[介绍Fast R-CNN之前先简单回顾一下R-CNN和SPP-net](#介绍Fast R-CNN之前先简单回顾一下R-CNN和SPP-net)
[R-CNN(Regions with CNN)](#R-CNN(Regions with CNN))
[affine image wraping 解析](#affine image wraping 解析)
[Bounding Box Regression(边界框回归)](#Bounding Box Regression(边界框回归))
[1 背景](#1 背景)
[SPP(spatial pyramid pooling)的三大性质(优点):(这里直接引用原文)](#SPP(spatial pyramid pooling)的三大性质(优点):(这里直接引用原文))
[2 SPP-net](#2 SPP-net)
[2.1 SPP-net的两大创新点:](#2.1 SPP-net的两大创新点:)
[2.2 具体流程](#2.2 具体流程)
[2.3 训练策略](#2.3 训练策略)
[3 SPP-net与目标检测](#3 SPP-net与目标检测)
[3.1 目标检测流程](#3.1 目标检测流程)
[3.2 SVM的训练和使用](#3.2 SVM的训练和使用)
[3.3 多尺度特征提取 multi-scale feature extraction](#3.3 多尺度特征提取 multi-scale feature extraction)
[Fast R-CNN](#Fast R-CNN)
[1 背景](#1 背景)
[2 Fast R-CNN结构和关键技术](#2 Fast R-CNN结构和关键技术)
[2.1 总体结构(inference过程)](#2.1 总体结构(inference过程))
[2.2 一种更有效的训练方法(hierarchical sampling)](#2.2 一种更有效的训练方法(hierarchical sampling))
[2.3 多任务损失(multi-task loss)](#2.3 多任务损失(multi-task loss))
[2.4 mini-batch sampling](#2.4 mini-batch sampling)
[2.5 BP through RoI pooling layers](#2.5 BP through RoI pooling layers)
[2.6 SGD超参数](#2.6 SGD超参数)
[2.7 Scale invariance(尺度不变性)](#2.7 Scale invariance(尺度不变性))
[3 Fast RCNN detection](#3 Fast RCNN detection)
[4 各类策略](#4 各类策略)
[4.1 Truncated SVD](#4.1 Truncated SVD)
[4.2 fine-tune](#4.2 fine-tune)
[1.文中仅采用selective search算法提取约2k个候选区域,那候选区域越多越好吗?](#1.文中仅采用selective search算法提取约2k个候选区域,那候选区域越多越好吗?)
[one vs rest:](#one vs rest:)

介绍Fast R-CNN之前先简单回顾一下R-CNN和SPP-net
R-CNN(Regions with CNN)
R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014
R-CNN是Ross Girshick大神的一大杰作,14年发表在CVPR上,目前已有超过2万的引用量,在目标检测领域有着里程碑式的意义
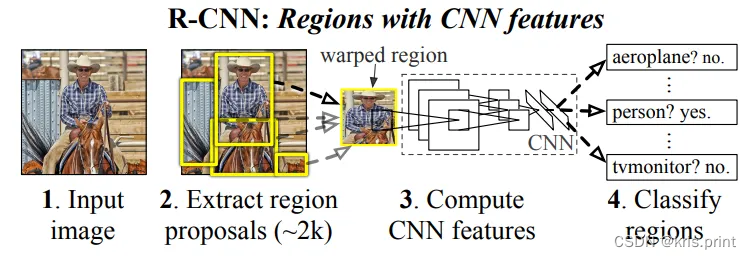
模型inference流程:(输入是任意大小的RGB图像)
(1)selective research :在每张图上生成2000个候选框(region proposal),该过程无可学习的参数
(2)affine image wraping:使用wrap、tightest square without context和tightest square with context三种方法,将大小各异的候选框形变为固定大小227*227,作为AlexNet的输入
(3)AlexNet:训练好的AlexNet生成2000个(共2000个框)4096维特征向量(2000*4096)
(4)SVM:训练好的SVM进行20个类别的分类,可以理解为一个(4096*20)的矩阵,(2000*4096)*(4096*20)=(2000*20),即计算了每个建议框属于每一种类别的概率
(5)NMS:得到(2000*20)维矩阵后后,对每一类(即每一列)执行NMS,剔除重叠的建议框
(6)Bounding Box Regression:使用20个回归器对20个类别中剩余的建议框进行回归操作,让定位框位置更准确
affine image wraping 解析

