凝聚聚类指的是许多基于相同原则构建的聚类算法,这一原则是:算法首先声明每个点是自己的簇,然后合并两个最相似的簇,知道满足某种停止准则为止。scikit-learn中实现的停止准则是簇的个数,因此相似的簇被合并,直到仅剩下指定个数的簇。还有一些链接准则,规定如何度量"最相似的簇"。这种度量总是定义在两个现有的簇之间。
scikit-learn中实现了以下三种选项:
ward:默认选项。ward挑选两个簇来合并,使得所有簇中的方差增加最小。这通常会得到大小差不多的簇。
average:average链接将簇中所有点之间平均距离最小的两个簇合并。
complete:complete链接(也称为最大链接)将簇中点之间最大距离最小的两个簇合并。
ward适用于大多数数据集,在我们的例子中将使用它。如果簇中的成员个数非常不同(比如其中一个比其他所有都大得多),那么average或complete可能效果更好。
举例:
python
import matplotlib.pyplot as plt
import mglearn.plots
mglearn.plots.plot_agglomerative_algorithm()
plt.show()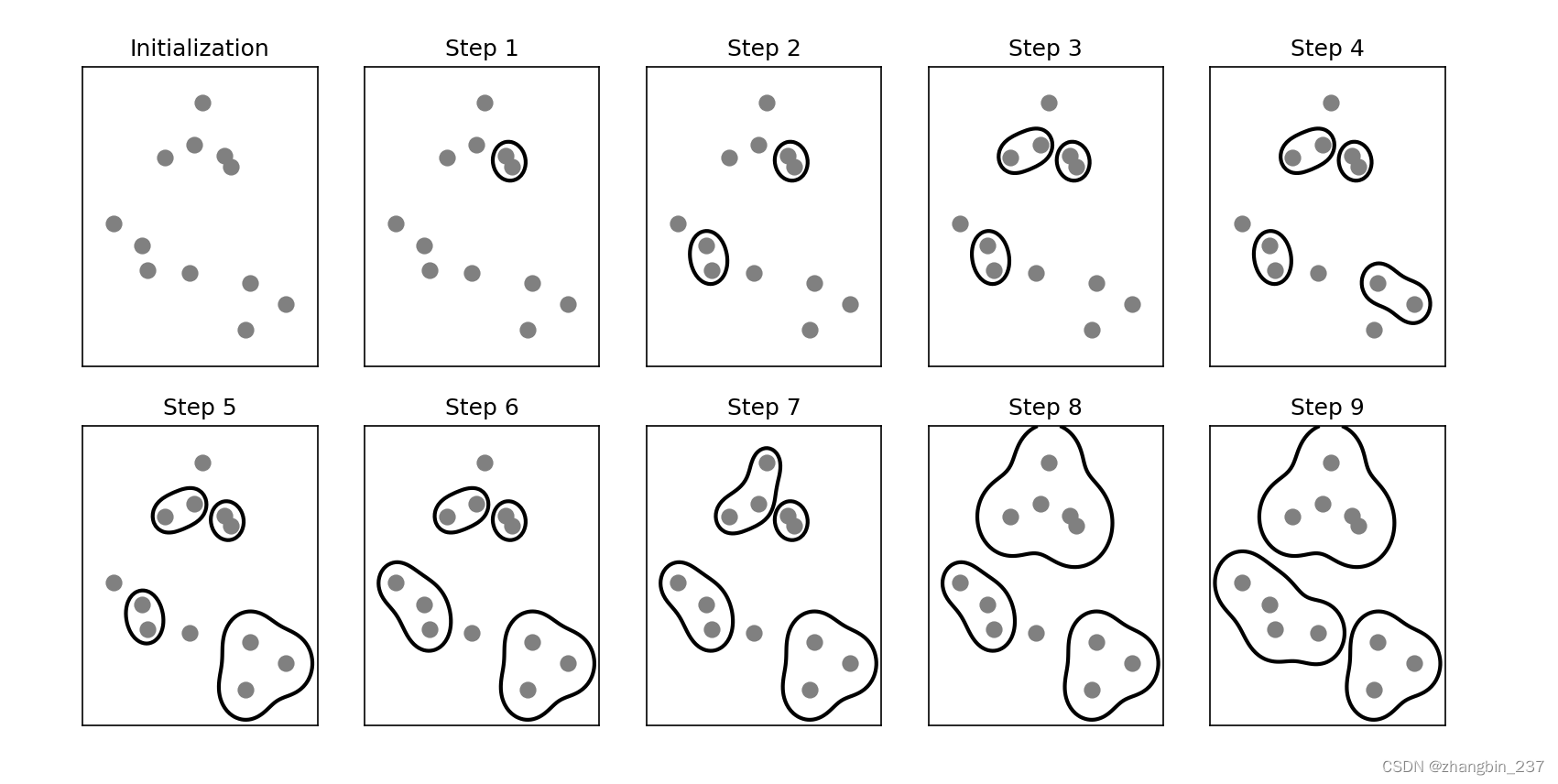
最开始,每个点自成一簇。然后在每个步骤中,相聚最近的两个簇合并。
