⭐️我叫忆_恒心,一名喜欢书写博客的研究生👨🎓。
如果觉得本文能帮到您,
麻烦点个赞👍呗!
近期会不断在专栏里进行更新讲解博客~~~有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三连支持一下呗。👍⭐️❤️
📂
Qt5.9专栏定期更新Qt的一些项目Demo📂
项目与比赛专栏定期更新比赛的一些心得 ,面试项目 常被问到的知识点。欢迎评论 💬点赞👍🏻 收藏 ⭐️加关注+
✍🏻文末可以进行资料和源码获取欧😄
前言
当我们需要收集一些数据的时候,自动化数据采集工具总是可以帮到我们,但是传统的自动化数据采集工具,存在以下不足:
- 工具的通用程度低:需要我们手动分析每个网站的特点;
- 保存的数据格式也比较单一
- 操作麻烦
当AI的阅读理解能力遇到了自动化采集工具的时候,将会产生怎么样的魔法呢?
能够理解你的意图 并自动执行复杂的网络数据抓取任务,ScrapeGraphAI 就是这样一个工具,它利用最新的人工智能技术,让数据提取变得前所未有地简单。
工具的优点

- 简单易用:只需输入 API 密钥,您就可以在几秒钟内抓取数千个网页!
- 开发便捷:你只需要实现几行代码,工作就完成了。
- 专注业务:有了这个库,您可以节省数小时的时间,因为您只需要设置项目,人工智能就会为您完成一切。
一、介绍
ScrapeGraphAI 是一个网络爬虫 Python 库,使用大型语言模型和直接图逻辑为网站和本地文档(XML,HTML,JSON 等)创建爬取管道。
只需告诉库您想提取哪些信息,它将为您完成!

scrapegraphai有三种主要的爬取管道可用于从网站(或本地文件)提取信息:
SmartScraperGraph: 单页爬虫,只需用户提示和输入源;SearchGraph: 多页爬虫,从搜索引擎的前 n 个搜索结果中提取信息;SpeechGraph: 单页爬虫,从网站提取信息并生成音频文件。SmartScraperMultiGraph: 多页爬虫,给定一个提示 可以通过 API 使用不同的 LLM,如 OpenAI ,Groq ,Azure 和 Gemini ,或者使用 Ollama 的本地模型。
官方提供了非常详细的文档:官方文档
二、准备工作
2.1 安装ollama
点击前往网站 https://ollama.com/ ,下载ollama软件,目前该软件支持支持win、Mac、linux
2.2 下载LLM
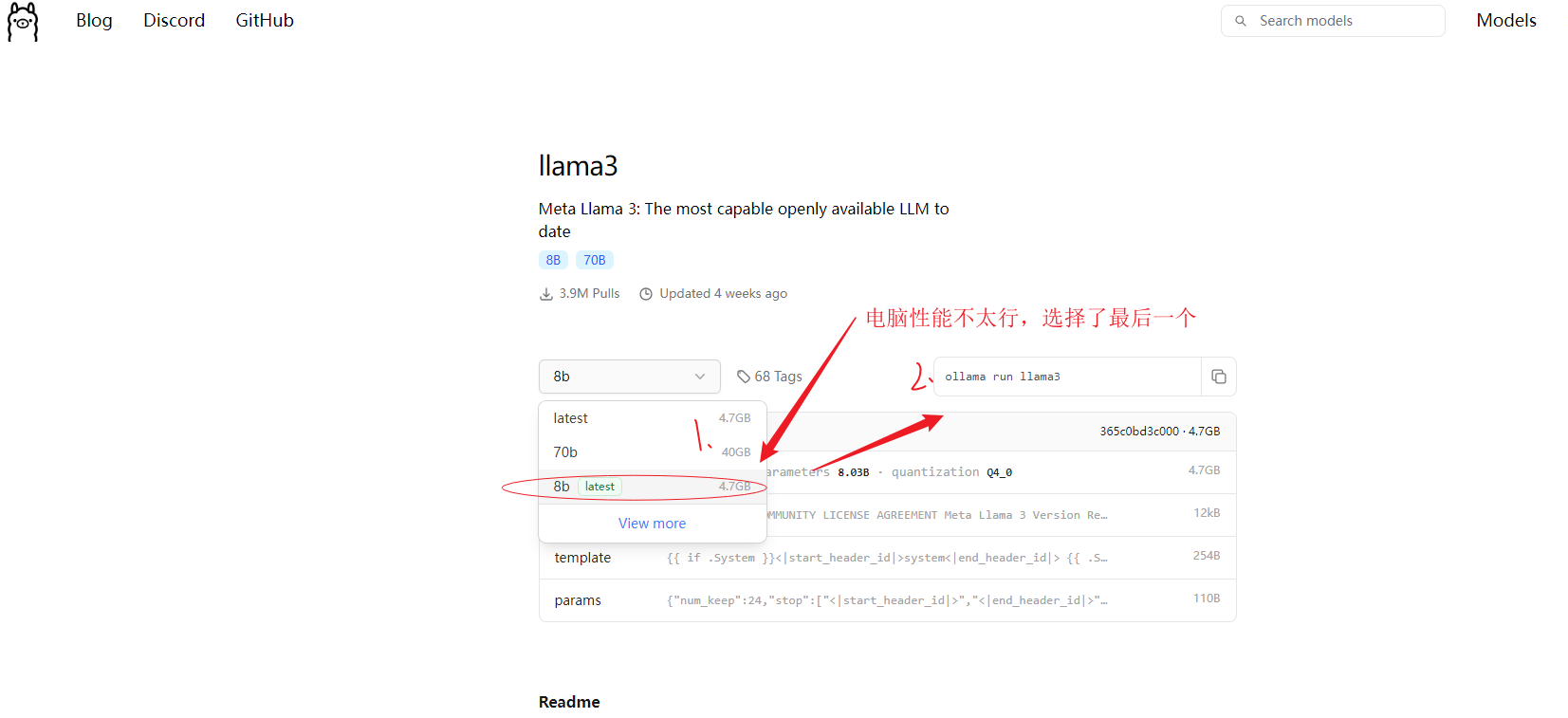
ollama软件目前支持多种大模型, 如阿里的(qwen、qwen2)、meta的(llama3),
以llama3为例,根据自己电脑显存性能, 选择适宜的版本。如果不知道选什么,那就试着安装,不合适不能用再删除即可 。
打开电脑终端命令行cmd, 网络是连网状态,执行模型下载(安装)命令
强烈建议,更改默认路径
新建变量
OLLAMA_MODELS
值
D:\OllamaCache
添加了环境变量后,记得重启计算机,使其生效
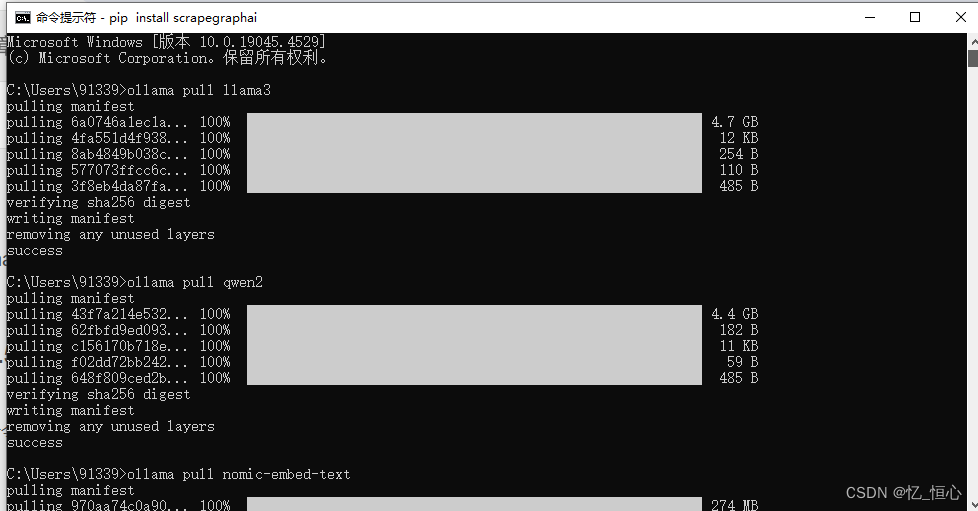
ollama pull llama3
ollama pull qwen2
ollama pull nomic-embed-text等待 llama3、 nomic-embed-text 下载完成。
2.3 安装python包
在python中调用ollama服务,需要ollama包。
打开电脑命令行cmd(mac是terminal), 网络是连网状态,执行安装命令
pip3 install ollama建议使用anaconda环境来管理这些包,因为默认的base环境可能会出现python版本不兼容的问题。
# 创建名为 ollama 的虚拟环境,并指定 Python 3.10
conda create --name ollama python=3.10
# 激活虚拟环境
conda activate ollama2.4 启动ollama服务
在Python中调用本地ollama服务,需要先启动本地ollama服务, 打开电脑命令行cmd(mac是terminal), 执行
ollama serveRun
cmd(mac是terminal)看到如上的信息,说明本地ollama服务已开启。
2.5 安装scrapegraphai及playwright
电脑命令行cmd(mac是terminal), 网络是连网状态,执行安装命令
pip install scrapegraphai之后继续命令行cmd(mac是terminal)执行
playwright install等待安装完成后,进行实验
三、实验
注意端口冲突,尽量不要使用8080
3.1 案例1
以我的博客 ydlin.blog.csdn.net 为例,假设我想获取标题、日期、文章链接,
代码如下:
from scrapegraphai.graphs import SmartScraperGraph
graph_config = {
"llm": {
"model": "ollama/llama3",
"temperature": 0,
"format": "json", # Ollama 需要显式指定格式
"base_url": "http://localhost:11434", # 设置 Ollama URL
},
"embeddings": {
"model": "ollama/nomic-embed-text",
"base_url": "http://localhost:11434", # 设置 Ollama URL
},
"verbose": True,
}
smart_scraper_graph = SmartScraperGraph(
prompt="返回该网站所有文章的标题、日期、文章链接",
# 也接受已下载的 HTML 代码的字符串
#source=requests.get("https://ydlin.blog.csdn.net/").text,
source="https://ydlin.blog.csdn.net/",
config=graph_config
)
result = smart_scraper_graph.run()
print(result)Run
--- Executing Fetch Node ---
--- Executing Parse Node ---
--- Executing RAG Node ---
--- (updated chunks metadata) ---
--- (tokens compressed and vector stored) ---
--- Executing GenerateAnswer Node ---
Processing chunks: 100%|█████████████████████████| 1/1 [00:00<00:00, 825.81it/s]
...3.2 案例2
采集豆瓣读书 https://book.douban.com/top250 中的 名字、作者名、评分、书籍链接 等信息。

from scrapegraphai.graphs import SmartScraperGraph
graph_config = {
"llm": {
"model": "ollama/llama3",
"temperature": 0,
"format": "json", # Ollama 需要显式指定格式
"base_url": "http://localhost:11434", # 设置 Ollama URL
},
"embeddings": {
"model": "ollama/nomic-embed-text",
"base_url": "http://localhost:11434", # 设置 Ollama URL
},
"verbose": True,
}
smart_scraper_graph2 = SmartScraperGraph(
prompt="返回该页面所有书的名字、作者名、评分、书籍链接",
source="https://book.douban.com/top250",
config=graph_config
)
result2 = smart_scraper_graph2.run()
print(result2)Run
--- Executing Fetch Node ---
--- Executing Parse Node ---
--- Executing RAG Node ---
--- (updated chunks metadata) ---
--- (tokens compressed and vector stored) ---
--- Executing GenerateAnswer Node ---
Processing chunks: 100%|████████████████████████| 1/1 [00:00<00:00, 1474.79it/s]
{}采集失败,返回空。
将大模型llama3改为qwen2
from scrapegraphai.graphs import SmartScraperGraph
graph_config2 = {
"llm": {
"model": "ollama/qwen2",
"temperature": 0,
"format": "json", # Ollama 需要显式指定格式
