27含并行连结的网络GoogLeNet
python
import torch
from torch import nn
from torch.nn import functional as F
import liliPytorch as lp
import matplotlib.pyplot as plt
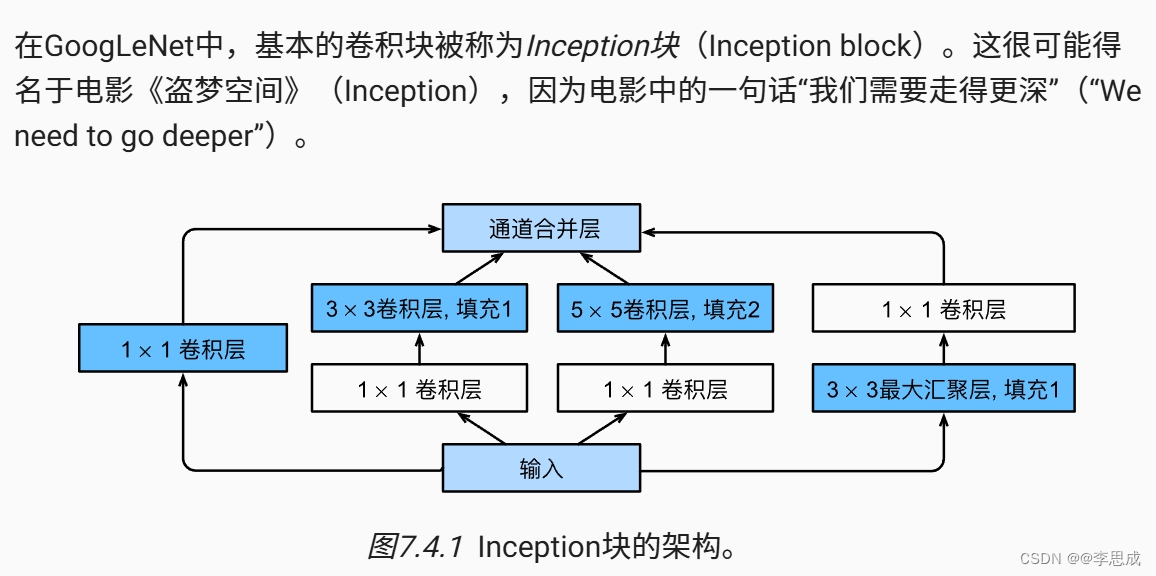
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super().__init__()
# super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
# 经过每条路径,并应用 ReLU 激活函数
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
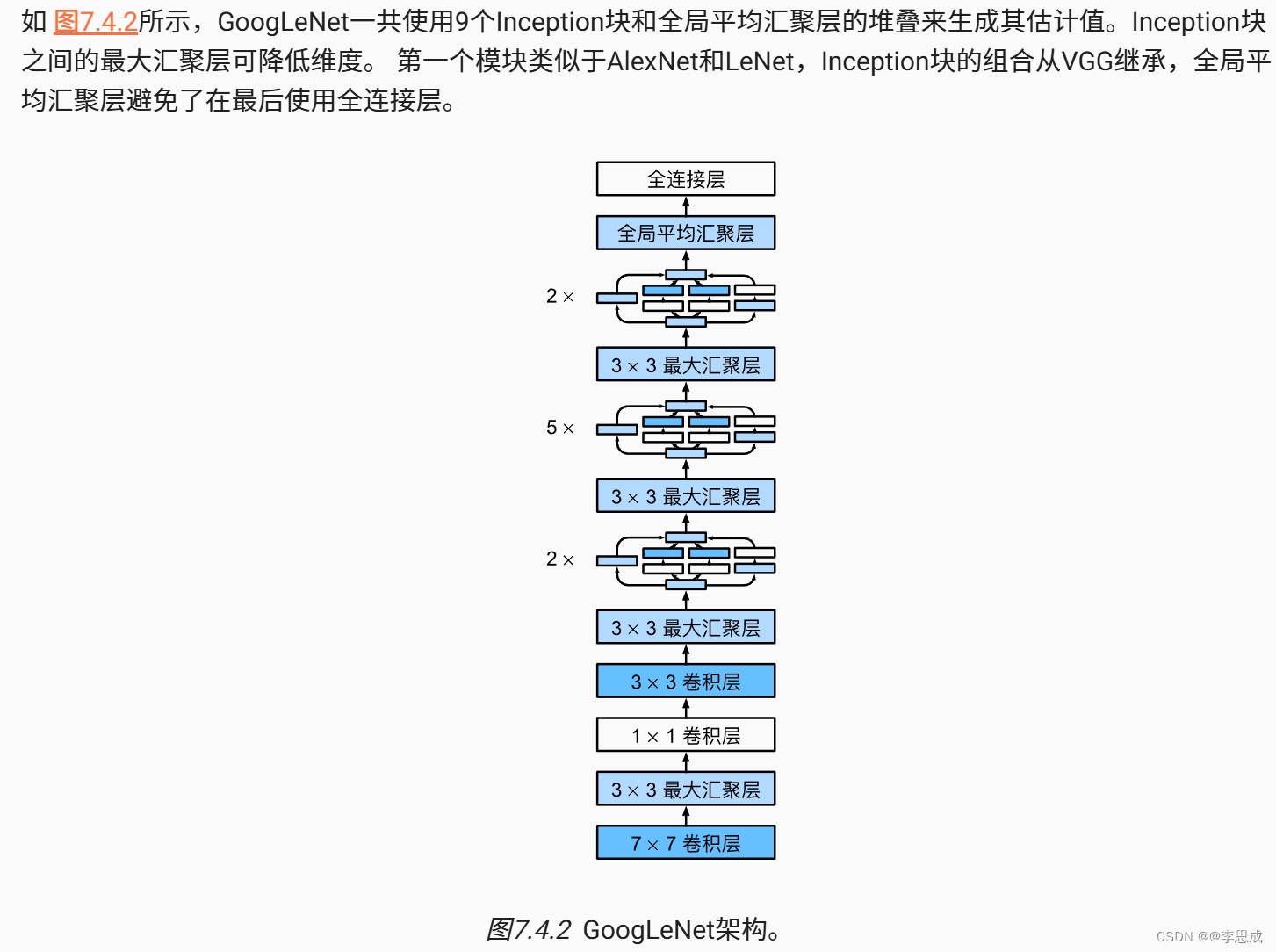
# 定义模型的各个模块
b1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), # 第一个卷积层
nn.ReLU(), # 激活函数
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 最大汇聚层
)
b2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=1), # 1x1卷积层
nn.ReLU(), # 激活函数
nn.Conv2d(64, 192, kernel_size=3, padding=1), # 3x3卷积层
nn.ReLU(), # 激活函数
