Lucene中基于论文:Optimizing Top-k Document Retrieval Strategies for Block-Max Indexes实现了Block-Max-Maxscore (BMM) 算法,用来优化关键字之间只有OR关系,并且minShouldMatch <= 1时的查询。比如有查询条件为:term1 OR term2 OR term3,那么文档中至少包含其中一个term就认为是满足查询条件。
算法概述
该算法通过对每个term的倒排表排序,排序规则为最大分数/倒排表长度,将高分倒排表作为必要倒排表,低分倒排表作为非必要倒排表。先遍历必要倒排表的文档ID,计算部分评分,如果部分评分加上非必要倒排表的最大分数之和仍低于阈值,则跳过该文档。否则,进行完整评分,包括非必要倒排表的评分。这样,算法减少了不必要的计算操作,因为它避免了对所有文档进行评分,只关注最有可能进入top-k结果的文档。
Lucene中BMM算法的处理逻辑基本跟论文中是一致的,结合上文的算法概述,我们通过以下三个步骤介绍该算法在Lucene中的实现:
- 计算最大分数(Maxscore)
- 选择必要倒排表(essential posting)跟非必要倒排表(non-essential posting)
- 遍历必要倒排表中的文档,选择合适的文档号
算法实现
计算最大分数(Maxscore)
算法名Block-Max-Maxscore中的block-max指的就是将倒排表划分为多个连续区间,每个区间即一个block,最大分数就是在每个block中最大的文档打分值。
由于在查询期间 计算这个区间内所有的 文档打分值然后选出最大值是昂贵的,因此Lucene提供了Impact 机制,使得在索引期间 先挑选出部分 候选者,能保证最高的文档打分值只会出现于这些候选者中。在查询期间 计算这些候选者,找出最大分数。
关于Impact的完整介绍可以阅读文章:索引文件的读取(十二)、ImpactsDISI。本文中我们简述下Impact机制。
Impact
图1:
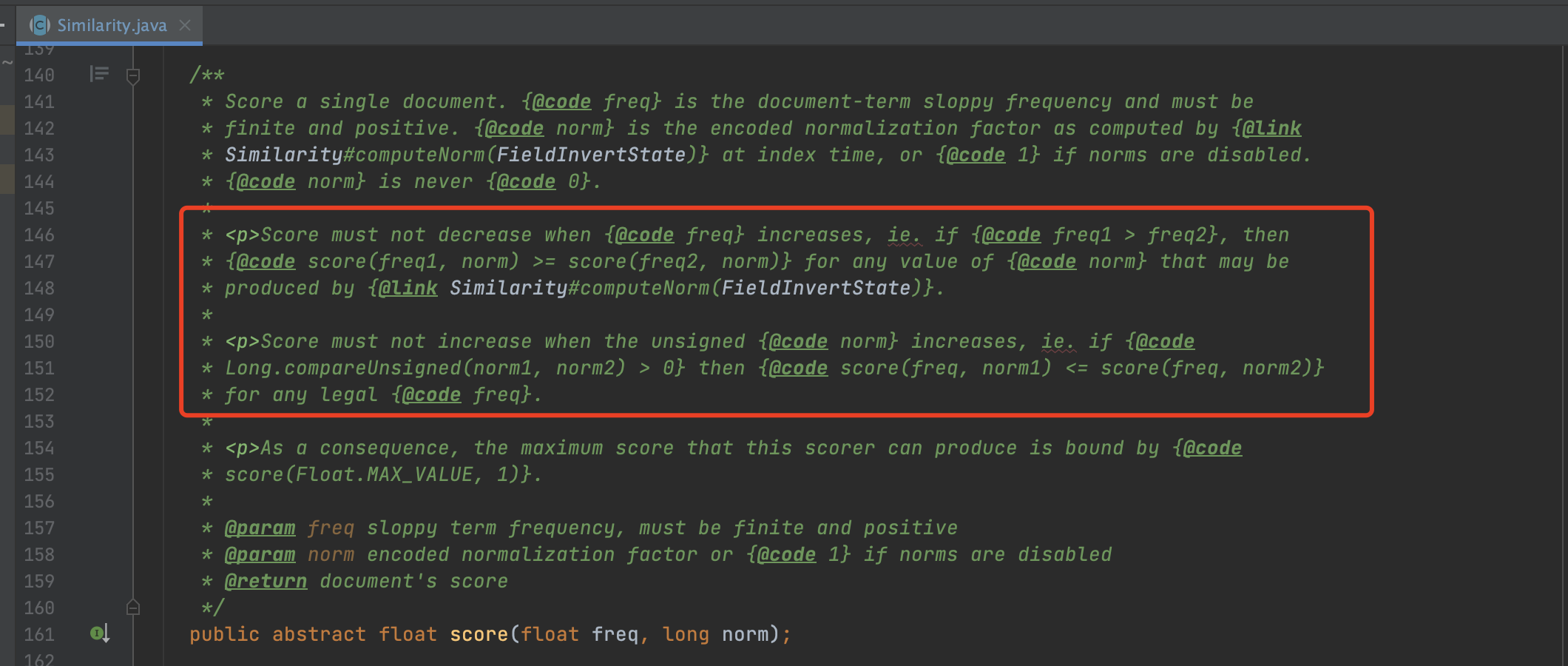
从Lucene打分公式的注释可以看出:
- 如果norm相等,那么freq较大对应的文档打分值会相等或者更高
如果freq相等,那么norm较小对应的文档打分值会相等或者更高
因此在索引期间,我们不需要真正的调用打分公式,而是简单的比较term在每一篇文档中的freq和norm ,就可以筛选出候选者 。也就是freq相等时,norm最小,或者norm相等时,freq最大的文档作为候选者,将他们的freq跟norm信息写入到索引文件中:
图2:

随后在查询阶段,我们就可以根据索引文件中所有的freq和norm,调用图1的打分公式,计算出最终的最大分数。