态。这种方法允许HUSKY像经典规划系统一样运行,使用大型语言模型(llm)来优化性能。
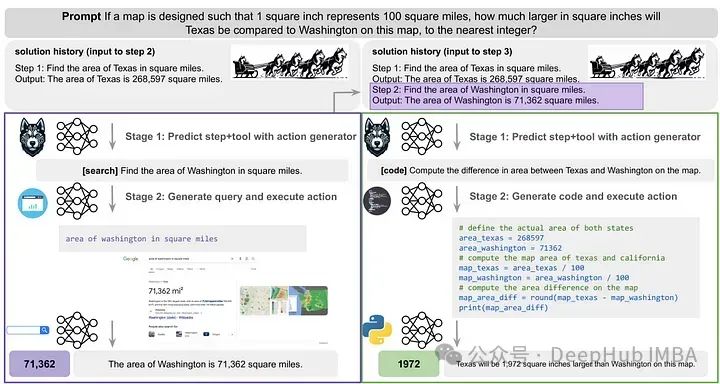
对于需要多步推理的任务,HUSKY预测下一个动作和相应的工具,然后用专家模型执行。这个过程一直持续到找到最终答案为止。HUSKY使用多个llm来协调专家模型,类似于一组哈士奇一起拉雪橇。
HUSKY在生成动作和执行动作之间迭代,直到达到终端状态。动作生成器预测下一个高级步骤,并从预定义集合(代码、数学、搜索或常识)中分配一个工具。根据指定的工具,HUSKY调用专家模型,执行操作,并更新解决方案状态,可选择将输出转换为自然语言。
训练
HUSKY的训练包括使用教师模型创建工具集成解决方案轨迹。这些轨迹有助于为动作生成器和专家模型构建训练数据。训练管道是简化和通用的,确保HUSKY可以处理广泛的任务,而无需任务特定的假设。
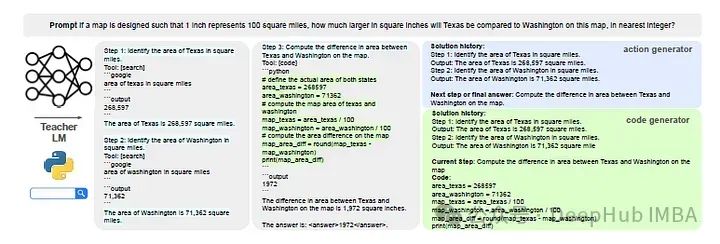
推理
在推理过程中,HUSKY集成其训练模块来解决新的多步骤任务。动作生成器确定第一步和工具,然后将其传递给专家模型,由专家模型产生输出。这个迭代过程一直持续到最终解决方案的实现,专家模型为每一步提供特定的输出。
表现评估
评估HUSKY包括测试其在复杂推理任务上的推理能力并对结果进行评分。现有数据集通常缺乏HUSKY所需工具的多样性,因此作者创建了一个新的评估集HUSKYQA来测试混合工具推理。这组任务包括需要检索缺失的知识和执行数值推理的任务。尽管使用较小的模型,但HUSKY匹配或超过了GPT-4等前沿模型,证明了它的有效性。
在需要多步骤推理和工具使用的各种任务中,HUSKY与其他基线语言代理一起接受了训练和评估。这些任务的一半用于根据工具集成解决方案路径训练HUSKY的模块,而另一半用于测试训练结果。最后的验证阶段则都是用零样本的方式进行评估。
1、数值推理任务
数值推理任务包括从小学到高中比赛水平的数学数据集。这些数据集包括GSM-8K、MATH、Google DeepMind数学任务和MathQA,都取自LILA基准。对于Google DeepMind数学,重点是代数、基础数学、微积分、乘法/除法和数论子集。对于MathQA,子集包括增益、通用、几何、物理和概率。使用GSM-8K和MATH进行训练,总共提供13.7K的工具集成解决方案路径。
2、表格推理任务
表格推理任务涉及TabMWP,一个表格数学问题的数据集,FinQA和TAT-QA,这两个数据集都是金融问答数据集,以及MultimodalQA的测试问题子集,这需要理解文本和表格数据。TabMWP和FinQA用于训练和评估,TAT-QA和MultimodalQA用于评估。这些数据集总共提供了7.2万个工具集成的解决方案路径。
3、基于知识的推理任务
基于知识的推理任务包括HotpotQA、CWQ、musque、Bamboogle和StrategyQA。HotpotQA和Bamboogle用于评估,CWQ和musque用于训练,两者都使用StrategyQA。这个集合产生了总共7K个工具集成的解决方案路径。
4、评估模型
评估包括以下模型:
动作生成器:对于动作生成器,采用了LLAMA-2-7B, 13B和LLAMA-3-8B。从训练集中删除了不正确的解决方案路径,从而在数字、表格、基于知识和混合工具的推理任务中产生了110K个实例。动作生成器在这个多任务训练集上进行了充分的微调。
代码生成器:以其强大的编码能力而闻名的deepseekcode - 7b - instruct - v1.5模型被选为微调代码生成器。使用正确的解决方案路径提取所有必要的代码,从而产生用于训练的44K代码实例。
数学推理器:选择DEEPSEEKMATH-7B-INSTRUCT模型是因为它具有先进的数学推理能力。正确的解决方案路径为微调数学推理器提供了30K数学解决方案实例。
查询生成器:查询生成器使用LLAMA-2-7B作为基本模型。正确的解决方案路径产生22K搜索查询实例,用于微调查询生成器。
结果如下:
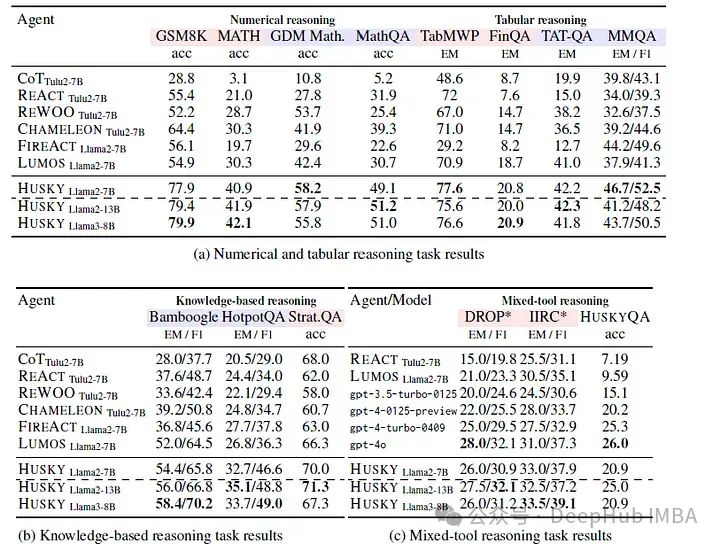
可以看到HUSKY通过整合不同的高效模型,并为不同的任务分配了不同的专家代理,为复杂的推理任务提供了一个通用的、开源的解决方案。它的整体方法,将行动生成和执行与专家模型相结合,使其能够有效地处理各种挑战。从各种评估中可以看出,HUSKY赫斯基的表现突出了其重新定义语言代理如何解决复杂问题的潜力。
https://avoid.overfit.cn/post/9c05e34dc60645bfb6f6a47df294b5e8
作者:Jesus Rodriguez