帕金森病(Parkinson's disease, PD)是一种使人衰弱的神经退行性疾病,它需要进行精确和早期的诊断,以便为患者提供有效的治疗和护理。这种疾病是由James Parkinson在1817年首次确定的,其特征是多巴胺生成神经元的退化。多巴胺的不足导致了一系列症状,包括静止性震颤、肌肉僵硬、运动迟缓(姿势不稳定)、以及其他重要特征,如睡眠障碍、心律失常、便秘和语音变化,这些都是帕金森病的关键指标。
帕金森病的准确及时诊断对于有效管理症状和适当的治疗至关重要,因为错误或延迟的诊断可能会给患者带来巨大的身体和经济成本。相反,一个精确的诊断可以防止不必要的干预措施,并减少整体的医疗开支。因此,帕金森病诊断领域的研究人员和医疗专业人员正在积极寻找新的解决方案,这些方案提供高诊断准确性和最优的效率。
目前关于帕金森病诊断的研究大致可以分为以下三个主要类别:
- 第一类是基于临床症状和实验室测试来诊断PD,例如单光子发射计算机断层扫描(SPECT)测量和基于RNA的方法。然而,这些医学测试可能成本高昂且不易获得。此外,这些测试的分析和解释通常需要专业知识,引入了结果解释中可能出现人为错误的可能性。
- 第二类侧重于专家对受影响个体展示的身体状况进行检查。然而,专家的可用性可能受限,并且人为错误仍然是一个因素。
- 第三类涉及利用人工智能(AI)技术来分析症状并协助诊断。已经探索了各种方法,包括应用Relief技术来分析三维SPECT图像,以及使用卷积神经网络对脑电图(EEG)图像进行分类。然而,这些方法通常需要昂贵的设备来进行图像记录和准备。
研究表明,89%的帕金森病患者经历了语音障碍,其特征是表达不清、声音刺耳和气喘,以及音调单一。因此,最近基于AI的研究已经集中在将语音分析作为诊断帕金森病的一种手段,前面介绍的《PPINtonus (深度学习音调分析)帕金森病早期检测系统》也属于这个范畴。
ESN在语音识别以及在诊断各种疾病(如乳腺癌、预测I型糖尿病的血糖浓度和检测口腔癌)中具有多种能力,但在帕金森病诊断的语音分析背景下,ESN的使用,特别是与特征缩减结合使用,尚未得到广泛探索。++++本文提出一种诊断模型,能够在保证高准确率的同时,最小化假阴性率(即漏诊率),++++ ++++核心思想就是++++ ++++利用回声状态网络 (ESN) 和特征选择技术,从语音特征中提取信息,实现 PD 的诊断。++++
1 方法
1.1 数据准备
数据集涉及一个包含31名个体的数据库,其中23人被诊断出患有帕金森病(PD),并在牛津大学寻求治疗。科罗拉多州丹佛的国家声音与语言中心记录了这些参与者的语音信号。从每个受试者那里收集了多种类型的语音样本,包括持续元音、数字、单词和短句,总共得到了195个语音录音(每个患者大约六个录音)。从这些录音中提取了一组22个线性和时/频基础特征,这些特征并非相互独立的。
为了减少分类器过拟合的风险,现有数据被随机划分为两个不同的集合:一个包含156个样本的训练集和一个包含39个样本的测试集。这种划分方法允许分类器在训练数据上进行训练,并随后使用独立的测试数据进行评估。
1.2 回声状态网络结构
回声状态网络 (Echo State Network, ESN)是一种为预测非线性时间序列和分析复杂系统而设计的递归神经网络(RNN)。ESN 由三个层次组成:
- 输入层: 接收输入数据,例如语音信号的声学特征。
- 隐藏层(池): 也称为"池",包含大量稀疏连接的内部单元。池的权重是随机初始化的,并且在训练过程中保持不变。
- 输出层: 也称为"读取层",包含输出神经元,其权重可以通过学习进行调整。

1.2.1 工作原理
- 初始化: 随机初始化输入层和池的权重,以及池的泄漏率。
- 状态更新: 对于每个输入数据点,根据输入权重和池的权重计算池的激活状态。池的激活状态会根据泄漏率进行更新,以保留之前的激活状态。
- 输出计算: 使用池的激活状态和输出权重计算输出值。
- 训练: 通过最小化输出值与目标值之间的差异来调整输出权重。
1.2.2 ESN 的优势
- 简单易用: 结构简单,训练过程相对容易,并且可以快速收敛。
- 非线性能力: 可以处理非线性数据,并捕捉数据中的复杂模式。
- 泛化能力: 具有良好的泛化能力,可以在新的数据上表现良好。
- 鲁棒性:对输入噪声和权重初始化不敏感。
1.3 特征选择
1.3.1 为什么需要进行特征选择
- 样本数量有限: 本研究中,训练数据样本数量有限,因此需要避免过拟合,选择最具代表性的特征。
- 减少模型复杂性: 特征选择可以减少模型的输入维度,降低模型的复杂性和计算量,提高模型的训练和推理效率。
- 提高诊断精度: 选择最具影响力的特征可以提高模型的诊断精度,减少误诊和漏诊的风险。
1.3.2 特征选择方法
- 方差分析(ANOVA): ANOVA 是一种统计方法,用于评估多个组之间的均值是否存在显著差异。在本研究中,ANOVA 用于评估每个特征与目标变量(健康或帕金森病)之间的统计显著性。
- F-值: ANOVA 分析会生成每个特征的 F-值,F-值越高,表明该特征与目标变量之间的关系越强。
1.3.3 特征选择过程
- 计算 F-值: 对每个特征进行 ANOVA 分析,并计算其 F-值。
- 选择特征: 根据 F-值选择最具影响力的特征。++++本研究中,选择了 F-值最高的 4 个特征:MDVP:Fo(Hz)、spread1、spread2 和 PPE。++++
1.4 模型训练
2.2 评估过程
2.3 评估结果
-
初始化: 随机初始化 ESN 的输入权重、池权重和泄漏率。
-
贝叶斯优化: 使用贝叶斯优化方法来调整 ESN 的超参数,例如池的大小、泄漏率等,以获得最佳性能。
-
状态更新: 对于每个输入数据点,根据输入权重和池的权重计算池的激活状态。池的激活状态会根据泄漏率进行更新,以保留之前的激活状态。
-
输出计算: 使用池的激活状态和输出权重计算输出值。
2 评估
2.1 评估指标
-
准确率 (Accuracy): 衡量模型正确预测的比例,即正确预测的样本数占总样本数的比例。
-
精确率 (Precision): 衡量模型正确预测为正类的比例,即正确预测为正类的样本数占预测为正类的样本数的比例。
-
召回率 (Recall): 衡量模型正确识别所有正类的比例,即正确预测为正类的样本数占实际正类样本数的比例。
-
假阴性率 (False Negative Rate): 衡量模型错误地将正类预测为负类的比例,即错误预测为负类的正类样本数占实际正类样本数的比例。
-
数据划分: 将数据集划分为训练集和测试集,用于训练和评估模型。
-
模型训练: 使用训练集数据训练模型,并调整模型的参数。
-
模型评估: 使用测试集数据评估模型的性能,并计算各种评估指标。
-
模型比较: 将 ESN 与其他分类算法进行比较,分析其优缺点。
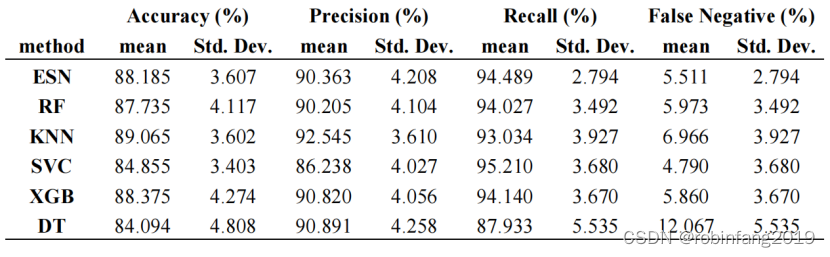
2.3.1 准确率
- KNN 方法在准确率方面表现最佳,但与其他高准确率方法(ESN、RF 和 XGBoost)的差异并不显著。
- ESN、RF 和 XGBoost 方法在准确率方面也表现出色,与 KNN 方法相当。
- 所有方法的准确率都存在一定的波动,这与数据集的固有不平衡性有关。
2.3.2 精确率
- ESN 和 RF 方法的精确率略高于其他方法。
- 所有方法的精确率都保持在较高水平,说明模型对 PD 的识别能力较强。
2.3.3 召回率(灵敏度)
- ESN 方法的召回率最高,说明其能够有效识别出 PD 患者,减少漏诊。
- 其他方法的召回率也较高,说明模型对 PD 的诊断能力较强。
2.3.4 假阴性率
- ESN 方法的假阴性率最低,在 83% 的情况下假阴性率低于 8%。
- ++++其他方法的假阴性率相对较高,说明 ESN 在减少误诊方面具有显著优势。++++
- 假阴性率是 PD 诊断中非常重要的指标,因为漏诊可能导致患者错过最佳治疗时机,造成严重后果。
2.3.5 模型比较
