研究方向:Image Captioning
1. 论文介绍
本文提出了一种基于检索的对象与关系提示用于图片标题生成(RORPCap),以最短的训练时间达到了与基于检测器与图卷积网络(GCN)的模型相当的性能指标。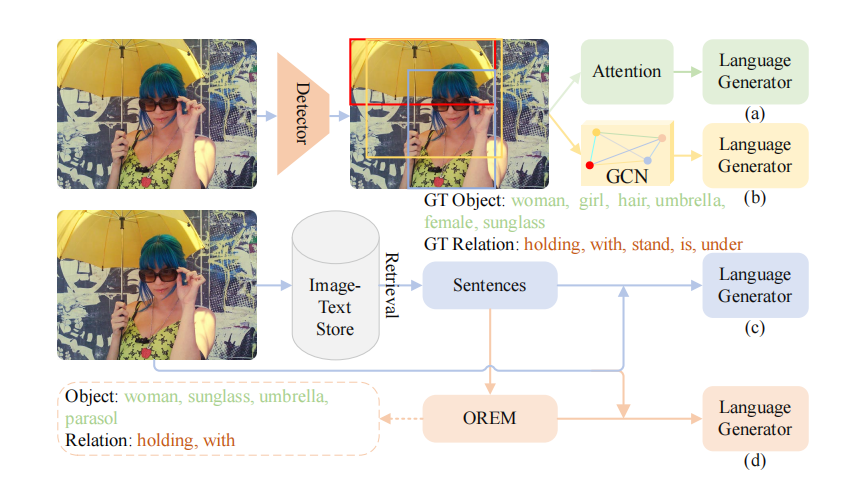
RORPCap利用从OREM(对象和关系提取模型)获得的关于图像的对象和关系词,并将这些词填入模板中,然后使用GPT-2的分词器将其转换为提示嵌入。为了弥合视觉和文本模态之间的差距,使用基于Mamba构建的映射网络将CLIP提取的图像嵌入映射成视觉-文本嵌入。接下来,将提示嵌入和视觉-文本嵌入连接起来形成一个前缀。在训练期间,前缀与真实描述(GT)嵌入连接在一起,然后输入到GPT-2中,得到最终描述。
2. 方法介绍
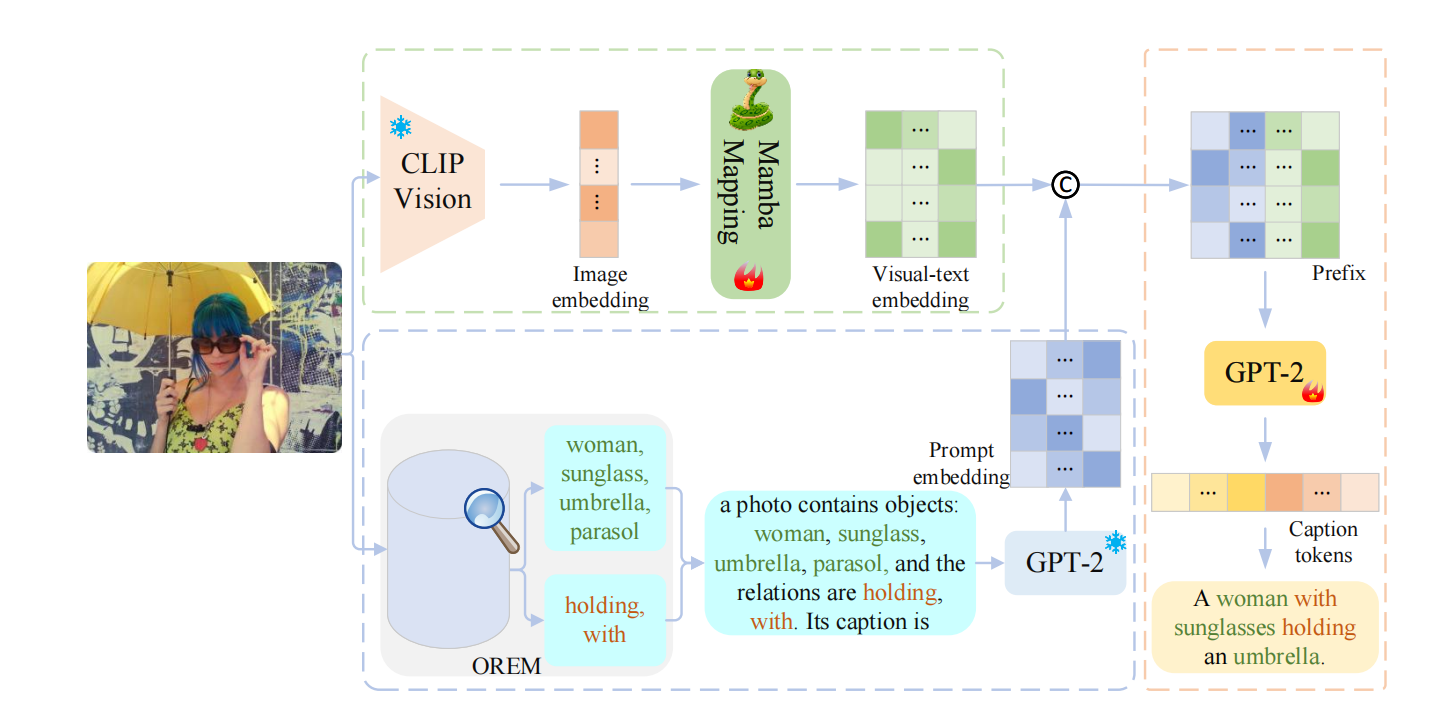
2.1 对象和关系提取模型
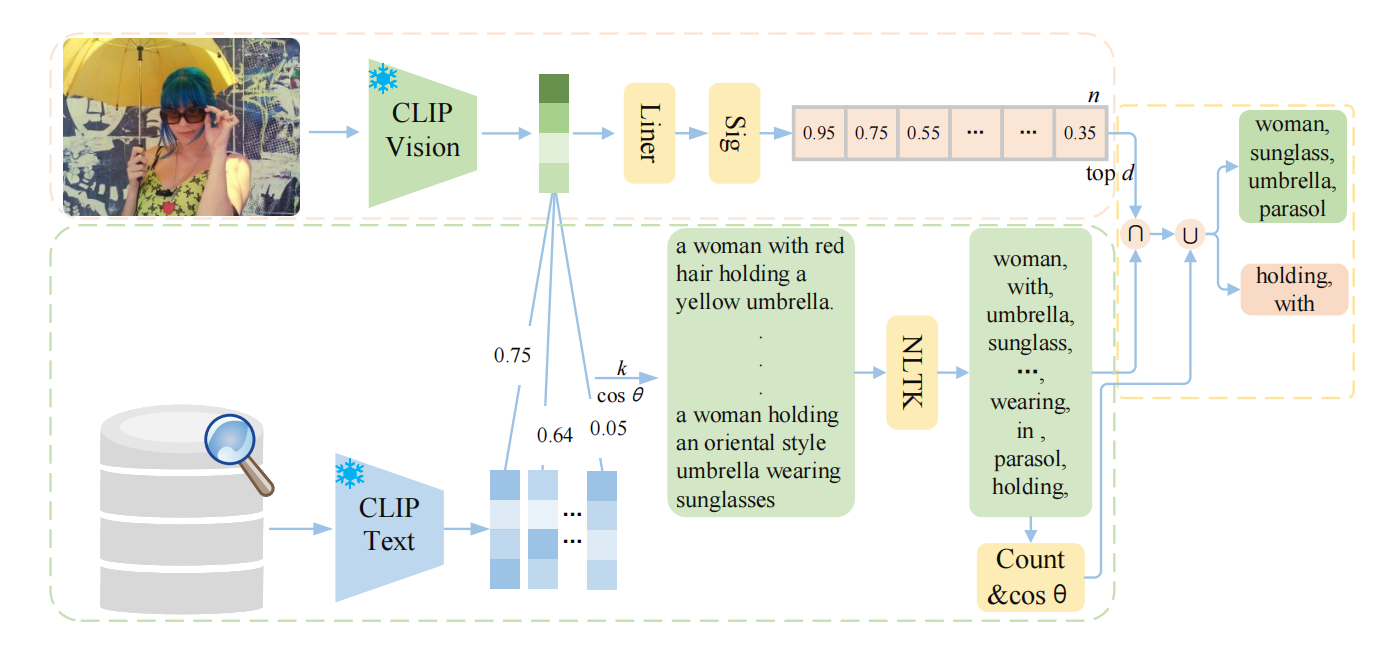
直接将整个句子作为提示可能会引入冗余信息。为解决这个问题,如上图,我们在OREM中处理检索到的句子并从中提取重要信息。
对输入图像和数据库
使用CLIP的视觉(CLIP-ViT-B/32)和文本编码器得到特征向量,然后基于余弦相似度使用最近邻搜索从数据存储(不包括ground truth)中检索k个最相似的句子,公式如下:
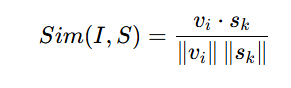
使用一个线性层和一个激活层将图像特征映射到n个高频词汇,并获得相应的分数。然后,我们提取分数大于s的前d个词汇,形成集合。我们使用NLTK(自然语言处理工具包,用于从检索到的句子中提取特定词性的词汇)来标记检索到的
个句子中的词性。为了避免来自多余信息的干扰,只提取对象和关系的词语,形成词集
作为语义线索。
取集合和
的交集,得到词集
,这些词语可能无法提供足够的文本概念,因此还结合词频和相似度统计作为补充。
补充: 在词性标注后对对象词和关系词进行频率分析,选择对象词频大于阈值且关系词频大于阈值
的词语。对于对象,我们还计算与输入图像中对象的相似度,以提高选词的准确性。最终的对象词集合表示为
,关系词集合表示为
。将它们填入固定提示模板中。
2.2 映射网络
仅使用图像中对象和对象中的关系词汇不足以传达其主要信息。还需要考虑这些细节之间的上下文关系,如颜色、形状、大小和位置,确保描述是合乎逻辑且易于阅读的。
选择Mamba模型作为连接视觉领域和文本领域的桥梁,用于处理从CLIP视觉编码器获得的图像嵌入。
2.3 语言生成器
生成描述所需的语义信息被封装在前缀中,使用 GPT-2(小型版)作为语言模型,利用前缀作为先验条件来预测下一个标记生成文本描述。