下载MongoDB数据库
首先,需要下载MongoDB数据库,下载的话比较简单,直接去官网找到想要的版本下载即可,具体安装过程可以看这里。
pycharm下载pymongo库
python
pip install pymongo然后在在python程序中我们可以这样连接MongoDB数据库:
python
import pymongo
#指定数据库与表
# client = pymongo.MongoClient(host='127.0.0.1', port=27017)
# connect = client['table']
client = pymongo.MongoClient(host='127.0.0.1', port=27017)
connect = client['table']['table_info']
# 插入一条数据
info = {'name': 'python', 'age': 18}
result = connect.insert_one(info)
print(result)
# 查询数据
res = connect.find()
print(res)
# 插入多条数据
info_1 = {'name': 'python', 'age': 18}
info_2 = {'name': 'spider', 'age': 18}
result = connect.insert_many([info_1, info_2])
print(result)
res = connect.find()
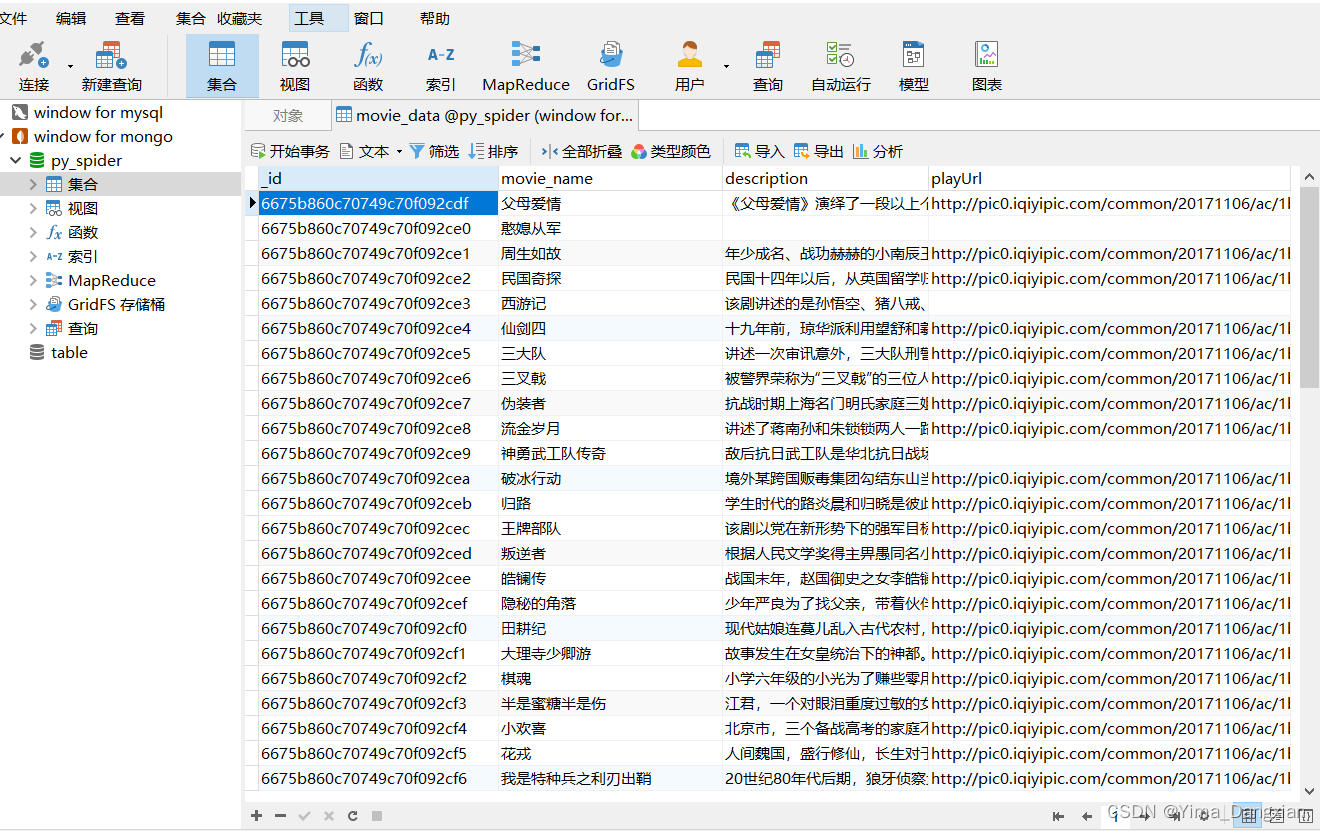
print(list(res))了解pymongo的常用语法后,我们来练习爬取爱奇艺的视频数据信息:标题、播放地址、简介并存入MongoDB数据库。
目标地址:https://list.iqiyi.com/www/2/15-------------11-1-1-iqiyi--.html?s_source=PCW_SC
可以先试试,再来看下面的代码:
python
# -*- coding: utf-8 -*-
# @Time: 2024/06/22 0:05
# @Author: 马再炜
# @File: 爬取爱奇艺存入MongoDB.py
import requests
import pymongo
import time
# 爬取爱奇艺的视频数据信息:标题、播放地址、简介并存入MongoDB数据库。
class AiQiYi:
url = "https://pcw-api.iqiyi.com/search/recommend/list"
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36"
}
self.params = {
"channel_id": "2",
"data_type": "1",
"mode": "11",
"page_id": "2",
"ret_num": "48",
"session": "31dd983cf8e6ca3c75b4faaa17d88eac",
"three_category_id": "15;must"
}
def require_info(self):
response = requests.get(AiQiYi.url, headers=self.headers, params=self.params).json()
# print(response["data"]["list"])
return response["data"]["list"]
def insert_in_mongo(self):
insertLists = list()
client = pymongo.MongoClient(host='127.0.0.1', port=27017)
connect = client['py_spider']['movie_data']
movieLists = self.require_info()
# print(movieLists)
for movie in movieLists:
insertTemp = dict()
insertTemp["movie_name"] = movie["name"]
insertTemp["description"] = movie["description"]
insertTemp["playUrl"] = movie["payMarkUrl"]
# insertLists.append({
# "movie_name": movie["name"], "description": movie["description"], "playUrl": movie["payMarkUrl"]
# })
insertLists.append(insertTemp)
# print(insertLists)
connect.insert_many(insertLists)
# time.sleep(1)
print('插入完成!')
def main(self):
self.insert_in_mongo()
if __name__ == '__main__':
aiqiyi = AiQiYi()
aiqiyi.main()最终结果如图: