GaussDB架构介绍(四)从云原生关键技术架构&关键技术方案两方面对GaussDB云原生架构进行了解读,本篇将从关键技术方案的事务存储组件、SQL引擎组件、DCS组件、实时分析组件等方面继续介绍GaussDB云原生架构。
目录
[3、支持远程内存池, 内存独立扩展。](#3、支持远程内存池, 内存独立扩展。)
4、本地缓存远程页面地址,页面地址共享,全RDMA/UB单边读写。
[5、Lamport LSN](#5、Lamport LSN)
事务存储组件
云原生数据库支持透明多写,所有节点对等,每个计算节点都可以读写全部的数据页面,事务在本节点执行,没有分布式事务。每个计算节点都有Local buffer pool,采用Remote memory pool扩展计算节点的内存,在多个计算节点之间共享buffer地址,避免页面在多个计算节点之间传来传去。存储引擎采用Inplace update引擎,底层存储接口统一采用段页式存储方式。事务ID本节点分配,保证唯一性。事务提交时间戳统一分配,合并原来的CLOG和CSN LOG统一记录。存储层采用Log is data,把数据库存储引擎的持久化卸载到Page Store执行日志持久化,日志回放修改页面,创建检查点。
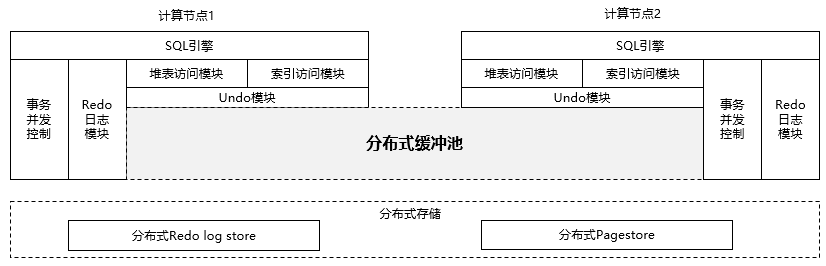
图1 分布式缓冲池示意图
在计算节点,分布式缓冲池位于数据访问层和分布式存储层的中间,所有的数据访问都要经过缓冲池。分布式缓冲池需要保证页面数据的一致性和页面查找访问的高效性,是云原生数据库实现透明多写,内存资源弹性的关键模块。具体设计如下:
1、本地内存和远程内存两级缓存
本地内存和远程内存的读写时延差别非常大(30~100ns 和 800ns~5us的区别), 哪些页面在本地缓存,哪些页面在远程缓存非常关键。同时还有一个重要的因素需要考虑,那就是页面是否在多个计算节点被读写,因此云原生数据库把页面分为三大类,一类是页面在多个计算节点被读写(Heap页面,FSM页面),适合存放在远程内存里,页面地址共享;一类是页面大概率被读,几乎不被修改或者极低概率被修改(索引的非叶子页面,系统表的页面)适合存放在本地内存;另外一类是页面只在固定的单节点被读写,(智能路由优化后索引的叶子节点页面),适合存放在本地内存。
理想的页面分布情况如下图所示:
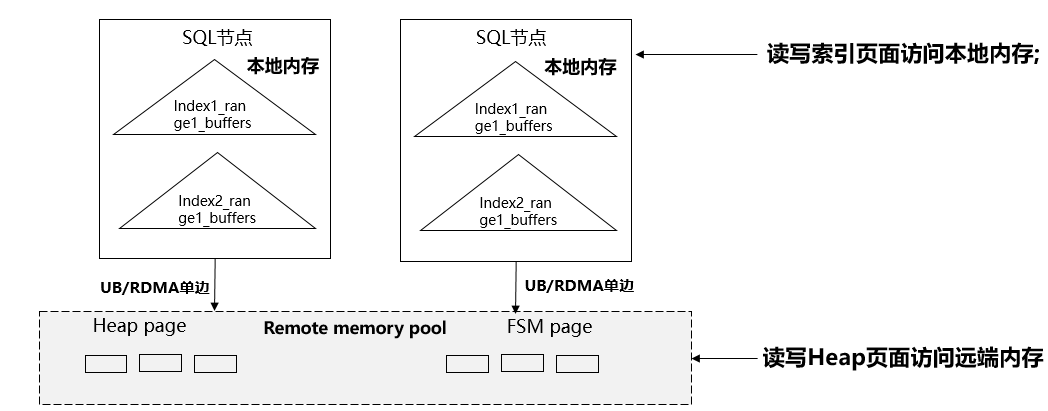
图2 理想页面分布示意图
2、页面查找机制
每个页面缓存对应一个元信息,称为page directory(PD),它描述了页面的最新版本在哪个节点,也就是page owner node(PON),页面是否是共享的远程页面地址,以及远程页面地址。PD 也是分布在各个计算节点上,每个计算节点管理一部分PD, 采用一致性Hash的方法管理PD。