示例1---从左到右,第一列是object的实际大小,第二列是tightest square with context,第三列是tightest square without context,第四列是warp。第一行没有 context padding ,第二行有context padding(pixels=16)  实例二
实例二
- tightest square with context:相当于在原图上用一个最小的正方形将建议框包围起来,然后将正方形里的图像形变为227*227
- tightest square without context:和第一种方法类似,但是需要把建议框以外的图片背景去掉
- warping:直接形变建议框
- context padding(p=16):在原图上放大建议框,上下左右各添加16像素,即让输入到CNN中的图片包含更多context 信息
Bounding Box Regression(边界框回归)

BBR的目的是微调建议框 ,让建议框更加接近GT。那么如何微调?------调整建议框中心坐标 (𝑃𝑥,𝑃𝑦) 和长宽 (𝑃𝑤,𝑃ℎ)
如何回归?

本质上就是学习四组不同的参数 𝑤∗ ,学习到参数后,在inference阶段,可以由 𝑤∗ 计算预测值 𝑡^∗ ,再由 𝑡^∗ 计算 𝐺^∗ ( ∗=𝑥,𝑦,𝑤,ℎ ),从而得到位置更加精准的建议框

问题1:为什么要使用相对坐标差?

问题2:为什么使用log?
为了限制尺度必须大于0,最简单的方法就是exp函数,即 𝐺^𝑥=𝑃𝑥×𝑒𝑗^𝑥 ,这样可以保证得到的 𝐺^𝑥 是大于0的,反推过来 𝑗^𝑥=𝑙𝑜𝑔(𝐺𝑥/𝑃𝑥)
问题3:为什么IoU较大时边界框回归可视为线性变换?

SPP-net
K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, 2014(6500+引用)
1 背景
SPP-net之前:多数基于CNN的目标检测模型要求固定大小的输入图像(因为全连接层要求固定大小的输入),对不符合要求的图像需要进行crop或者wrap,但是crop会损失部分信息,wrap也可能会改变物体的长宽比使图像失真