- ++++ESN 在准确率、精确率和召回率方面与其他高准确率方法相当,但在假阴性率方面具有显著优势。++++
- ESN 在处理有限数据集方面具有优势,能够在保持高准确率的同时,最大限度地减少误诊。
- KNN 方法在准确率方面表现最佳,但在假阴性率方面不如 ESN。
- RF 和 XGBoost 方法在准确率、精确率和召回率方面表现良好,但假阴性率略高于 ESN。
- SVM 和决策树方法的性能略低于其他方法。
2.3.6 总体结论
- ESN 是一种有效的 PD 诊断方法,尤其在假阴性率方面具有显著优势。
- 特征选择对于提高 ESN 模型的性能至关重要。
- ESN为基于人工智能的 PD 诊断提供了新的思路,有望提高诊断准确率和效率,减少误诊和漏诊,改善患者预后。
3 相关知识
3.1 声学特征
3.1.1 基频特征
- ++++MDVP:Fo(Hz): 平均声带振动频率,即基频的平均值。++++
- MDVP:Fhi(Hz): 基频的最大值。
- MDVP:Flo(Hz): 基频的最小值。
3.1.2 振幅特征
- MDVP:Jitter(%): 抖动,即基频周期之间差异的百分比。
- MDVP:Jitter(Abs): 抖动的绝对值,即基频周期之间差异的平均值(以微秒为单位)。
- MDVP:RAP: 相对振幅扰动,即基频振幅之间差异的百分比。
- MDVP:PPQ: 五点周期扰动商,即基频周期之间差异的百分比。
- Jitter:DDP: 周期差异差异的平均绝对值除以平均周期,用于评估基频的稳定性。
- MDVP:Shimmer: 闪烁,即基频振幅之间差异的百分比。
- MDVP:Shimmer(dB): 闪烁的分贝值。
- Shimmer:APQ3: 三点振幅扰动商,即基频振幅之间差异的百分比。
- Shimmer:APQ5: 五点振幅扰动商,即基频振幅之间差异的百分比。
- MDVP:APQ: 十一点振幅扰动商,即基频振幅之间差异的百分比。
- Shimmer:DDA: 连续周期之间振幅差异的平均绝对值。
3.1.3 谐波特征
- NHR: 噪声谐波比,即噪声能量与谐波能量之比。
- HNR: 谐波噪声比,即谐波能量与噪声能量之比。
3.1.4 其他特征
- RPDE: 再现周期密度熵,用于评估基频的稳定性。
- DFA: 去趋势波动分析,用于评估语音信号的复杂性。
- D2: 相关系数维数,用于评估语音信号的非线性特性。
- ++++PPE: 基频周期熵,用于评估基频的随机性。++++
- ++++Spread1: 一种基频变化的非线性度量。++++
- ++++Spread2: 另一种基频变化的非线性度量。++++
3.2 常用分类器
- 随机森林(RF)是一种利用决策树集成的机器学习算法。++++与其他方法不同,它通过构建多个决策树,并为每棵树随机选择特征子集++++ 。这些树的预测结果通过聚合它们的投票来组合,得票数最多的类别成为最终预测。RF以其能够减轻过拟合和捕捉变量的非线性和交互效应而闻名。训练过程的并行化显著减少了所需的训练时间。通过组合每棵树的预测结果,RF有效地降低了方差,提高了整体预测精度。
- K-最近邻(KNN)是一种基于最近邻规则的简单分类算法。它通过计算测试样本与所有训练样本之间的距离,将测试样本分配给其k个最近邻居中最普遍的类别。++++KNN已应用于分析PD患者的不同声音特征,包括抖动、闪烁和谐波噪声比,并在检测帕金森病方面显示出适度的准确率++++ 。
- 支持向量分类器(SVC)是一种传统的监督机器学习技术,广泛用于分类和回归任务。它依赖于核方法,以其能够分割决策边界,有效地分离数据点类别而著称。++++在PD检测的背景下,SVC通过分析各种运动特征,如震颤幅度、加速度和快速度,展示了高准确率++++ 。
- 极端梯度提升(XGBoost)是一种集成学习算法,结合了多个机器学习模型,特别是梯度提升决策树。它基于不同的决策标准构建多个决策树,类似于随机森林。++++XGBoost以其速度和效率而闻名,使其成为各种应用的首选++++ 。