一.预备知识
1.基本全局命令
set key value 将key的值设置成value

get key 得到key的值

keys pattern 查看匹配pattern的所有key
比如h?llo匹配hallo,hbllo,hcllo......只要用一个符号将?代替即可
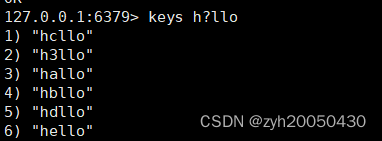
比如h*llo匹配hllo,heeeello......用0个1个或多个字符将*代替即可

比如haello匹配hallo,hello只有这两个

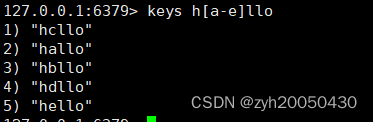
比如ha-ello匹配hallo,hbllo,hcllo,hdllo,hello这五个
比如h\^ello表示除e之外的字母都匹

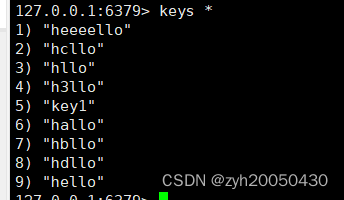
那keys * 则可以获取到任何key
keys命令的时间复杂度是O(N)所以在生产环境上一般禁止使用keys,尤其是大杀器 keys *。因为生产环境上的key一般非常非常多,而Redis又是一个单线程服务器,执行keys*的时间就会非常长,就会使redis服务器阻塞住,无法给其他命令/其他客户端使用。
就像一个妹纸同时交了三个男友,同时与三个男友周旋,如果在同一时间三个男友都要约会,就周旋不过来了。
而且Redis经常被当作缓存,替mysql负重前行。一旦redis被keys *给阻塞住了,那么美其他查询redis的命令就超时了,就会直接访问mysql。突然一大波请求发送过来,mysql就会措手不及,容易挂了
exists key key...... 判断指定的key是否存在
返回值是存在的key的个数

这个命令的时间复杂度是O(1),因为Redis组织这些key-value键值对是按照hash表的方式来组织的,每次找一个key都是O(1),所以当key特别多时,时间复杂度就成了O(N),N指的是key的个数。
exists key1 exists key2 与exists key1 key2 达到的效果相同,但实际上差别很大,因为Redis是客户端与服务器之间通过网络进行通信的,第一种查询方式会产生更多轮次的网络通信,这与直接操作内存比的话,效率更低,成本更高。
因为每次网络通信都涉及到封装分用:进行网络通信时,发送放发送一个数据,这个数据就要从应用层到物理层,层层封装(即每一层协议都要加上报头报尾),就像抱一个快递要包很多层。接收方收到后,这个数据就要从物理层到应用层,层层分用(也就是拆快递)
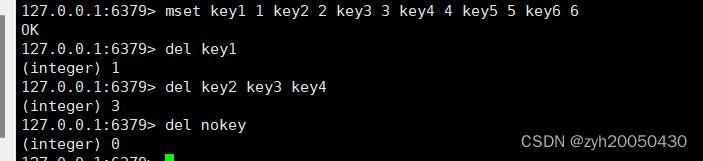
del key key\^ 删除指定的key
返回值是成功删除掉的key的个数
时间复杂度是O(1)。其实还是和exists一样,有几个key就是O几的时间复杂度
我们知道在MySQL中删除数据是很危险的操作,那么del在redis中是不是危险操作呢?
当redis作为缓存存储热点数据时,由于全量数据依然安安全全的在MySQL中,所以redis这里误删了几个数据没有太大影响,只要通过mysql再把数据给映射到redis就可以了。不过要是突然一下子一大半热点数据,redis就大概率无法替mysql负重前行了,就可能使得很多的请求突然到了MySQL那里,可能会导致MySQL挂掉。
当redis作为MQ(消息队列)时,影响程度就要分情况来看了
当redis代替mysql作为数据库时,影响就很大啦
expire key seconds 为指定的key添加过期时间
ttl key 查看当前key剩余的时间
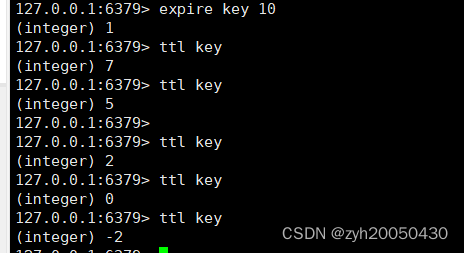
如上,过期时间的单位是秒级,当到期时ttl的返回值就是-2
expire的应用场景有很多:比如点外卖,优惠券在指定时间内有效;比如手机验证码的有效时间;比如分布式锁的实现,有多种实现方式,其中redis就是一种(所谓redis实现分布式锁,其实就是给redis加一个特殊的key-value,把它删了就是解锁),为了避免不能正确解锁的情况,redis就会给锁设置过期时间。
pexpire key也是设定过期时间,不过它的单位是毫秒
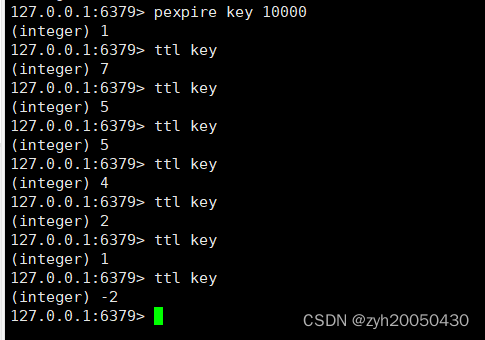
注意,当expire和pexpire后面的key不存在时,返回值就是0