SPP-net的灵感来自于:
SPP(spatial pyramid pooling)的三大性质(优点):(这里直接引用原文)
- SPP is able to generate a fixed-length output regardless of the input size, while the sliding window pooling used in the previous deep networks cannot
- SPP uses multi-level spatial bins, while the sliding window pooling uses only a single window size. Multi-level pooling has been shown to be robust to object deformations
- SPP can pool features extracted at variable scales thanks to the flexibility of input scales
2 SPP-net
2.1 SPP-net的两大创新点:
(1)在RCNN中,一张图图片会有大约2k个候选框,每一个都要单独输入CNN做卷积等操作,计算量大、费时。SPP-net只对整幅图像做一次卷积,在feature map上提取ROI
(2)首次将SPP和CNN结合,让网络输入图片的大小不再受限制
SPP-net同时继承了:1.the power of the deep CNN feature maps;2.the flexibility of SPP on arbitrary window sizes
2.2 具体流程
 top: SPPnet之前传统卷积网络结构 bottom: SPPnet
top: SPPnet之前传统卷积网络结构 bottom: SPPnet 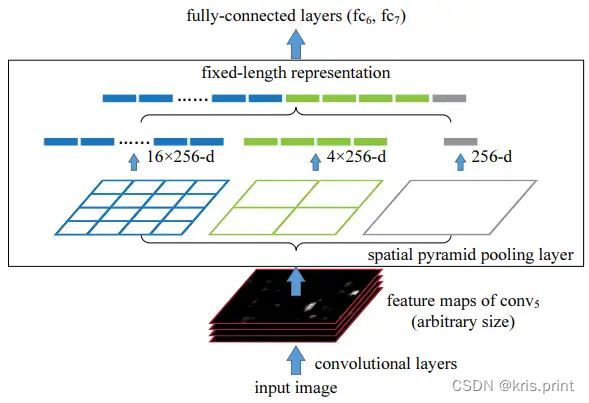 SPP层(在最后一个卷积层之后)
SPP层(在最后一个卷积层之后)
对conv5输出feature maps中的每一张feature map,分别做 4×4 、 2×2 、 1×1 的卷积,输出一个长度为 (16+4+1) 的向量,最终SPP层输出是 (16+4+1)×256 维固定大小向量
池化的区块大小和步长:区块大小上取整(ceiling operation),例如 13/2=7 ;步长下取整(floor operation),例如 13/2=6 。但总之SPP层的输出大小都是固定的
 conv5层输出大小为13*13*256时SPP层的size和stride
conv5层输出大小为13*13*256时SPP层的size和stride
可以使用标准BP算法对SPP-net进行训练(Theoretically, the above network structure can be trained with standard backpropagation)
2.3 训练策略
- 单一尺度策略:固定输入大小为224*224
- 多尺度策略:可以提升模型性能。一个epoch使用224*224的输入,一个epoch使用180*180的输入,切换epoch时网络参数共享(相当于两个网络,一个"固定"输入为224,一个"固定"输入为180,输入不同但是网络参数是完全相同的,可以互相copy)
3 SPP-net与目标检测
3.1 目标检测流程

- selective search:使用selective search的"fast"模式,在每张输入图像上产生2000个候选框(candidate windows)
- convolution:计算一次特征图
- SPP:对每个候选框使用4层的金字塔池化(1*1 / 2*2 / 3*3 / 6*6),最终产生50*256=12800维的特征
- FC (full connected layer):接收12800维向量,假设输出向量长度1000
- SVM:对每一个category分别train一个二分线性SVM类器(a binary linear SVM classifier) 。如果有20个类别,就有20个SVM,每个SVM代表一个维度为(1000*2)的权重。FC层输出为(2000*1000),则一个SVM输出维度为(2000*1000)*(1000*2)=(2000*2)
- NMS:inference阶段使用NMS
- BBR(bounding box regression):回归使用的特征来自conv5,回归训练使用的框至少和GT重叠50%
为什么不直接训练一个n分类的SVM?而是n个二分类的SVM?
3.2 SVM的训练和使用
positive samples使用ground truth windows,negative samples使用和GT重叠度在30%以下的框,如果一个negative sample和另外一个negative sample重叠度大于70%,则删除两个中的一个。使用standard hard negative mining策略训练SVM。训练完毕后使用SVM分类器对候选框(candidate windows)打分,再使用阈值为0.3的NMS(non-maximum suppression)
3.3 多尺度特征提取 multi-scale feature extraction
将每张图像resize成 𝑚𝑖𝑛(𝑤,ℎ)=𝑠∈𝑆 , 𝑆={480,576,688,864,1200} ,即每张图像的长和宽的最小值被限制
对每一个candidate window,我们选择 𝑆 中的某个 𝑠 ,使candidate window的大小最接近224*224,然后仅使用 𝑠 尺度的图像计算feature maps,并提取该candidate window的feature
该方法近似于将所有windows都resize成224*224,然后使用CNN提取特征(但是该方法只需要计算一次特征图)
多尺度特征提取的依据和意义在哪?(Our method can be improved by multi-scale feature extraction,仅仅是因为这样可以提升模型效果?empirically find,依据仅仅是因为经验发现?)
Fast R-CNN
Fast R-CNN是Ross Girshick的续作,15年发表在ECCV,目前已有超过1.5W的引用量。Fast R-CNN比RCNN快9倍,比SPP-net快3倍,inference一张图片耗时仅0.3s(RCNN需要47s),在PASCAL VOC 2012上有66%的mAP(RCNN为62%)
1 背景
目标检测的两大挑战:(1)需要处理的候选框过多;(2)候选框的位置不精确要进行微调;
R-CNN的缺点:
- 训练和测试过程复杂:R-CNN网络训练过程分为ILSVRC 2012样本下有监督预训练、PASCAL VOC 2007该特定样本下的微调、20类即20个SVM分类器训练、20类即20个Bounding-box 回归器训练,该训练流程繁琐复杂;同理测试过程也包括提取候选框、提取CNN特征、SVM分类和Bounding-box 回归等步骤
- R-CNN网络训练需要大量存储空间:20类即20个SVM分类器和20类即20个Bounding-box 回归器在训练过程中需要大量特征作为训练样本,这部分从CNN提取的特征会占用大量存储空间
- R-CNN网络需要对候选框进行形变操作后(形变为227*227)再输入CNN网络提取特征,形变会产生一些列问题(在SPP-net部分已经陈述过)
SPPnet的缺点:
- 虽然只需要提取一次特征图,但是依然包含了特征提取、微调网络、训练SVM、边界框回归多个步骤,模型复杂
- 微调算法不能更新SPP之前的卷积层(SPPnet is unable to update weights below the spatial pyramid pooling layer.)
2 Fast R-CNN结构和关键技术
2.1 总体结构(inference过程)

