#pragma once
#include<stdlib.h>
typedef struct SeqList
{
int* a;
int size;
int capacity;
}SL;
inline void SLInit(SL* pls, int n = 4)
{
pls->a = (int*)malloc(sizeof(int) * n);
pls->size = 0;
pls->capacity = 0;
}
void SLPushBack(SL* pls, int x);
int SLFind(SL* pls, int x, int i = 0);
int& SLat(SL* pls, int i);
void SLModify(SL* pls, int i, int x);
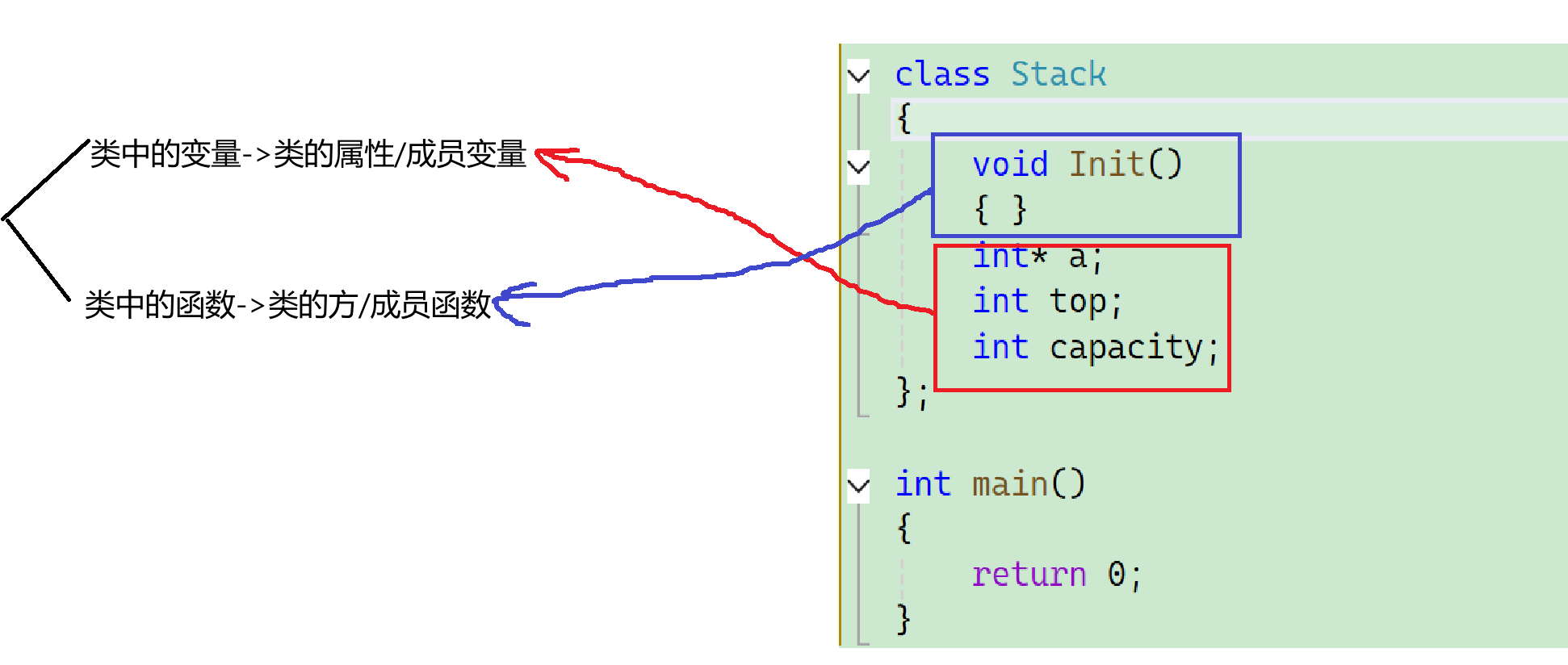
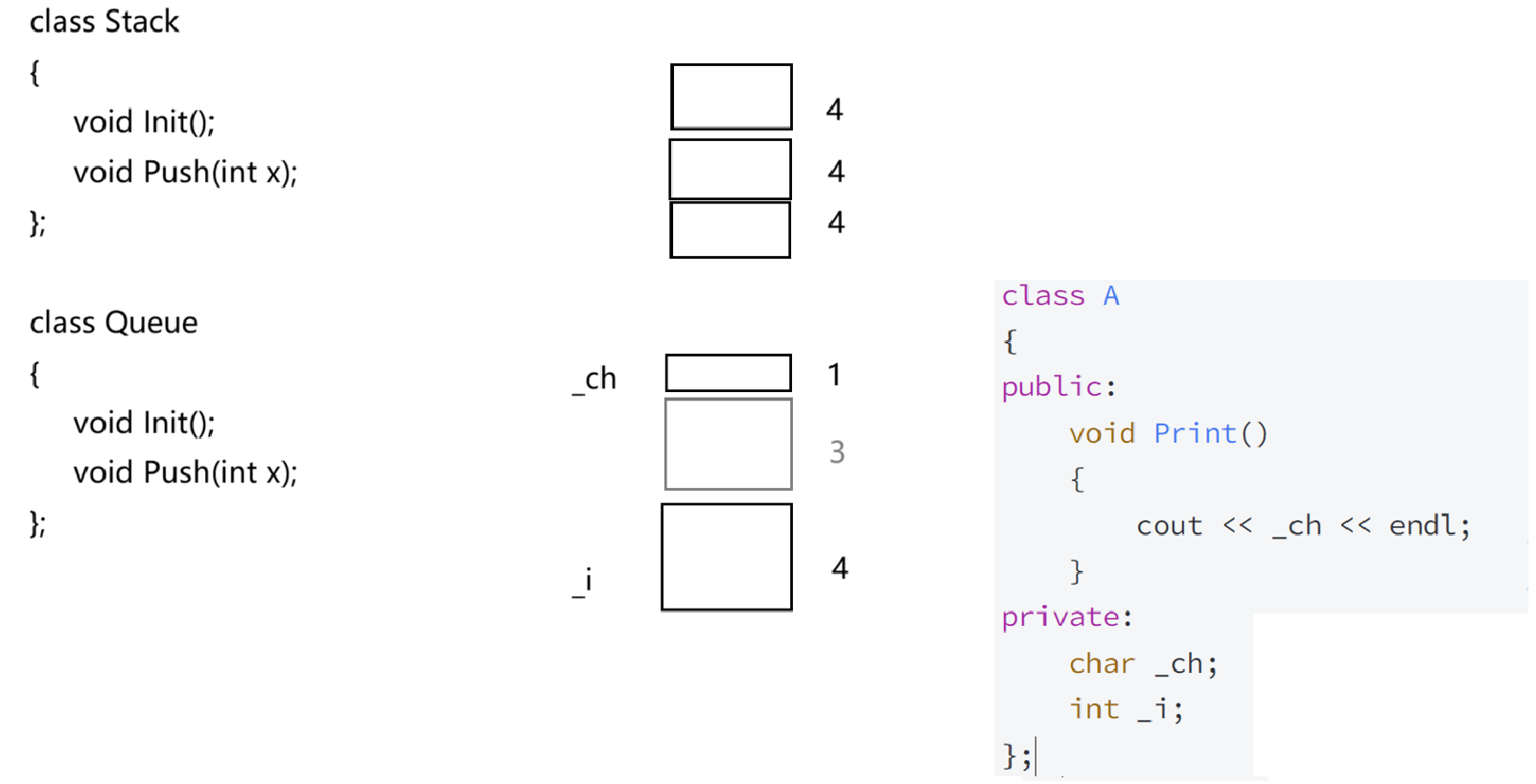
class Stack
{
public:
//u
void Init(int capacity = 4);
void Push(int x);
private:
//u
int* _a;
int _top;
int _capacity;
};
2、SeqList.cpp
cpp复制代码
#define _CRT_SECURE_NO_WARNINGS 1
#include"SeqList.h"
//void SLInit(SL* pls, int n)
//{
// pls->a = (int*)malloc(sizeof(int) * n);
// pls->size = 0;
// pls->capacity = n;
//}
void SLPushBack(SL* pls, int x)
{
//...
pls->a[pls->size++] = x;
}
int SLFind(SL* pls, int x, int i)
{
while (i < pls->size)
{
//...
}
return -1;
}
int& SLat(SL* pls, int i)
{
//...
return pls->a[i];
}
void SLModify(SL* pls, int i, int x)
{
//...
pls->a[i] = x;
}
void Stack::Init(int capacity)
{
_a = nullptr;//malloc
_top = 0;
_capacity = capacity;//区分形参和实参
}
void Stack::Push(int n)
{
//...