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 最大汇聚层
)
b3 = nn.Sequential(
Inception(192, 64, (96, 128), (16, 32), 32), # 第一个Inception块
Inception(256, 128, (128, 192), (32, 96), 64), # 第二个Inception块
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 最大汇聚层
)
b4 = nn.Sequential(
Inception(480, 192, (96, 208), (16, 48), 64), # 第一个Inception块
Inception(512, 160, (112, 224), (24, 64), 64), # 第二个Inception块
Inception(512, 128, (128, 256), (24, 64), 64), # 第三个Inception块
Inception(512, 112, (144, 288), (32, 64), 64), # 第四个Inception块
Inception(528, 256, (160, 320), (32, 128), 128), # 第五个Inception块
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 最大汇聚层
)
b5 = nn.Sequential(
Inception(832, 256, (160, 320), (32, 128), 128), # 第一个Inception块
Inception(832, 384, (192, 384), (48, 128), 128), # 第二个Inception块
nn.AdaptiveAvgPool2d((1, 1)), # 自适应平均汇聚层
nn.Flatten() # 展平层
)
# 将所有模块串联成一个完整的模型
net = nn.Sequential(
b1, # 第一模块
b2, # 第二模块
b3, # 第三模块
b4, # 第四模块
b5, # 第五模块
nn.Linear(1024, 10) # 最后一层全连接层,输出10个类别
)
# 创建一个随机输入张量,并通过每一层,打印输出形状
X = torch.rand(size=(1, 1, 96, 96))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
# 训练参数
lr, num_epochs, batch_size = 0.1, 10, 128
# 加载数据集
train_iter, test_iter = lp.loda_data_fashion_mnist(batch_size, resize=96)
# 训练模型
lp.train_ch6(net, train_iter, test_iter, num_epochs, lr, lp.try_gpu())
# 显示训练过程中的图表
plt.show()
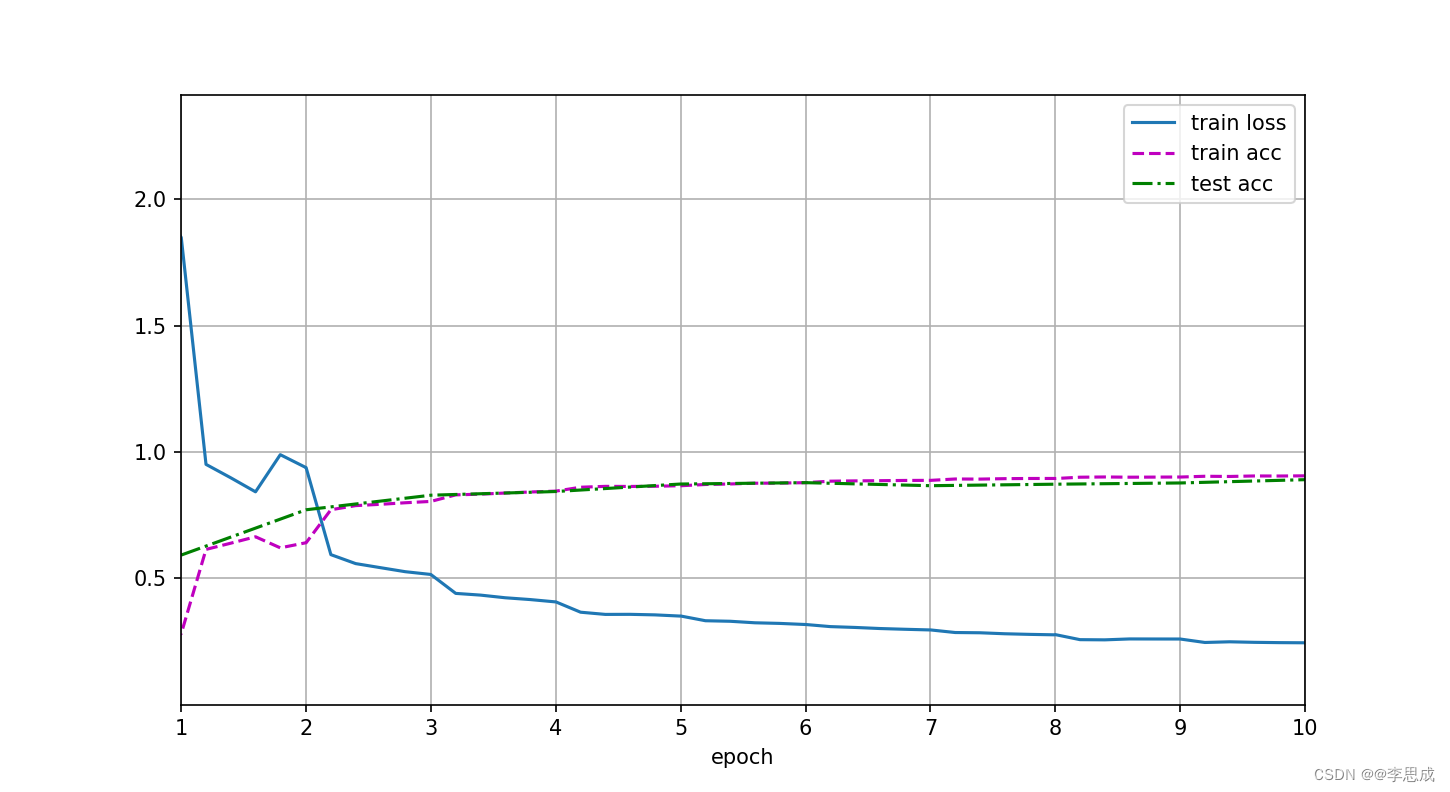
# 训练结果:
# 损失 0.254, 训练准确率 0.904, 测试准确率 0.866
# 1534.2 examples/sec on cuda:0
# loss 0.246, train acc 0.906, test acc 0.891
# 1492.9 examples/sec on cuda:0运行效果: