(2024)豆瓣电影TOP250爬虫详细讲解和代码
爬虫目的
获取 https://movie.douban.com/top250 电影列表的所有电影的属性。并存储起来。说起来很简单就两步。
- 第一步爬取数据
- 第二步存储
爬虫思路
总体流程图
由于是分页的,要先观察分页的规律,如下很容易知道每一页的规律。
- 第一页:https://movie.douban.com/top250?start=0\&filter=
- 第二页:https://movie.douban.com/top250?start=25\&filter=

代码思路
- 函数
getAllPageUrl:生成分页链接列表 - 函数
getMoiveListByUrl:根据某一页的分页链接,输出电影属性
函数:getAllPageUrl
python
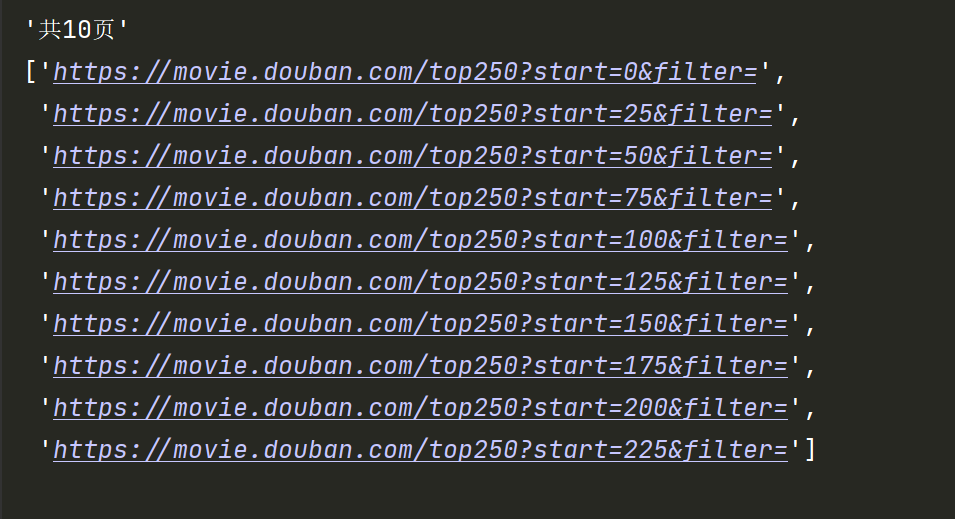
def getAllPageUrl():
"""
通过观察规律,生成所有分页的链接list
:return:
"""
list = []
for i in range(10):
url = f'https://movie.douban.com/top250?start={i*25}&filter='
list.append(url)
# print(url)
return list测试代码
python
if __name__ == "__main__":
urlList = getAllPageUrl()
pprint(len(urlList))
pprint(urlList)输出结果
可以一一校验链接是否有效,准确
函数:getMoiveListByUrl
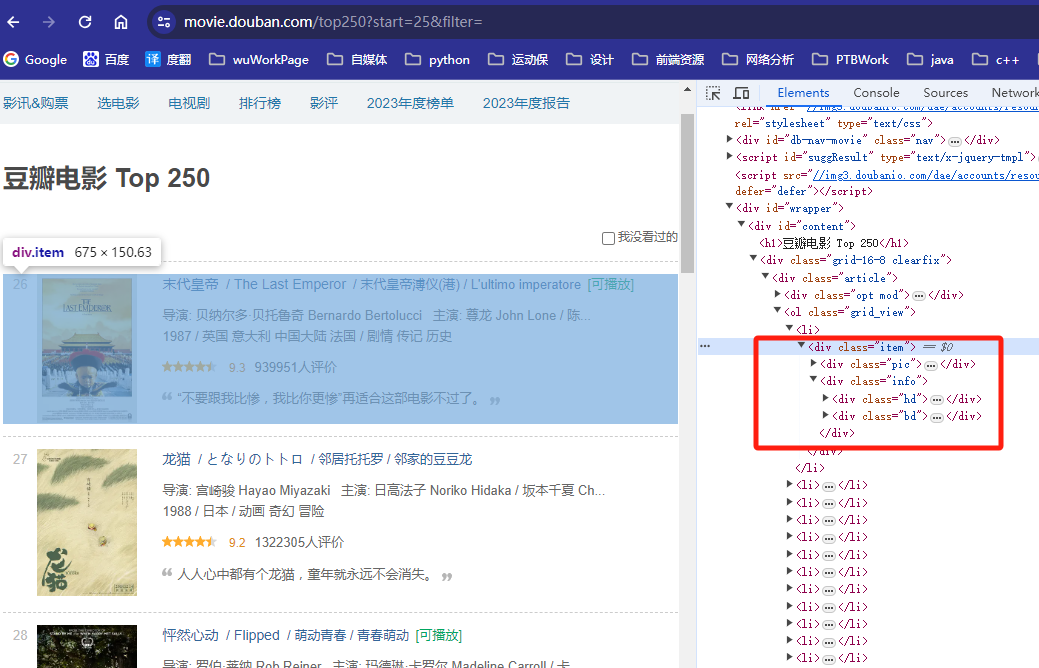
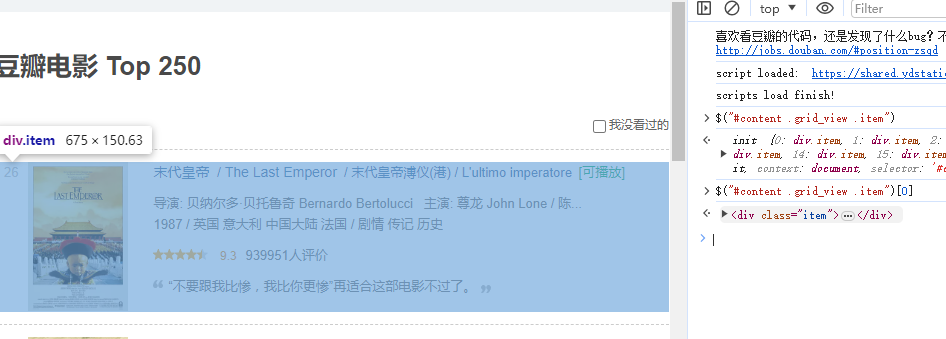
分析dom
js
//juery获取一部电影的dom
$("#content .grid_view .item")[0]OK,经过分析,我们找到了,使用jquery 获取电影dom的方式,只需要经过两步就能拿到电影列表了。
- 第一步:获取电影列表dom :
$("#content .grid_view .item") - 第二步:处理单个电影dom,拿到信息。
代码
python
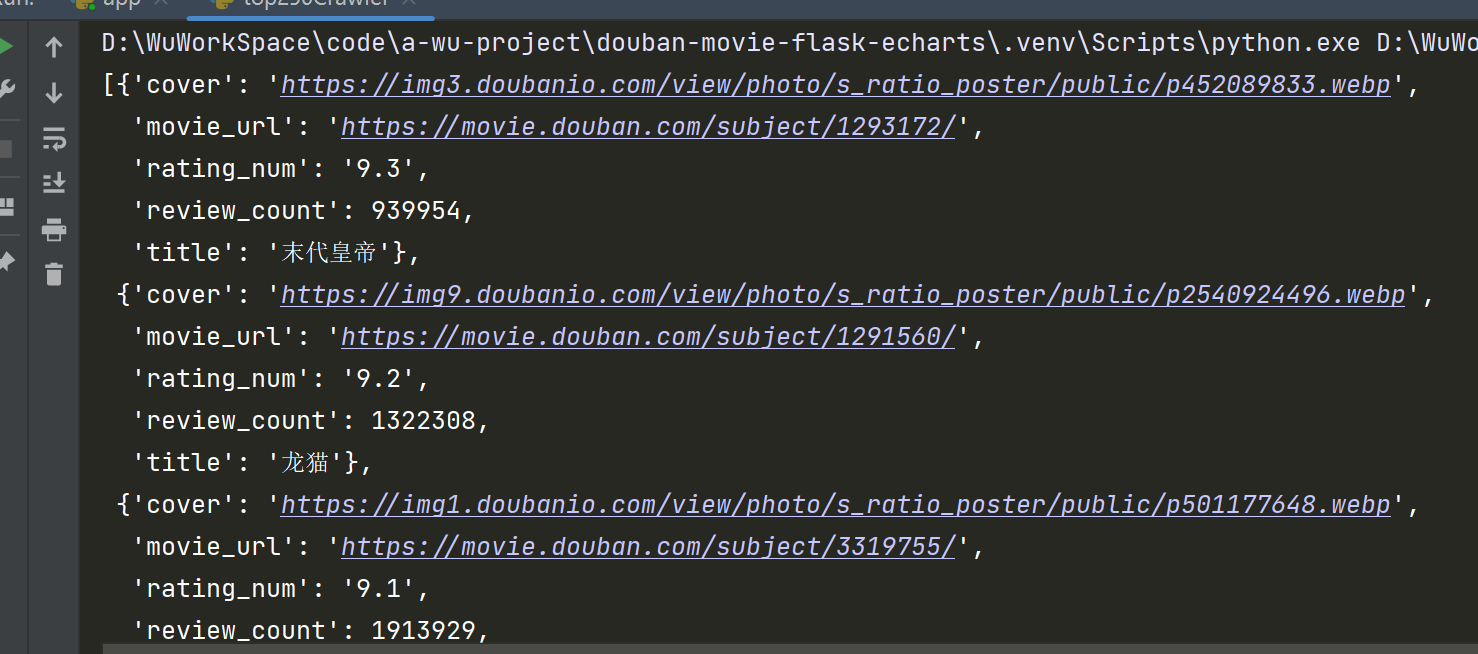
def getMoiveListByUrl(url):
"""
由一个分页链接开始,通dom节点的形式 + 数据处理(正则处理、字符处理、类型转换等), 获取电影信息
:return: list: 包含每部电影详细信息的字典组成的列表。
"""
# 定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
# 其他需要的请求头...
}
movieList = []
# 发送 GET 请求并获取响应内容
response = requests.get(url, headers=headers)
if response.status_code == 200:
#todo pyquery 解析dom,经过循环,数据处理(正则处理、字符处理、类型转换等),得到正确的电影属性信息
doc = pq(response.text)
movie_list_doc = doc("#content .grid_view .item")
for item in movie_list_doc.items():
item_dict = {} #存储单个电影对象的字典
cover = item('.pic img').attr('src')
movie_url = item('.pic a').attr('href')
title = item('.info .hd .title:first').text()
review_count_text = item('.info .bd .star span:contains("人评价")').text()
rating_num = item('.info .bd .star .rating_num').text()
review_count = int(review_count_text.replace("人评价", ""))
item_dict['title'] = title
item_dict['cover'] = cover
item_dict['review_count'] = review_count
item_dict['rating_num'] = rating_num
item_dict['movie_url'] = movie_url
# print(title)
movieList.append(item_dict)
return movieList
else :
return movieList测试代码
python
if __name__ == "__main__":
pageUrl02 = 'https://movie.douban.com/top250?start=25&filter='
movieList = getMoiveListByUrl(pageUrl02)
pprint(movieList)输出结果
可以一一校验链接是否有效,准确