- CNN:将任意size的图像输入网络,计算整张图的feature maps
- Selective search:在任意size图片上采用selective search算法提取约2k个候选框
- RoI projection:在特征图中找到每个候选框对应的特征框(深度和特征图一致)
- RoI pooling:相当于只有一层的空间金字塔池化SPP,将每个特征框划分为H*W个网格(eg: 7*7 for VGG16),每个网格中执行最大池化,输出为H*W*C,特征图深度不变。RoI pooling的输出需要满足下一层全连接层输入要求
- FC+softmax/bbox regerssion
- **NMS:**利用窗口得分分别对每一类物体进行非极大值抑制剔除重叠候选框,最终得到每个类别中回归修正后的得分最高的窗口
2.2 一种更有效的训练方法(hierarchical sampling)
首先SPP-net不能更新SPP层以下的权重,原因是当每一个训练样本都来自不同的image时,通过SPP层的反向传播效率非常低(这里应该如何理解?SPP层的出现究竟对反向传播有什么影响??)
The root cause is that back-propagation through the SPP layer is highly inefficient when each training sample (i.e. RoI) comes from a different image
The inefficiency stems from the fact that each RoI may have a very large receptive field, often spanning the entire input image. Since the forward pass must process the entire receptive field, the training inputs are large (often the entire image).
Fast R-CNN的训练方法要求训练样本尽量来自于同一张image,这样可以大大降低计算量,比如一个minbatch都128个样本,这128个训练样本只来自于2张image,理论上一张图像上的64个样本可能会非常"相似"(关联性很强),会不会降低模型的收敛速度?需要很多轮的训练------但是作者在实际使用该策略时并没有发现该问题,模型依然可以很快收敛
One concern over this strategy is it may cause slow training convergence because RoIs from the same image are cor- related. This concern does not appear to be a practical issue and we achieve good results with N = 2 and R = 128 using fewer SGD iterations than R-CNN
2.3 多任务损失(multi-task loss)
Fast R-CNN有两个并行输出(two sibling output layers),第一个是FC层接softmax,输出离散概率类别预测(per RoI), 𝑝=(𝑝0,⋯,𝑝𝐾) ,一共 𝐾+1 个类别;第二个输出边界框回归的偏移值(offsets), 𝑡𝑘=(𝑡𝑥𝑘,𝑡𝑦𝑘,𝑡𝑤𝑘,𝑡ℎ𝑘) , 𝑘 代表类别 𝑘 ,再根据偏移值计算修正后的框(和RCNN是类似的,只不过这里直接使用CNN输出偏移值,不再训练单独的回归器)