ttl key 查看当前key剩余的时间
ttl获取指定key的过期时间,它的单位也是秒级,ttl即Time To Live
当没有关联过期时间时,它的返回值就是-1,当key不存在时,它的返回值就是-2
在IP协议的报头也有一个ttl,但那个TTL不是用时间来衡量过期的,而是用次数
Redis的过期策略如何实现?
一个Redis中存在很多key,这些key中可能大部分都有过期时间,此时redis服务器咋知道那些key过期了?
redis的整体策略就是定期删除和惰性删除。惰性删除就是当key到期时,先不删,紧接着后面又访问到的时候redis就发现这个key过期了,再把它删了,同时返回nil;而上述过程也要结和定期删除,就是每次抽取一小部分key,看看有没有到期的,有的话就删了。(只取一小部分就能够保证这个抽取检查的过程足够快,防止redis线程阻塞)。
为啥对于定期删除的时间有明确规定?因为redis时单线程程序,它主要的任务(处理命令,扫描过期的key......)都是在一个线程中执行的,如果扫描key这个操作消耗的时间太多或这个操作太频繁,就会影响其他命令执行,就可能达到和keys*一样的效果.
虽然有了上述两种策略,但整体效果还是一般,仍然会有key没能及时删除。因此redis也提供了一系列内存淘汰策略(这个以后会讲到)
注意,redis没有使用定时器的策略来实现过期key的删除。但这里我们也简单复习一下定时器的实现
定时器的实现:
1.基于优先级队列/堆
在redis的过期key中,通过"过期时间越早,优先级越高,越先出队列,队首元素,最早过期"的方式实现key的删除。此时定时器秩序分配一个线程,让线程去检查队首元素,看是否过期。但扫描线程检查队首元素的过期时间时,也不能太频繁,否则会出现忙等。此时就可更具队首元素的过期时间设置一个等待时间,当时间差不多了,系统就唤醒线程。这样的话,扫描线程就不用高频率扫描队首元素了,就能省下cpu开销。但万一要是在休眠的时候来了一个新任务要执行该怎么办?那就直接唤醒这个扫描线程,重新检查队首元素,再根据过期时间去重新调整等待时间。如果key特别多,就可以多来几个扫描线程。
当然redis没有采用这个方法,因为redis是单线程程序。
2.基于时间轮实现的定时器
把时间划分成很多很多的小段(划分的粒度看实际需求),把小段分配到一个圆环上,每一个小段都是一个链表,都代表要执行的任务。假设每一个小段代表100毫秒,有一个key是300毫秒后过期,那么他就被添加到第三个小格上。然后指针就会每隔100毫秒向下走一小格,每次走到一个格子就会把这个格子链表上的任务尝试执行一下,看是不是真的到时间了(就比如一个任务是3000ms过期,那么指针就要转好几圈才能执行到)。
对于时间轮来说,一共多少格子,每个格子多长时间,都是可以灵活调配的。但redis也没有采取这个定时器的策略,不过redis源码里面有个比较核心的机制:事件循环,与时间轮优点类似
type key 查看指定key对应的value的数据类型
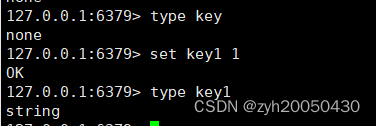
key不存在时返回null
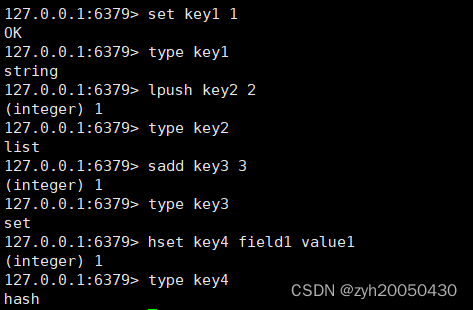
lpush,sadd,hset等命令会在后面讲到
2.Redis数据结构及内部编码
Redis支持很多数据结构,指的是一个value可以是一些复杂的结构,然而它的这些键值对都是通过hash表的形式来组织的,而且key的类型只能是string类型。在redis官方文档上,列出了12中数据结构,如下,不过我们常用的就是5种:String,List,Set,Hash,Zset(有序集合).