}
3、Test.cpp
cpp复制代码
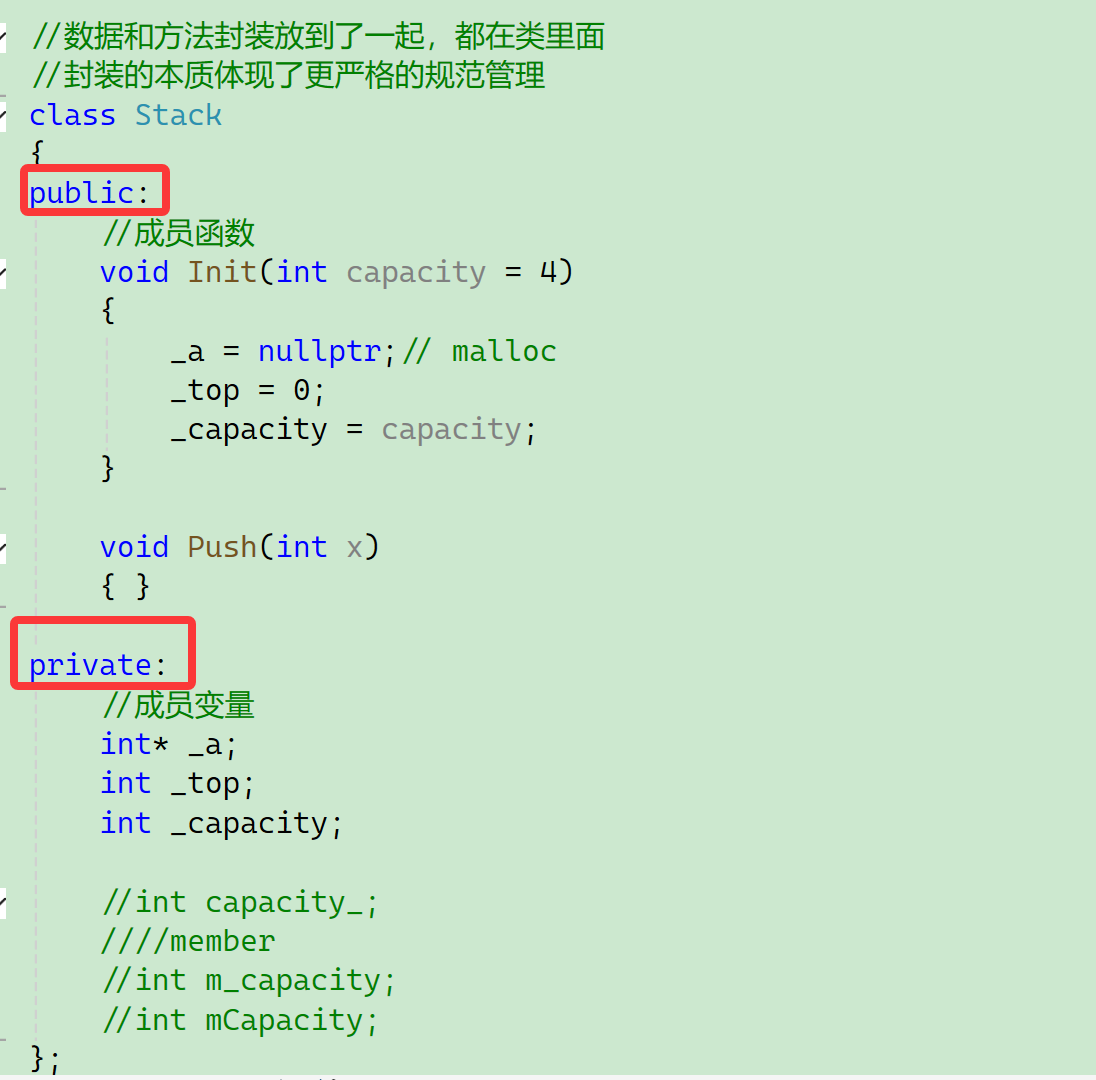
//数据和方法封装放到了一起,都在类里面
//封装的本质体现了更严格的规范管理
class Stack
{
public:
//成员函数
void Init(int capacity = 4)
{
_a = nullptr;// malloc
_top = 0;
_capacity = capacity;
}
void Push(int x)
{ }
private:
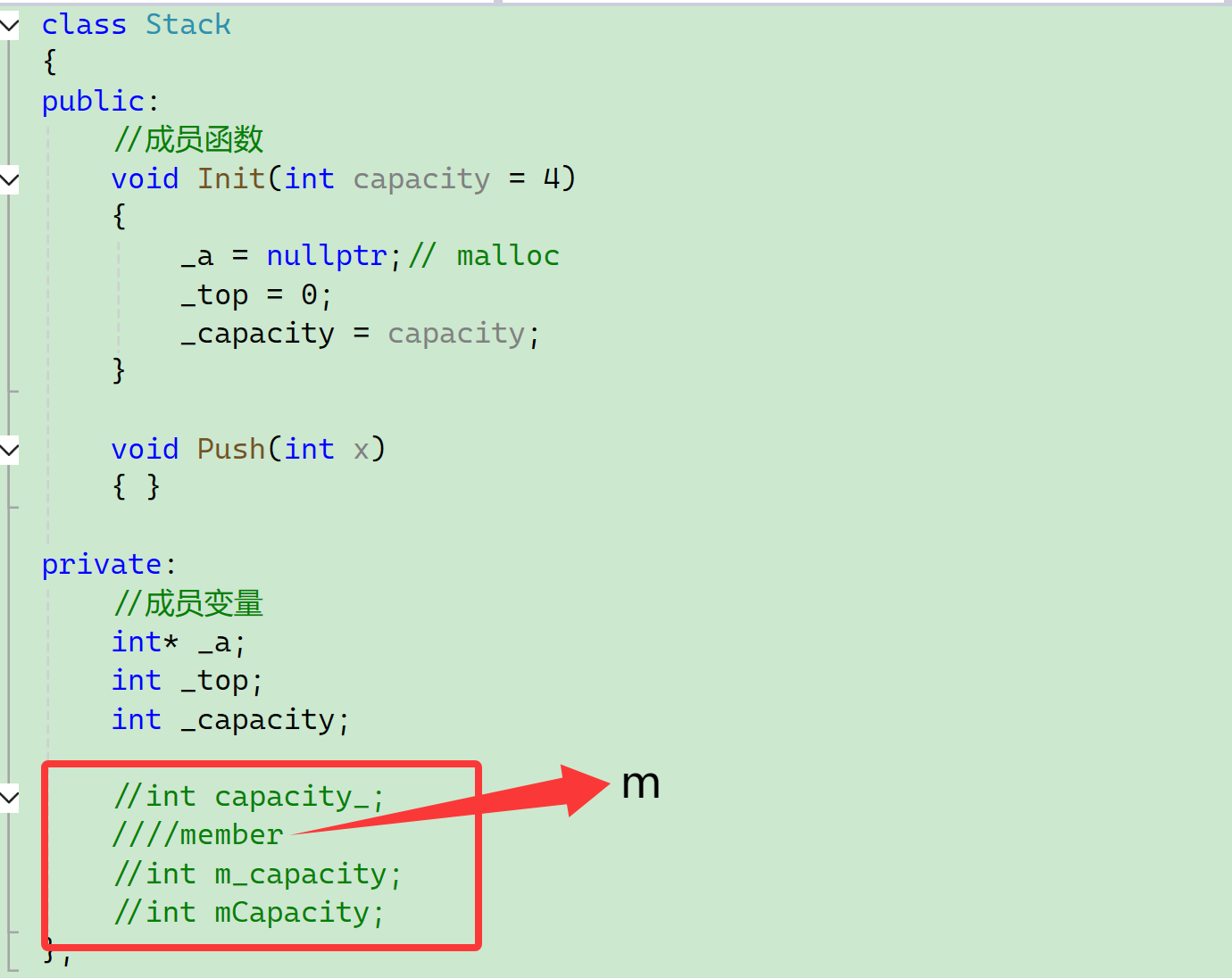
//成员变量
int* _a;
int _top;
int _capacity;
//int capacity_;
////member
//int m_capacity;
//int mCapacity;
};
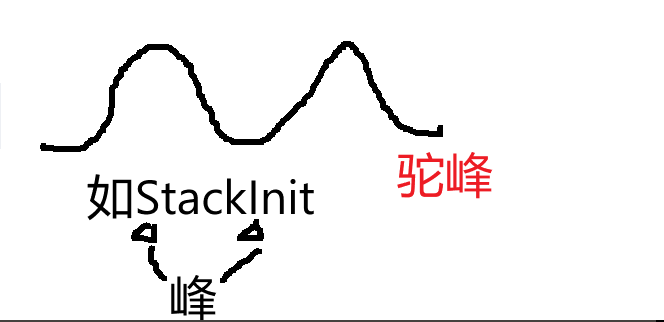
//驼峰法 StackInit 类型 函数, 单词首字母大写开头+单词首字母大写
// intCapacity 变量 单词首字母小写开头+单词首字母大写
// stack_init
// init_capacity
//兼容C的struct的写法
typedef struct A
{
void func()
{ }
int a1;
int a2;
}AA;
//升级成了类
struct B
{
void Init()
{ }
private:
int b1;
int b2;
};
struct ListNode
{
int val;
//struct ListNode* next;
ListNode* next;
};
int main()
{
struct A aa1;
AA aa2;
B bb1;
bb1.Init();
Stack s1;
s1.Init();
s1.Push(1);
s1.Push(2);
s1.Push(3);
//s1.top++;
return 0;
}
int main()
{
return 0;
}