"base_url": "http://localhost:11434", # 设置 Ollama URL
},
"embeddings": {
"model": "ollama/nomic-embed-text",
"base_url": "http://localhost:11434", # 设置 Ollama URL
},
"verbose": True,
}
smart_scraper_graph3 = SmartScraperGraph(
prompt="返回该页面所有书的名字、作者名、评分、书籍链接",
source="https://book.douban.com/top250",
config=graph_config2
)
result3 = smart_scraper_graph3.run()
print(result3)Run
--- Executing Fetch Node ---
--- Executing Parse Node ---
--- Executing RAG Node ---
--- (updated chunks metadata) ---
--- (tokens compressed and vector stored) ---
--- Executing GenerateAnswer Node ---
Processing chunks: 100%|████████████████████████| 1/1 [00:00<00:00, 1102.60it/s]
{'urls': ['https://book.douban.com/subject/10554308/', 'https://book.douban.com/subject/1084336/', 'https://book.douban.com/subject/1084336/', 'https://book.douban.com/subject/1046209/', 'https://book.douban.com/subject/1046209/', 'https://book.douban.com/subject/1255625/', 'https://book.douban.com/subject/1255625/', 'https://book.douban.com/subject/1060068/', 'https://book.douban.com/subject/1060068/', 'https://book.douban.com/subject/1449351/', 'https://book.douban.com/subject/1449351/', 'https://book.douban.com/subject/20424526/', 'https://book.douban.com/subject/20424526/', 'https://book.douban.com/subject/29799269/', 'https://book.douban.com/subject/1034062/', 'https://book.douban.com/subject/1229240/', 'https://book.douban.com/subject/1237549/', 'https://book.douban.com/subject/1078958/', 'https://book.douban.com/subject/1076932/', 'https://book.douban.com/subject/1075440/', 'https://book.douban.com/subject/1076932/', 'https://book.douban.com/subject/1078958/', 'https://book.douban.com/subject/1076932/', 'https://book.douban.com/subject/1078958/', 'https://book.douban.com/subject/1076932/', 'https://book.douban.com/subject/1078958/', 'https://book.douban.com/subject/1076932/'], 'images': ['https://img1.doubanio.com/view/subject/s/public/s1078958.jpg', 'https://img1.doubanio.com/view/subject/s/public/s1076932.jpg', 'https://img1.doubanio.com/view/subject/s/public/s1447349.jpg']}采集到一些信息,但没有书名、作者等信息。