但注意,这些只是redis对外的数据结构,它内部可不一定真的是使用这个结构存储value的:Redis底层在实现上述数据结构时,会在源码层面上,针对上述实现进行特定的优化,来达到节省空间/时间的效果。内部具体实现的数据结构(编码方式),还会有变数。
就比如:redis承诺,现在我这里有关hash表,你进行查询删除插入操作时,都保证O(1),但是,这背后的实现,可不一定是标准的hash表,可能在特定场景下使用别的数据结构实现,从而保证承诺
String的内部编码: raw,int,embstrraw:表示最基本的字符串,底层持有一个byte数组
int:当value是一个整数时,redis就会使用int来存储,从而更快实现计数,加减这样的操作
embstr:这个是用来针对短字符串进行特殊优化的。但要是字符串太长,就会使用raw
hash的内部编码:hashtable和ziplisthashtable:注意,它与java标准库中的hashtable不一样
ziplist:压缩列表,在hash表中的元素较少时,使用ziplist来进行优化,但是当元素很多时,就不能使用ziplist而是使用hashtable。压缩列表能够节省空间,但是它的遍历就会变成顺序遍历(那这样的话还能是O(1)的时间复杂度吗?可以,因为元素很少,遍历起来很快)。
为啥要压缩?redis上有很多key,可能某些key的value是hash类型,此时,若这样的key特别多,那么对应的hash结构就很多,那肯定要占用很多内存空间。但要是每个hash都不大,那就用ziplist尽量去压缩,从而使整体占用的内存空间减小。到这里有人会说,那不应该hash越大,越要压缩吗?注意,节省了空间,那肯定在压缩是有其他开销!!,比如时间......
list的内部编码:linkedlist和ziplistlinkedlist:就是链表
ziplist:压缩链表
但是,这是旧版本的redis的list实现方式,从redis3.2版本开始,list的实现方式是quicklist,它代替了linkedlist和ziplist,兼顾两者的优点。quicklist就是一个链表,每一个节点的元素又是一个ziplist。也就是说,quicklist的空间和效率都折中兼顾了
set的编码方式:hashtable和intsetintset:当集合中都是整数时,就是用intset
zset的编码方式:skiplist和ziplistskiplist:跳表,每个节点上有多个指针域,巧妙搭配这些指针域的指向,就可以达到查询的时间复杂度为O(log2N),就近似于二叉平衡搜索树
通过 object encoding key 的命令可以查看指定key的内部编码方式

