ApeGNN: Node-Wise Adaptive Aggregation in GNNs for Recommendation
ApeGNN:GNN 中的节点自适应聚合以进行推荐
Abstract
近年来,图神经网络(GNN)在推荐方面取得了长足的进步。基于 GNN 的推荐系统的核心机制是迭代聚合用户-项目交互图上的邻近信息。然而,现有的 GNN 平等对待用户和项目,无法区分每个节点的不同局部模式 ,这使得它们在推荐场景中表现不佳。为了解决这一挑战,我们提出了一种节点式自适应图神经网络框架 ApeGNN。 ApeGNN 开发了一种用于信息聚合的节点式自适应扩散机制,其中每个节点都能够根据局部结构(例如程度)自适应地决定其扩散权重。我们在六个广泛使用的推荐数据集上进行了实验。实验结果表明,所提出的 ApeGNN 优于最先进的基于 GNN 的推荐方法(高达 48.94%),证明了节点自适应聚合的有效性。
1 Introduction
基于 GNN 的推荐模型存在一些问题:
- 基于 GNN 的推荐没有区分节点类型。用户-项目交互网络是一种特殊类型的图,其中边只能存在于用户和项目的中间。换句话说,两个用户或项目之间没有直接通信。
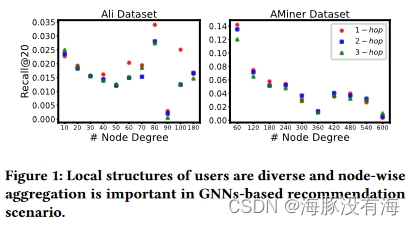
- 不同用户/项目的局部结构在推荐上是不同的。 在图 1 中,我们展示了一个激励示例,以充分理解这项工作的动机,即基于 GNN 的推荐的节点必要性。
因此,我们建议研究在基于 GNN 的推荐方法的聚合过程中是否应该在不同层中区别对待每个节点。
在这项工作中,作者提出了一种新颖的 A daP tivE 模型(ApeGNN),它在 GNN 中进行节点自适应聚合以进行推荐。作者没有在高阶聚合和传播过程中在每一层平等地对待每个用户和项目,而是利用图扩散过程自适应地为邻居的每一跳分配唯一的权重 (内层权重),并区分来自不同 GNN 的信息层,促进了聚合方法从固定聚合向节点聚合的发展。 ApeGNN 可以作为插件,自然地融入到任何现有的基于 GNN 的模型中进行推荐,而无需修改模型的架构。
2 Graph Neural Networks for Recommendation
2.1 Preliminaries
基于 GNN 的推荐系统在输入图结构上执行消息传递 以获得上下文表示。通常,消息传递过程包括聚合(aggregation)和池化(pooling)。
2.2 The limitation of GNNs-based models
• Degree-based Aggregator Represented by LightGCN. 以LightGCN 为代表的基于度的聚合器。
• Attention-based Aggregator Represented by GAT. 以GAT 为代表的基于注意力的聚合器。
3 The ApeGNN

3.1 Node-Wise Adaptive Aggregation in GNNs
为了将节点重要性纳入基于 GNN 的推荐模型中的现有聚合中,我们设计了一种节点式自适应聚合机制。对于用户 u i u_i ui 及其邻居节点 N u i \mathcal N_{u_i} Nui ,用户 u i u_i ui 具有权重系数函数 θ ( t u i ) \theta (t_{u_i}) θ(tui) 的聚合函数AGG:
h u i = A G G ( h v j , ∀ v j ∈ N u i ; θ ( t u i ) ) \mathbf{h}{u_i} = AGG ({\mathbf h{v_j},\forall v_j \in \mathcal N_{u_i}};\theta (t_{u_i})) hui=AGG(hvj,∀vj∈Nui;θ(tui))
对于项目 v j v_j vj 和上述等式类似:
h v j = A G G ( h u i , ∀ u i ∈ N v j ; θ ( t v j ) ) \mathbf{h}{v_j} = AGG ({\mathbf h{u_i},\forall u_i \in \mathcal N_{v_j}};\theta (t_{v_j})) hvj=AGG(hui,∀ui∈Nvj;θ(tvj))
Weighting Coefcients θ \theta θ .
应该通过设置不同的权重来区别对待不同层的嵌入,以在聚合过程中捕获每层的独特语义。特别地,我们提出了两种方法,即热核(HT)1和个性化PageRank(PPR)2,来模拟图扩散过程并提供更好的重要性选择支持。
1 Widder and David Vernon. 1976. The heat Kernel. Academic Press 1976.
2 Lawrence Page, Sergey Brin, Rajeev Motwani, and Terry Winograd. 1999. The PageRank citation ranking: Bringing order to the web. Technical Report. Stanford InfoLab.
The heat kernel.
在基于gnn的模型中,节点之间的特征传播可以看作是牛顿冷却定律(也称为热核)的实践,其中热量从温度较高的区域转移到温度较低的区域。也就是说,两个节点之间的嵌入传播自然与它们的表示成正比。
PPR.
