目录
第二题
我们现在将推导一个给定观测值是引导样本一部分的概率。假设我们从n个观测值中获得一个 引导样本。
(a) 第一个引导观测值不是 原始样本中第j个观测值的概率是多少?请证明你的答案。
(b) 第二个引导观测值不是 原始样本中第j个观测值的概率是多少?
(c) 论证原始样本中第j个观测值不在 引导样本中的概率是(1 − 1/n)^n。
(d) 当n = 5时,第j个观测值在引导样本中的概率是多少?
(e) 当n = 100时,第j个观测值在引导样本中的概率是多少?
(f) 当n = 10,000时,第j个观测值在引导样本中的概率是多少?
回答:
(a) 第一个引导观测值不是原始样本中第j个观测值的概率: 每个观测值被选中的概率是1/n。因此,第j个观测值不被选中的概率是1 - 1/n。
(b) 第二个引导观测值不是原始样本中第j个观测值的概率: 由于每次选择都是独立的,第二次选择和第一次选择相同,因此概率也是1 - 1/n。


第三题
k折交叉验证的实现步骤:
- 划分数据集:将整个数据集随机分成k个等大小的子集(folds)。
- 训练与验证 :对于每个子集:
- 使用其中的k-1个子集作为训练集。
- 使用剩下的1个子集作为验证集。
- 训练模型并在验证集上进行评估,记录模型的评估结果(例如误差)。
- 重复:重复上述过程k次,每次选择不同的子集作为验证集。
- 计算平均性能:将所有k次验证结果的评估指标取平均值,作为模型的最终性能指标。
通过这种方式,可以有效利用数据进行模型评估和调优,减少过拟合的风险。
(b) k折交叉验证相对于其他方法的优点和缺点:
i. 相对于验证集方法:
- 优点 :
- 更稳定和可靠的性能估计:验证集方法仅使用一次划分,评估结果可能对数据划分方式非常敏感。而k折交叉验证通过多次划分,得到的评估结果更为稳定和可靠。
- 更充分利用数据:验证集方法将一部分数据作为验证集,导致训练数据减少。而k折交叉验证每次只用1/k的数据作为验证集,其余数据用于训练,因此更充分地利用了所有数据。
- 缺点 :
- 计算开销更大:k折交叉验证需要进行k次训练和验证,计算量是验证集方法的k倍。
- 实现复杂度较高:相较于验证集方法,k折交叉验证的实现稍微复杂一些。
第四题
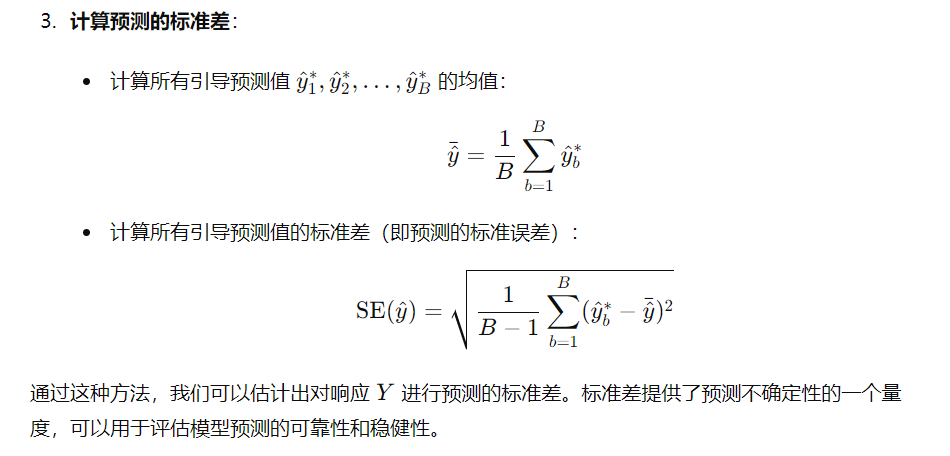
假设我们使用某种统计学习方法对特定的预测变量X进行响应Y的预测。请详细描述如何估计我们预测的标准差。
回答:
为了估计对响应 YYY 的预测的标准差,我们可以采用以下步骤:
-
使用训练集训练模型:使用现有的数据训练一个统计学习模型,得到预测模型 f^(X)\hat{f}(X)f^(X)。
-
获取多次预测:为了估计预测的标准差,可以采用重采样方法,例如引导法(bootstrap)或k折交叉验证(k-fold cross-validation)来获得多个预测值。