3.redis的单线程架构
redis只是用一个线程来处理所有的命令和请求,但不是说redis真的只有一个线程,其实它也有多个线程,只不过其他的线程都是在处理网络IO罢了。
假设有两个请求同时要求key自增,那么key最终的结果是加一还是加二呢?
首先回顾一下:在多线程中,自增操作存在线程安全问题,因为自增操作在cpu角度是分成三个指令执行的,它不是原子的,因此可能当两个线程(两个cpu核,共用同一个内存空间)同时要求key自增时,key只自增一次。
redis这里,两个请求同时要求key自增,这也相当于"并行"发起。但是redis服务器这里不会有线程安全问题。因为reids是单线程模型,而不是多线程,这两个请求看似是同时到达redis服务器,但最终还是得在队列里排队,一个一个进行。
redis能使用单线程模型很好的工作,主要是因为redis的核心业务逻辑都是短平快的,不太消耗cpu资源,不太吃多核cpu。
但这样的弊端就是:redis必须要特别小心,若某个操作占用时间特别长,那么就会阻塞其他命令的执行
相关面试题:Redis虽然是单线程模型,但为啥效率这么高,速度这么快?(参照物是数据库)
1.redis访问内存,而数据库访问硬盘
2.redis的核心功能比数据库简单,干的活少,提供的功能比数据库少了不少
3.redis单线程模型,避免了不必要的线程竞争开销。redis每个基本操作都是短平快的,就是简单的操作内存数据结构,不是什么特别消耗cpu的操作,就算是搞个多线程,也没多大意义,提升也不大,甚至可能降低效率
4.redis处理网络IO时,使用了epoll这样的IO多路复用的机制
什么是IO多路复用?就是指一共线程可以管理多个socket。针对TCP来说,服务器这边每次要服务多个客户端,都要给每一个客户端安排一个socket,通过此socket来和客户端进行通信。一个服务器要服务多个客户端,所以自然而然就有多个socket。这些socket难道都是无时无刻不在传输数据吗?当然不是,大多数情况下,这些socket是静默的,上面是没有数据要传输的,也就是说,同一时刻只有少数socket是活跃的。
在以前介绍TCP服务器的时候,有个版本是每个客户端给分配一个线程,这就导致客户端很多时,线程就很多,系统开销就很大。但上面咱们说了大多是线程是不活跃的。所以就可以引入IO多路复用,让一个线程同时去处理多个socket(这是操作系统给程序员提供的机制,即API,内部的功能是操作系统内核实现的。
在linux上,IO多路复用的实现主要是三套API:select,poll,epoll。
什么是epoll呢?好比我们去小吃街买炒饭、肉夹馍和饺子,我们先去让老板做炒饭,在等的过程中去买肉夹馍,再在等的过程中去买饺子。这三份饭,那个先做好了,对应的老板就来喊我,最大限度的节省了时间。这就是epoll,事件通知/回调机制,此时,我一个线程,就同时做了三件事情,但能够同时做这撒气那件事情的前提是这三件事情的交互不太频繁,大部分时间都在等待。
那什么是select呢?那就是老板不喊我,我不停的在三个窗口之间来回跑,问老板饭好了没有
对于IO多路复用,java中使用的是NIO(标准库中提供的一组类,底层封装了epoll)