3.3 使用远程服务器
如果机子的性能比较差,直接利用ChatGPT的key。
仓库中的.md文件给出调用样例,输出的结果为音频文件。
然而实际上,往往在进行数据采集的时候,我们将采集的结果保存成文本格式就可了。
python
import os
from dotenv import load_dotenv
from scrapegraphai.graphs import SmartScraperGraph
from scrapegraphai.utils import prettify_exec_info
load_dotenv()
def main():
#openai_key = os.getenv("x")
graph_config = {
"llm": {
"api_key": "OPENAI_API_KEY",
"model": "gpt-3.5-turbo",
},
}
# ************************************************
# Create the SmartScraperGraph instance and run it
# ************************************************
smart_scraper_graph = SmartScraperGraph(
prompt="List me all the projects with their description.",
# also accepts a string with the already downloaded HTML code
source="https://perinim.github.io/projects/",
config=graph_config
)
result = smart_scraper_graph.run()
print(result)
if __name__ == "__main__":
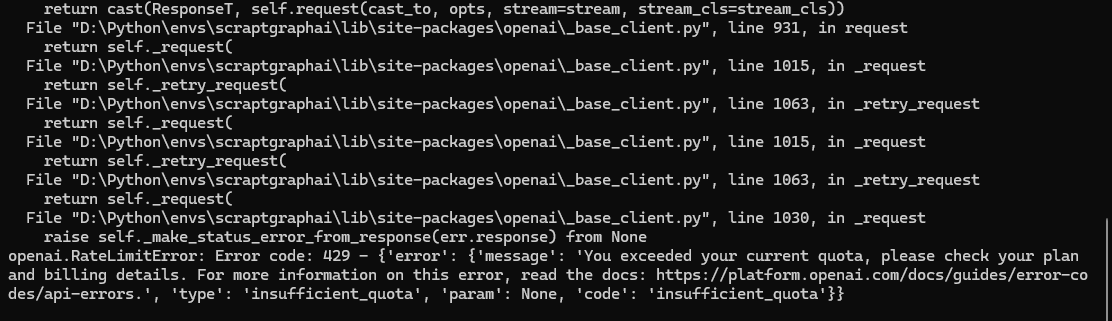
main()在环境都正常配上的时候,出现You exceeded your current quota 需要检查一下OPENAI_API_KEY是否有调用余额。
下面也附上仓库给出的示例,将爬取的结果保存成音频文件。
python
from scrapegraphai.graphs import SpeechGraph
graph_config = {
"llm": {
"api_key": "OPENAI_API_KEY",
"model": "gpt-3.5-turbo",
},
"tts_model": {
"api_key": "OPENAI_API_KEY",
"model": "tts-1",
"voice": "alloy"
},
"output_path": "audio_summary.mp3",
}
# ************************************************
# Create the SpeechGraph instance and run it
# ************************************************
speech_graph = SpeechGraph(
prompt="Make a detailed audio summary of the projects.",
source="https://perinim.github.io/projects/",
config=graph_config,
)
result = speech_graph.run()
print(result)注意:
代码需要在 .py 中运行,在 .ipynb 中运行会报错。
四、讨论与总结
ScrapeGraphAI 能够理解你的意图 并自动执行复杂的网络数据抓取任务。虽然,现在模型还存在着一些不够完善的地方(采集的速度比较慢,底层使用playwright访问速度较慢)
但是目前AI与自动化爬取相结合的一个大模型爬虫,真的可以称得上是一款可以理解用户意义的网络爬虫。
往期优秀文章推荐:
- 研究生入门工具------让你事半功倍的SCI、EI论文写作神器
- 磕磕绊绊的双非硕秋招之路小结
- 研一学习笔记-小白NLP入门学习笔记
- C++ LinuxWebServer 2万7千字的面经长文(上)
- C++Qt5.9学习笔记-事件1.5W字总结
资料、源码获取以及更多粉丝福利,可以关注下方进行获取欧