图3 页面查找示意图
索引页面按照Range自动汇聚算法,根据SQL访问把相关页面汇聚到一个节点,提高索引访问的本地内存的亲和性。
索引的叶子节点本身就是从左到右按照索引key的大小顺序存放的,因此很容易根据索引的叶子节点自动划分Range,SQL优化器的路由模块按照Range路由就可以让索引页面按照Range汇聚到SQL节点的本地缓存里实现亲和性访问。针对多个索引的多个Range的亲和性场景,优先选择主键作为亲和性的Range路由。
3、支持远程内存池, 内存独立扩展。
云原生数据库在云上支持各种业务负载,CPU、MEM和Storage的配比很难一开始就配置合适,有的是计算密集型的业务,有的是内存密集型的业务,有的是存储容量大的业务。针对各类业务场景,云原生数据库需要提供精细的各种资源的独立扩展能力。支持远程内存池,实现了集群物理内存独立扩展。内存池是可选服务,也可以跟计算节点合部署。
4、本地缓存远程页面地址,页面地址共享,全RDMA/UB单边读写。
页面如果频繁在多个节点被读写,为了避免页面在多个节点之间传来传去,采用共享页面地址的方式,SQL节点Local buffer pool里缓存页面的远程地址,通过全单边读写远程页面。在设计上需要考虑读写页面的Latch问题以及写页面过程中故障的处理问题。对于exclusive latch采用lock bit和lock owner node的方式表示,对于share latch,lock bit和lock owner node的方式无法表示, 因为可以有很多发起者同时持有share latch。因此云原生在设计上采用lock-free无锁机制读取页面。
5、Lamport LSN
在云原生数据库多写的架构下,每个节点有独立的日志流,本地日志流的LSN是本地分配维护的,本地有序逻辑递增,页面在各个SQL节点之间分别被修改的情况下,需要保证在新节点上修改页面产生的日志LSN要比这个页面之前的日志LSN要大才可以,也就是说从多个节点修改过同一个页面,日志虽然在各个节点独立的日志流里,但是要维护修改页面的日志顺序LSN。Redo日志在多个SQL节点都存在,需要保证这些日志的LSN顺序,才可以保证日志回放的顺序正确性,因此采用Lamport LSN。这部分的详细设计请参照文档<< GaussDB Kernel TD V600R001C00 XLog日志系统设计说明书.docx>>。
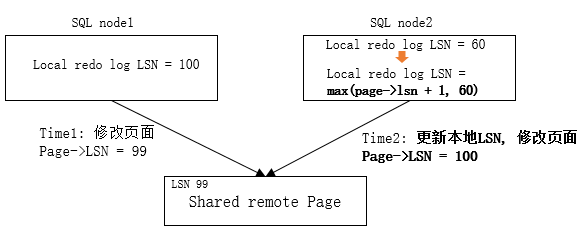
图4 页面Lamport LSN维护示意图
SQL引擎组件
云原生数据库SQL引擎继承原来openGauss的词法解析,语法解析,查询重写,查询优化和执行引擎的能力。由于云原生数据库是shared disk 架构,一个事务在一个节点上执行,所以不需要原来分布式根据分布式key进行数据分布,分布式执行和分布式2PC提交的能力。为了支持数据库粒度的异地多活,云原生数据库引入了CDB和ADB的概念,SQL引擎在访问表等对象的过程中,需要记录当前执行的数据库上下文信息,内存上下文根据CDB来分配和管理,并且需要把当前的CDB信息透传到存储引擎,把日志持久化到相应CDB的日志流中。
云原生支持SQL读写一致性路由,根据当前会话的数据一致性要求和CDB的主备把SQL路由到相应集群进行处理。云原生支持SQL数据亲和性路由,根据数据的访问亲和性对数据进行汇聚,SQL优化识别出数据分区所在节点后,把SQL路由到相应节点进行处理。
云原生长期演进要求数据和程序的解耦,在SQL引擎中实现系统表存储和解析的解耦,实现系统表的前向兼容。
DCS组件
云原生数据库支持DCS一是为了DCS能够支持持久化能力,二是构建一站式的云数据库服务能力。DCS原来是一个share nothing的分布式集群,有自己的通信管理,集群管理和客户端。在云原生数据库中,DCS是作为一个组件集成到整个服务中,主要提供字符串(String)、哈希(Hash)、列表(List)、集合结构(Set、SortedSet)等数据类型的直接存取,包括代理层实现消息收发解析,KV数据的基本读写,数据分片管理和数据存储等功能。通信和集群管理使用云原生的通信和集群管理。

