一、题目描述
题目难度:中等
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
输入:nums = 1,2,3
输出:\[1,2,3,1,3,2,2,1,3,2,3,1,3,1,2,3,2,1]
示例 2:
输入:nums = 0,1
输出:\[0,1,1,0]
示例 3:
输入:nums = 1
输出:\[1]
提示:
1 <= nums.length <= 6
-10 <= numsi <= 10
nums 中的所有整数 互不相同
二、解题准备
第一,题意
不解释
第二,基本操作
涉及到数组的遍历,List的增加,可能还有List的删除。
第三,基础原理
对于回溯算法,从大的方面讲,题解一般涉及递归(迭代解法过于复杂)。
从小的方面讲,可能会关系到将题目、解题过程转化为解空间树。
这棵解空间树,一般都是满多叉树 (可能会用剪枝算法,降低运行时间)
一般来说,这棵解空间树,有这样的特点:
它的叶子节点是真正的题解。
它的其它节点,可以理解为解题过程 。
因此,学会遍历多叉树,是解题的基础算法,链接如下:
多叉树遍历算法
三、解题思路
针对该题,我们先手动地解题。
对于数组【a,b,c】
它的排列有以下可能:
第一,如果先选择a,
那么,余下【b,c】进行选择。
紧接着1,如果选择b,余下c进行选择
有答案1为【a,b,c】
紧接着1,如果选择c,余下b选择
有答案2为【a,c,b】
第二,如果先选择b,
那么,余下【a,c】进行选择。
紧接着2,如果选择a,余下c,
有答案3为【b,a,c】
其它同理
我们可以发现,这颗多叉树,从空节点开始,每一层都会减少一个节点,如下图:
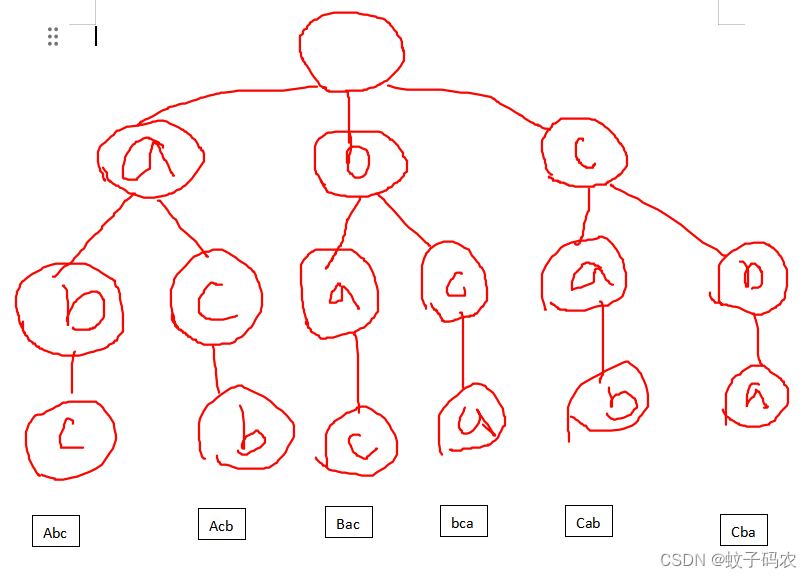
问题1:这不是满多叉树
想必你也发现了,随着层次减少,上一层总比下一层多出一个节点。
这是因为,在全排列中,如果某个位置 使用了a,那么,其它的位置就不能 使用a。
根据全排列的性质,我们可以得到这么个规律(假设length是输入数组的长度):
第一层:有length个节点【忽略,根节点】
第二层:有length-1个节点
......