利用 PageRank 2 和 APPNP 3 中使用的 PPR 来构建图结构信息并为每个节点分配唯一的权重。ApeGNN 和 APPNP 的共同点是,我们将 GCN 与个性化 PageRank 结合起来,以进行远距离传播并降低过度平滑的风险,并适当利用传送概率来保留初始特征以获得更好的性能。通过利用热核和个性化PageRank,我们可以为每个节点灵活地分配适当的权重,以增强低频过滤器并增强图的平滑度。
3 Johannes Klicpera, Aleksandar Bojchevski, and Stephan Günnemann. 2018. Predict then propagate: Graph neural networks meet personalized pagerank. arXiv preprint arXiv:1810.05997 (2018).
Centrality Importance t t t .
如图 1 所示, u u u 的最佳传播是不确定 的。因此,在对节点的重要性进行建模时应考虑每层的邻居权重 ,并且在聚合过程中获取节点的表示时应对用户和项目节点之间的不同影响进行建模。先前关于节点重要性估计的研究表明,节点的重要性与其在图中的中心性正相关 。一般来说,用户节点 u i u_i ui的入度 D ( u i ) D(u_i) D(ui)表示其中心性和流行度。因此,我们使用入度 D ( u i ) D(u_i) D(ui) 作为 u i u_i ui和 v j v_j vj初始层的权重 t u i ( 0 ) t^{(0)}{u_i} tui(0)和 t v j ( 0 ) t^{(0)}{v_j} tvj(0)来建模用户和项目的差异。这里,我们为用户 u i u_i ui 定义 t t t,并为 t t t 获取一个较小的值。项目的中心重要性与等式中用户的中心重要性类似。
t_{u_i}\^{(0)} = \\varphi(D(u_i)) = \\sigma(\\log(D(u_i) + \\epsilon)),
在 ApeGNN 中,通过给出用户-项目交互二分图作为输入,通过自适应聚合区分每个用户和每个项目的嵌入,并且该嵌入以节点方式参数化以形成最终表示。用于推荐的 ApeGNN 架构如图 2 所示,它说明了模型的主要部分------节点式内层聚合和层间传播。
3.2 Propagation Process
将每个嵌入层添加到传播层以挖掘高阶连接信息。用户和项目在第 l l l层的传播嵌入公式为:
h u i ( l ) = θ ( t u i ( l ) ) ∑ v j ∈ N u i p ( u i v j ) h v j ( l − 1 ) , h v j ( l ) = θ ( t v j ( l ) ) ∑ u i ∈ N v j p ( v j u i ) h u i ( l − 1 ) . \mathbf{h}{u_i}^{(l)} = \theta(t{u_i}^{(l)}) \sum_{v_j \in \mathcal{N}{u_i}} p{(u_i v_j)} \mathbf{h}{v_j}^{(l-1)},\\ \mathbf{h}{v_j}^{(l)} = \theta(t_{v_j}^{(l)}) \sum_{u_i \in \mathcal{N}{v_j}} p{(v_j u_i)} \mathbf{h}_{u_i}^{(l-1)}. hui(l)=θ(tui(l))vj∈Nui∑p(uivj)hvj(l−1),hvj(l)=θ(tvj(l))ui∈Nvj∑p(vjui)hui(l−1).
这里作者是借鉴了LightGCN模型,但是他删除了自循环链接去减少信息冗余。
通过用卷积核扩展嵌入聚合和传播函数,ApeGNN 第 l l l 层的用户和项目的自适应图卷积矩阵 E u E_u Eu 和带有权重矩阵 θ θ θ 的 E v E_v Ev 可以表示为:
E u ( l ) = ∑ l = 0 L Θ t u ( l ) T l E u ( l − 1 ) , E v ( l ) = ∑ l = 0 L Θ t v ( l ) T l E v ( l − 1 ) . \mathbf{E}{u}^{(l)} = \sum{l=0}^{L} \Theta_{t_u}^{(l)} \mathbf{T}^l \mathbf{E}{u}^{(l-1)},\\ \mathbf{E}{v}^{(l)} = \sum_{l=0}^{L} \Theta_{t_v}^{(l)} \mathbf{T}^l \mathbf{E}_{v}^{(l-1)}. Eu(l)=l=0∑LΘtu(l)TlEu(l−1),Ev(l)=l=0∑LΘtv(l)TlEv(l−1).
3.3 Pooling
u i u_i ui和 v j v_j vj的最终嵌入总汇为:
h u i ∗ = ∑ l = 0 L h u i ( l ) , h v j ∗ = ∑ l = 0 L h v j ( l ) \mathbf{h}{u_i}^{*} = \sum{l=0}^{L} \mathbf{h}{u_i}^{(l)}, \quad \mathbf{h}{v_j}^{*} = \sum_{l=0}^{L} \mathbf{h}_{v_j}^{(l)} hui∗=l=0∑Lhui(l),hvj∗=l=0∑Lhvj(l)
3.4 Optimization
和大部分基于GNN的推荐算法一样,作者这里选择了BPR(Bayesian Personalized Ranking)作为损失函数。
L = − ∑ ( u i , v j , v k ) ∈ O ln σ ( r ^ u i , v j − r ^ u i , v k ) + λ ∥ E ( 0 ) ∥ 2 , \mathcal{L} = - \sum_{(u_i, v_j, v_k) \in \mathcal{O}} \ln \sigma (\hat{r}{u_i, v_j} - \hat{r}{u_i, v_k}) + \lambda \left\| \mathbf{E}^{(0)} \right\|^2, L=−(ui,vj,vk)∈O∑lnσ(r^ui,vj−r^ui,vk)+λ E(0) 2,