在前四个步骤中,选出两个单点簇并将其合并成两点簇。在步骤5中,其中一个两点簇被扩展到三个点,以此类推,在步骤9中,只剩下三个簇,由于我们指定寻找3个簇,因此是算法结束。
来看一下凝聚聚类对最简单的三簇数据效果如何。由于算法的工作原理,凝聚算法不能对新数据点做出预测。因此凝聚聚类没有predict方法。为了构造模型并得到训练集上簇的成员关系,可以改用fit_predict方法:
python
import matplotlib.pyplot as plt
import mglearn.plots
from sklearn.datasets import make_blobs,make_moons
from sklearn.cluster import AgglomerativeClustering
agg=AgglomerativeClustering(n_clusters=3)
X,y=make_blobs(random_state=1)
assignment=agg.fit_predict(X)
mglearn.discrete_scatter(X[:,0],X[:,1],assignment)
plt.xlabel('Feature 0')
plt.ylabel('Feature 1')
plt.show()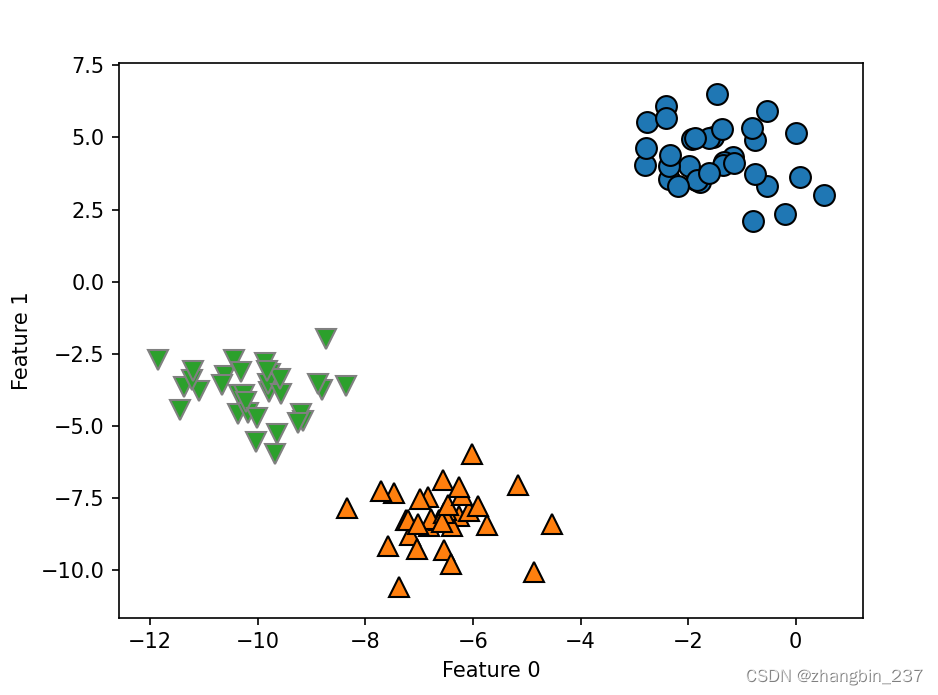
如图,算法完美的完成了聚类。虽然凝聚聚类的scikit-learn实现需要你指定希望算法寻找的簇的个数,但凝聚聚类方法为选择正确的个数提供了一些帮助。