上一次我们使用pytesseract.image_to_boxes来检测字符,今天我们使用pytesseract.image_to_data来检测文本并显示
实战教程
和上一次一样,添加opencv-python和pytesseract库
首先我们先来了解一下pytesseract.image_to_data
**
pytesseract.image_to_data(img)**是一个 pytesseract 库提供的函数,用于检测图像中的文本,并返回详细的文本框、文本内容及其位置信息。这个函数会返回一个包含每个检测到的文本块信息的字典列表。每个字典包含以下信息:
level: 检测级别(如字块、段落等)page_num: 页码block_num: 块编号par_num: 段落编号line_num: 行号word_num: 单词编号left: 文本框左边缘的 x 坐标top: 文本框顶部的 y 坐标width: 文本框的宽度height: 文本框的高度conf: 文本识别的置信度text: 检测到的文本内容
接一下我们使用代码打印一下pytesseract.image_to_data
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
# 读取图像
img = cv2.imread('3.jpg')
# 将图像从 BGR 格式转换为 RGB 格式(因为 pytesseract 使用 RGB 格式)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
himg, wimg, _ = img.shape
data = pytesseract.image_to_data(img)
print(data)
# 显示带有文本框和识别结果的图像
cv2.imshow( 'result', img)
# 等待按键输入来关闭窗口
cv2.waitKey(0)
# 关闭所有打开的窗口
cv2.destroyAllWindows()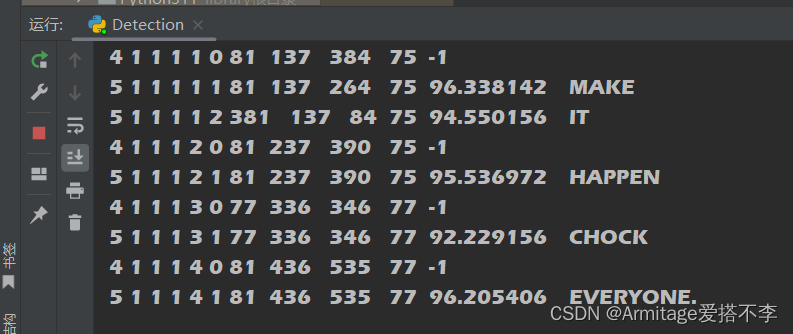
运行后我们得到这一串,按我刚才介绍的 pytesseract.image_to_data可知各个数字的含义,大家可以对照着看一下
接下来我们使用for x, b in enumerate(data.splitlines()):来遍历并枚举文本数据中的每一行
for x,b in enumerate(data.splitlines()):
if x!=0:
b = b.split()
print(b)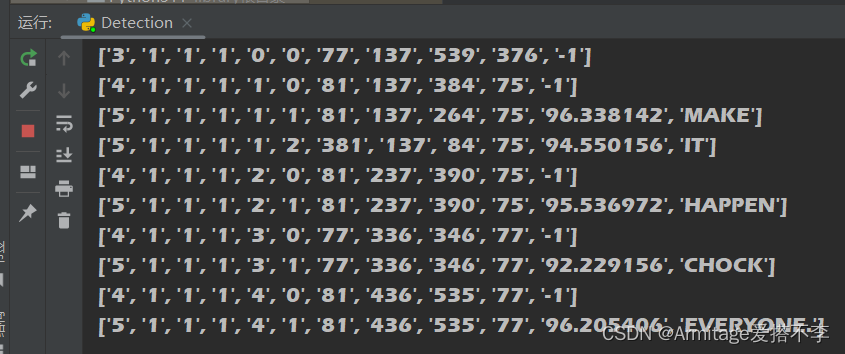
这样就将坐标和文本分离出来了
'5' '1' '1' '1' '4' '1' '81' '436' '535' '77' '96.205406' 'EVERYONE.'
从左往右为层级 、页码、块编号、段落编号、 行号、单词编号、文本框左边缘的 x 坐标、文本框顶部的 y 坐标、文本框的宽度、文本框的高度、文本识别的置信度、检测到的文本内容
接下来我们采用cv2的画矩形来画框,在这里我又发现 pytesseract.image_to_data 的原点和opencv的原点又是同一个原点了,和之前的pytesseract.image_to_boxes不同
 这样我们就可以写出代码
这样我们就可以写出代码
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
# 读取图像
img = cv2.imread('3.jpg')
# 将图像从 BGR 格式转换为 RGB 格式(因为 pytesseract 使用 RGB 格式)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
himg, wimg, _ = img.shape
data = pytesseract.image_to_data(img)
print(data)
for x,b in enumerate(data.splitlines()):
if x!=0:
b = b.split()
print(b)
if (len(b)==12):
x,y,w,h = int(b[6]),int(b[7]),int(b[8]),int(b[9])
cv2.rectangle(img,(x,y),(w+x,h+y),(0,0,255),3)
cv2.putText(img,b[11],(x+20,y-5),cv2.FONT_HERSHEY_COMPLEX,1,(50,50,255),2)
# 显示带有文本框和识别结果的图像
cv2.imshow( 'result', img)
# 等待按键输入来关闭窗口
cv2.waitKey(0)
# 关闭所有打开的窗口
cv2.destroyAllWindows()这里我们使用判断每一行是否有12个数据来筛选出我们需要的文本那一行
这样就完成了,我们看一下效果

我们发现文本被正确框出和显示出来 。
有兴趣的可以关注一下,近期一直更新,谢谢