图5 DCS方案示意图
表1 DCS主要模块
| 模块 | 功能描述 |
|---|---|
| 代理模块 | 依据GaussDB消息协议实现消息解析、消息封装等功能。代理在DCS服务端集成,不存在实际的代理节点。引入代理的主要目的是屏蔽客户端对服务端实现细节的感知。 |
| 数据管理 | 实现数据分片分布和管理,保障数据可靠性。通过跳表实现过期删除和对象回收,保障租户内存复用。同时实现双云同步功能。 |
| 存储模块 | 以分片数据为细粒度实现数据的内存存储、逻辑持久化、多版本备份等能力。 |
云原生DCS服务继承原来DCS内存KV数据的CRUD、路由管理、跨DC复制、逻辑持久化、过期删除、对象回收、数据核查等数据处理功能,需要调整新增的模块功能如下:
1、代理层
原来DCS客户端协议与Redis兼容,Redis客户端使用RESP(Redis序列化协议)与Redis服务器进行通信,RESP位于TCP之上,客户端和服务器是保持双工的连接。云原生客户端可同时支持SQL操作和KV操作,除了SQL操作的前后端消息协议,还需要考虑KV操作的通信协议。云原生数据库设计目标要求DCS的KV接口完全兼容,但不要求兼容redis原生客户端,所以在不和SQL操作通信协议冲突的前提下,DCS的通信协议继承原来的实现方式,对于冲突的部分,优先保证SQL的通信协议,调整DCS的通信协议实现。
2、数据管理
数据分片分布基于一致性hash算法,实现分片数据和计算节点的映射。数据分区还是基于经典的一致性hash算法,将(0~2^64-1)的地址空间划分为固定细粒度的分区,主键的hash值会映射到固定的分区中,数据内存存储通过DCS数据管理模块实现。计算节点通过模拟表形式将KV数据存放到存储引擎实现数据落盘。
3、DCS在云原生数据库中是shared disk架构,所有节点对等,在DCS初始化时,需要通过一致性hash计算分区管理的owner,在一个节点故障通知一致性视图调整时,需要选择一个节点接管故障节点的分区,并且通过数据库的存储引擎读取数据,恢复内存数据结构。
4、DCS提供GR地理复制能力,支持DCS数据进行跨DC数据备份,实现DC故障时业务的无损切换,实现DC容灾。一个源端集群对应多个备份集群,为保证集群能够跨DC通信,通过GR Link建立跨DC的链接,Link代表一个DC到另外一个DC的复制和备份关系的有向链接。用户通过配置好的GR同步备份或复制的规则,才能触发数据同步。LINK、RULE的操作接口在DCS内部实现,规则持久化到系统表或配置表。DC同步跨集群消息转发采用云原生数据库通信系统中跨集群通信服务处理。
实时分析组件
云原生数据库以OLTP为主,同时也支持基于OLTP数据的OLAP需求,如每日报表。在云原生数据库中,DBA可以选择为这部分表创建列存索引。创建完列存索引之后,执行器在做顺序扫描的时候,会自动选择列存索引进行数据的读取,实现快速扫描计算的能力。
云原生数据库以行存为基础,数据的增删改都先以行存的形式落到数据库中。事务、xlog等机制保障了行存的ACID特性。行存采用Inplace-update引擎,一个Tuple一旦被插入到表中,位置基本不会改变。每个Tuple可以用它的物理位置(文件页号+页内偏移,称为RowID),作为唯一标识。事务的多版本在回滚段中,可以根据RowID直接访问。云原生数据库中的列存索引方案如下图所示:列存是根据行存构建的一个read-only的副本,每次对行存的更新操作会在元数据区域(In Memory Delta Unit,IMDU)增加一条RowID记录。列存扫描的时候会查看元数据区域,确定哪些Tuple已经失效,再去行存中根据RowID读相应的数据。后台线程会周期性地更新列存,回收元数据。如果列存索引和更新操作不在同一台机器上,使用batch模式,即把一个事务中产生的所有失效信息,统一打包到一个RPC请求中,发送给列存索引所在的实例上,从而减少对OLTP请求的影响。行存的block为8KB,列存需要较多的数据量才能实现更好的压缩、向量化操作等优化。所以一个IMCU对应多个行存的block,目前暂定为1024个,这样一个1024个block称为一个Super Block。

图6 列存索引示意图
为了支持列存大小超过内存容量的场景,列存索引支持从内存中置换到磁盘上。但是列存本身在故障情况下并不能保证自身的一致性,故障重启之后列存需要根据行存的内容重新构建。所以这里的磁盘对于列存来说,是内存的延伸,用来缓存额外的数据。因为DU容量小,且经常被修改,所以可以常驻内存。
列存索引和行存完全是解耦开的。部署形态上,列存索引既可以与行存在一个实例中,节约物理资源;也可以与行存在不同的实例中,避免OLAP请求对OLTP请求产生影响。两种部署形态分别如下图所示:

图7 行存列存混合部署示意图

图8 行存列存分开部署示意图
PageStore组件
PageStore是一个分布式存储,对外提供SAL接口,SQL节点通过SAL接口进行日志和页面的持久化服务,PageStore对象间的映射关系如下图所示。
Page Cluster Manager Control Server(集群管理):页面集群管理控制服务负责整个存储节点的管理,VFS和StoreSpace的管理,以及Slice的分配和调度。
VFS:虚拟文件系统,每个租户可以创建一个VFS,集群管理按照VFS统计容量和IO等信息;
PG(Placement Group,放置组):多个存储节点组成一个PG,PG的多个存储节点满足反亲和性。集群管理在分配Slice的时候,按照PG进行分配。
Slice:数据存储的基本单元,Slice分配到具体的某个PG,分配到PG后,Slice就运行在PG下的多个节点上。每个Slice管理10G的数据量,10G的数据可能来自多个文件的一段连续页面。Slice逻辑上主要实现SQL节点页面的持久化和快速检索。Slice的元数据采用Btree管理,多个节点的Slice副本通过Raft机制提供数据的可靠性。每个Slice是数据回放的基本单元,实现独立的快照和检查点。Slice存储管理如下图所示。
存储节点:每个存储节点上运行一个PageStore进程,PageStore进程会管理多个Slice。PageStore进程内的所有Slice共享BufferPool、ThreadPool、通讯组件、消息分发和PAL等模块功能。多个Slice共享PageStore进程的CPU资源和内存。
文件:抽象的存储,为Slice存储数据,Slice会使用多个文件来存储数据。
PAL:持久化层,用于对Slice的文件进行持久化,下面可以对接LocalFS、Plog、Lun等。图中红色虚线框为PageStore提供的本地盘持久化方案。

图9 PageStore对象关系示意图

图10 Slice存储管理示意图
备份恢复组件
备份和恢复PITR主要是为了应对人为失误、硬件故障和自然灾害等。云原生数据库默认支持一级备份,一级备份是分布式存储Page Store基于append only实现的快照功能,快照数据保存在本集群,用户可以配置开始一级备份的时间段、频率以及保留时间,由OM_Server根据集群的负载等数据生成备份计划。一级备份等于是数据页的备份,为了实现PITR,在开启一级备份后,会默认开启日志归档,通过快照数据+日志实现快速PITR。
用户可以设置开启二级备份,一级备份数据保存在本集群,会占用用户生产集群的空间且全闪环境下费用较高,同时为了提高备份数据的可靠性,云原生数据库提供二级备份将备份数据及日志保存在OBS等远端存储上。当一级备份的保留时间过期时,云原生数据库会自动将其转储为二级备份,转储成功后自动删除一级备份的快照。同样用户可以设置二级备份的保留时间,二级备份保留时间过期时会自动将远端存储备份删除。
在恢复时,由于云原生数据库一个页面可能涉及多个日志流,需要对多个日志流进行扫描,对日志进行合并恢复。在扫描日志阶段可以根据恢复配置文件配置的恢复点确定恢复的位置,从而在正式恢复时恢复到这个时间点即可。
安全
云原生数据库是一个分布式系统,各个服务之间,服务与外部应用和外部用户之间,服务与内部应用和内部用户之间主要通过通信进行交互,它们的数据流图如下图所示。

图11 安全威胁分析示意图
从图中可以看出,云原生主要包括三个通信平面,OM_Monitor,OM_Agent,OM_Server组成的管理平面(操作维护),GaussDB Master Server和DB Cluster Resource Schedule Server组成的控制平面。GaussDB Server,DCS Server,Memory Server,Message Server,Page Server,Page Cluster Manager Control Server组成的用户平面。
云原生系统外部交互主要有三类接口:
第一类是GaussDB Server,DCS Server提供的业务访问接口,这个接口是外部接口。
第二类是OM_Server提供的操作维护接口,这个接口对接公有云的维护后台。
第三类是Message Server提供的跨区域集群的消息通信接口,这个接口虽然是内部接口,但通信网络不在内部网络。
云原生数据库是一个池化的共享资源系统,不同租户的运行环境通过进程隔离,租户的存储通过VFS进行隔离。为了保证租户数据不泄露,不发生篡改,在控制平面需要对租户身份进行签名认证,租户资源调度信息的传递需要防止仿冒和篡改。在用户平面,不同租户的数据使用不同的秘钥进行加密,对于远程内存操作的RDMA rkey进行随机化,其他安全继承原来数据库的能力,包括用户管理、权限管理和审计。在维护平面,对接入的访问进行认证,对进行的操作进行审计。
- END -