第length层:有1个节点。此时,这个节点是叶子节点。【也就是我们需要的答案】
问题2:这棵多叉树难以遍历
这棵多叉树虽然结构鲜明,但明显是个刺头,难以下手。
假如,我们使用一个boolean数组,来标记哪个节点被访问,然后根据访问情况,进行遍历判断。
也许可行,不过我没写出来,主要问题出现在:
java
// 随机拿一个未访问的节点
// 使boolean数组为true
访问。
// 设置boolean数组为false这几个步骤中,有2大问题:
第一,随机访问节点,很可能会访问到上一次的节点,这会造成答案重复。
第二,我们不能确定,究竟要访问多少次。【如果用nums的长度为标准,我们会发现,下一层节点,又只有上一层-1个。】
四、解题难点分析
难点如上所示。(我的观点)
难点定义:在数据处理的过程中,数据结构在不断变化。
最开始,有length个节点。
第二层,剩下length-1个。
......
到最后一层,只有1个了。
我们没法用统一的结构,处理这个问题。
A1思考:递归函数的解决结构
我们学习过二叉树的DFS深度优先遍历,以及斐波那契的递归函数。
其实可以发现,它有递归调用递归的过程。
java
// 斐波那契
return feibo(n-1) + feibo(n-2);然而,这两个方案处理的数据结构,是一致的。
虽然斐波那契每次往前回调2次,但是,至始至终,处理的数据量都是2。
二叉树同理,每次处理的都是左子、右子两个节点。
在本题的多叉树中,每次处理的节点在依次减少。
B2解决方案:双层递归函数
我们定义函数A,它提供一个方案:
A处理数据量为len的数组,依次从数组中拿出一个数,然后将此数移出数组,递归调用A函数,处理len-1的数组。
也就是说,A处理的对象是固定的:
只处理数据量为len的数组,其它的情况,交给它的子递归函数。
并且,A处理的结构,每次会按要求减少,直到符合叶子节点,然后返回答案。
代码在下方,在此仅解释。
C3难点:确定参数
A的参数比较难以确定,这属于是回溯法的特点之一。
我在此介绍一种思路:
3个关键词:结果集 、答案集 、输入集
结果集:求解过程中的临时变量,到达叶子节点时,就是一个答案。
答案集:存储所有答案的全局或局部变量。
输入集:变化的数据结构。
另外的参数,需要看题目情况,动态地变化。
D4难点:变化的输入集
由上可知,输入集在不断变化。
如果现在输入集为【a,b,c】
在选择后,剩下【b,c】
如果采用数组的结构,每次新生成一个数组,然后把【b,c】存储到数组,接着再递归调用。
可以发现,这会占用比较大的内存空间,而且数组复制的时间复杂度也不小。
因此,我们可以采用List链表,每次添加一个数,或者删除一个数,这样使用的内存空间会大大减少。
五、代码
java
class Solution {
public List<List<Integer>> permute(int[] nums) {
// 答案集
List<List<Integer>> res = new ArrayList<List<Integer>>();
// 输入集
List<Integer> damn = new ArrayList<>();
// 将数组转化为List,节省内存
for(int i:nums){
damn.add(i);
}
dfs_n(new ArrayList<>(), res, damn);
return res;
}
// data是结果集,临时答案
private void dfs_n(List<Integer> data, List<List<Integer>> res,
List<Integer> damn){
// size为0,就是叶子节点的下一层,该返回了
if(damn.size() == 0){
res.add(new ArrayList<>(data));
return;
}
// 每次访问输入集的长度
for(int i=0; i<damn.size(); i++){
// tem仍要用于回溯,所以用个tem存储
int tem = damn.get(i);
// 结果集添加,输入集移除
data.add(tem);
damn.remove(i);
// 调用子递归函数
dfs_n(data, res, damn);
// 结果集移除,输入集恢复
data.remove(data.size()-1);
damn.add(i, tem);
}
}
}六、结语
以上内容即我想分享的关于力扣热题29的一些知识。
我是蚊子码农,如有补充,欢迎在评论区留言。个人也是初学者,知识体系可能没有那么完善,希望各位多多指正,谢谢大家。