多任务损失 𝐿 如下

需要注意,超参数 𝜆 用来平衡两个任务的损失,实验中统一设置为1
We normalize the ground-truth regression targets 𝑣𝑖 to have zero mean and unit variance
(这里为什么要把BBR的真实偏移值标准化?)
多任务训练的好处------Multi-task training is convenient because it avoids managing a pipeline of sequentially-trained tasks. But it also has the potential to improve results because the tasks influence each other through a shared representation
2.4 mini-batch sampling
mini-batch的大小为128,每张图片提取64个RoI。非背景类和GT的IoU至少为0.5,背景类和GT的IoU范围为0.1到0.5
The lower threshold of 0.1 appears to act as a heuristic for hard example mining
(背景类的IoU下限0.1和hard example mining有什么关系?这里参考了DPM的论文)
2.5 BP through RoI pooling layers

2.6 SGD超参数
All layers use a per-layer learning rate of 1 for weights and 2 for biases and a global learning rate of 0.001
(三种不同的learning rate?)
When training on VOC07 or VOC12 trainval we run SGD for 30k mini-batch iterations, and then lower the learning rate to 0.0001 and train for another 10k iterations. When we train on larger datasets, we run SGD for more iterations, as described later. A momentum of 0.9 and parameter decay of 0.0005 (on weights and biases) are used.
2.7 Scale invariance(尺度不变性)
使用两种方法实现尺度不变性(全部参考SPP-net):(1)"brute force" learning;(2)image pyramids
In the brute-force approach, each image is processed at a pre-defined pixel size during both training and testing. The network must directly learn scale-invariant object detection from the training data
At test -time, the image pyramid is used to approximately scale-normalize each object proposal. During multi-scale training, we randomly sample a pyramid scale each time an image is sampled, following SPP-net, as a form of data augmentation
如何处理尺度不变性问题?即如何使24×24和1080×720的车辆同时在一个训练好的网络中都能正确识别?
brute-force(单一尺度)和image pyramids(多尺度)。单一尺度直接在训练和测试阶段将image定死为某种scale,直接输入网络训练就好,然后期望网络自己能够学习到scale-invariance的表达;多尺度在训练阶段随机从图像金字塔中采样训练(将图像按多种比例缩放,然后从中随机采样?),测试阶段将图像缩放为金字塔中最为相似的尺寸进行测试
作者对单一尺度和多尺度分别进行了实验,不管哪种方式下都定义图像短边像素为s,单一尺度下s=600(维持长宽比进行缩放),长边限制为1000像素;多尺度s={480,576,688,864,1200}(维持长宽比进行缩放),长边限制为2000像素,生成图像金字塔进行训练测试;实验结果表明AlexNet、VGG_CNN_M_1024下单一尺度比多尺度mAP差1.2%~1.5%,但测试时间上却快不少,VGG-16下仅单一尺度就达到了66.9%的mAP(由于GPU显存限制多尺度无法实现),该实验证明了深度神经网络善于直接学习尺度不变形,对目标的scale不敏感
3 Fast RCNN detection
以一张图像(使用图像金字塔时是多张图像)和多个目标建议框作为输入,建议框(object proposals)大约有2000个,使用image pyramid时,尽量使每个RoI的scale接近224*224(这点参考了SPP-net)
对每个RoI,前向传播最终会输出一个类别概率分布 𝑝 和预测的边界框偏移值
each of the K classes gets its own refined bounding-box prediction
(对每一个类别都有不同的预测偏移值??边界框偏移值和类别也有关系?比如有20个类,则为每一个RoI预测20组偏移值?)
同时为每个RoI赋一个class-wise检测置信度分数(detection confidence for each object class k)
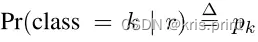
最后针对每个类别,执行NMS
4 各类策略
4.1 Truncated SVD
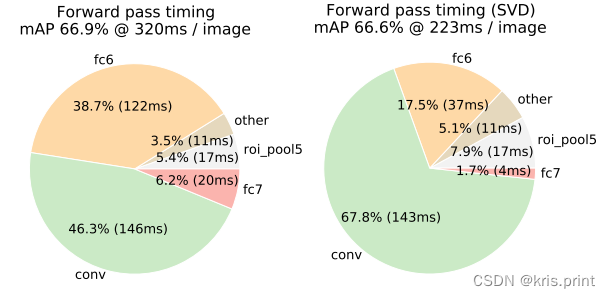
模型前向传递过程,有近一半时间花费在了全连接层的计算上,就Fast R-CNN而言,RoI池化层后的全连接层需要进行约2k次(每个建议框都要计算),可以使用truncated SVD压缩全连接层,从而加速运算
假设全连接层输入数据为x,输出数据为y,全连接层参数为W,尺寸为u×v,那么该层全连接计算为 𝑦=𝑊𝑥 ,计算复杂度为u×v
若将W进行SVD分解,并用前t个特征值近似代替

