
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」
统计学中的回归
- 目标:
- 主要用于解释和推断自变量(independent variables)和因变量(dependent variables)之间的关系。
- 强调模型的解释性,了解各个自变量对因变量的影响。
- 假设:
- 假设数据符合特定统计假设,如正态分布、独立性和同方差性。
- 需要满足严格的模型假设。
- 模型复杂性:
- 通常使用简单模型,如线性回归。
- 模型形式固定,主要是线性或加性模型。
- 数据量:
- 通常处理较小的数据集。
- 评估方法:
- 强调参数的显著性检验(significance tests)。
- 使用 R 平方((R^2))和 P 值(P-value)等统计指标。
机器学习中的回归
- 目标:
- 主要用于预测,关注模型的预测性能。
- 更关注模型的泛化能力(generalization ability),即在新数据上的表现。
- 假设:
- 对数据分布和模型形式的假设较少。
- 灵活性更大,不需要满足严格的统计假设。
- 模型复杂性:
- 使用复杂模型,如决策树回归(decision tree regression)、随机森林回归(random forest regression)、支持向量回归(support vector regression)和神经网络(neural networks)等。
- 模型可以是非线性的,适应复杂数据模式。
- 数据量:
- 通常处理大规模的数据集。
- 评估方法:
- 使用交叉验证(cross-validation)等方法评估模型性能。
- 强调预测误差,如均方误差(Mean Squared Error, MSE)和均绝对误差(Mean Absolute Error, MAE)。
总结
- 统计学中的回归:用于解释和推断变量之间的关系,假设严格,模型简单,适用于小数据集。重点在于理解数据和变量关系,模型解释性强。
- 机器学习中的回归:用于预测和优化,假设少,模型复杂,适用于大数据集。重点在于提高模型的预测性能,模型灵活性高。
图示解释
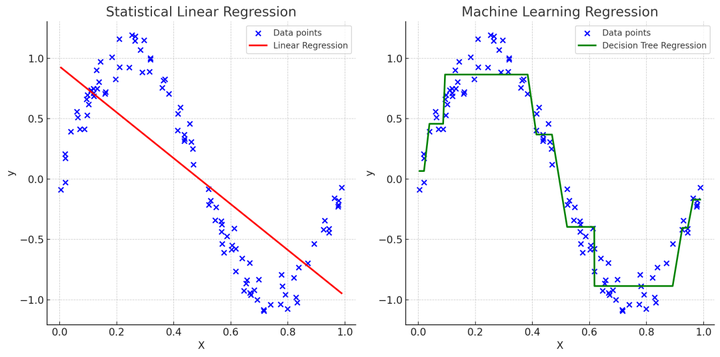
- 统计学中的线性回归:
- 图示:数据点分布在图上,一条直线(回归线)穿过数据点,显示自变量与因变量之间的线性关系。
- 解读:这条直线表示最小二乘法(Least Squares Method)拟合出的最佳线性关系,用于解释 (X) 和 (Y) 之间的关系。
- 机器学习中的非线性回归:
- 图示:数据点分布在图上,一条曲线穿过数据点,显示自变量与因变量之间的复杂非线性关系。
- 解读:这条曲线可能是通过复杂模型(如决策树、神经网络)拟合出的,显示出自变量和因变量之间更复杂的模式和关系。
这两者的差别主要体现在模型的目标、假设、复杂性、数据量和评估方法上,各有其应用场景和优势。

统计学中的回归主要强调模型的解释性和简洁性,因此通常采用简单的线性模型。下面是一些具体原因:
假设和解释性
- 解释性:
- 统计学中的回归模型强调解释变量对因变量的影响。
- 线性回归模型的系数具有明确的解释意义,可以直接说明每个自变量对因变量的线性贡献。
- 简洁性:
- 线性模型较为简单,易于理解和解释。
- 在变量关系相对简单的情况下,线性模型能有效地捕捉主要趋势。
- 假设检验:
- 统计学中的回归依赖于一定的假设,如正态分布、独立性和同方差性。
- 这些假设在简单的线性模型中更容易满足和检验。
数据量和计算复杂度
- 数据量:
- 统计学方法通常用于较小的数据集。
- 简单模型在小数据集上表现更好,因为复杂模型容易过拟合。
- 计算复杂度:
- 线性回归计算简单,适用于快速分析和建模。
- 非线性模型(如决策树)计算复杂度较高,训练和预测时间更长。
过拟合和泛化能力
- 过拟合:
- 复杂模型(如右图的决策树回归)容易过拟合,即在训练数据上表现很好,但在新数据上表现不佳。
- 线性模型的简单性有助于避免过拟合,提升模型的泛化能力。
应用场景
- 应用场景:
- 统计学中的回归主要用于变量关系的探索和解释,如社会科学和经济学研究。
- 在这些领域,理解变量间的关系和影响是主要目标,而不是追求复杂模型的预测性能。

图示解读
- 统计学中的线性回归(左图):
- 适用于数据关系较简单、主要目标是解释和推断的场景。
- 线性回归线展示了自变量和因变量之间的线性关系,便于解释。
- 机器学习中的决策树回归(右图):
- 适用于数据关系复杂、主要目标是预测和优化的场景。
- 决策树回归曲线展示了自变量和因变量之间的复杂非线性关系,但解释性较差。
抱个拳,总个结
统计学中的回归更关注模型的简洁性和解释性,适用于变量关系较为简单、数据量较小的场景。因此,通常采用线性回归模型。而机器学习中的回归更多用于预测复杂关系,模型复杂性更高,适用于大数据集和需要高预测性能的应用。- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵 内容仅供学习交流之用,部分素材来自网络,侵联删
算法金,碎碎念

全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