那么原来的前向传播分解成两步,计算复杂度为u×t+v×t,若t<min(u,v),则这种分解会大大减少计算量。在实现时,相当于把一个全连接层拆分为两个全连接层,第一个全连接层不含偏置,第二个全连接层含偏置;实验表明,SVD分解全连接层能使mAP只下降0.3%的情况下提升30%的速度,同时该方法也不必再执行额外的微调操作

Truncated SVD大大降低了单张图像前向传递的时间,仅会损失很少的mAP
4.2 fine-tune
通过实验证明了微调卷积层非常重要,但是所有卷积层都需要fine-tuning么?------no,例如conv1是独立的,允许or不允许conv1学习,不会对最后的mAP产生影响(conv1 is generic and task independent / Allowing conv1 to learn, or not, has no meaningful effect on mAP)------为什么conv1是独立的??
VGG16_Fast_RCNN只微调conv3_1及之后的layer
QA
1.文中仅采用selective search算法提取约2k个候选区域,那候选区域越多越好吗?
文中利用selective search算法提取1k~10k中10种数目【1k,2k...】的候选区域进行训练测试,发现随着候选区域个数的增加,mAP成先增加后缓慢下滑的趋势,这表明更多的候选区域会有损精度;与此同时,作者也做了召回率【所谓召回率即候选区域为真的窗口与Ground Truth的比值【IoU大于阈值即为真】】分析实验,发现随着候选区域个数的增加,召回率并没有和mAP成很好的相关性,而是一直不断增加,也就是说更高的召回率并不意味着更高的mAP
文中也以selective search算法提取的2k个候选区域为基础,每次增加1000 × {2, 4, 6, 8, 10, 32, 45}个密集box【滑动窗口方法】进行训练测试,发现mAP比只有selective search方法的2k候选区域下降幅度更大,最终达到53%
2.为什么不沿用R-CNN中的形式继续采用SVM进行分类?
文中分别进行实验并对比了采用SVM和采用softmax的mAP结果,不管AlexNet、VGG_CNN_M_1024、VGG-16中任意网络,采用softmax的mAP都比采用SVM的mAP高0.1%~0.8%,这是由于softmax在分类过程中引入了类间竞争,分类效果更好
We note that softmax, unlike one-vs-rest SVMs, introduces competition between classes when scoring a RoI.
one vs rest:
假如我有四类要划分(也就是4个Label),他们是A、B、C、D。于是我在抽取训练集的时候,分别抽取A所对应的向量作为正集,B,C,D所对应的向量作为负集;B所对应的向量作为正集,A,C,D所对应的向量作为负集;C所对应的向量作为正集,A,B,D所对应的向量作为负集;D所对应的向量作为正集,A,B,C所对应的向量作为负集,这四个训练集分别进行训练,然后的得到四个训练结果文件,在测试的时候,把对应的测试向量分别利用这四个训练结果文件进行测试,最后每个测试都有一个结果f1(x),f2(x),f3(x),f4(x).于是最终的结果便是这四个值中最大的一个