概览-公式汇总
| 序号 | 公式功能 | 公式 | 公式示例 | 公式说明 |
|---|---|---|---|---|
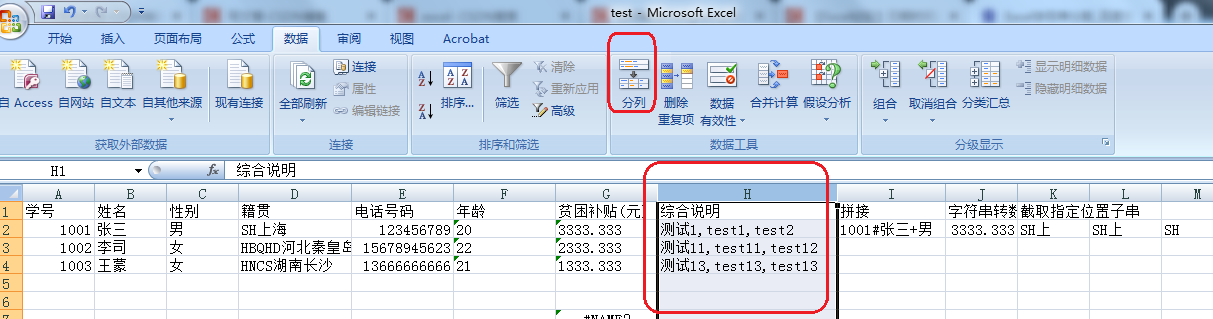
| 1 | 把多列内容拼接在一起,作为新的一列的内容 | CONCATENATE (text1,text2,...) | =CONCATENATE(A2,"#",B2,"+",C2) | 用于根据多个列的内容拼成我们指定格式的内容,拼接的内容通常来源于原始数据,同时有的时候会加上额外固定的内容。 |
| 2 | 某列的内容是数值,但是格式是字符串形式,需要转换为数值类型,方便计算 | VALUE(text) | =VALUE(G2) | 内容是数值,但是在excel中显示的是字符串形式,计算前需要做数据类型转换。 |
| 3 | 截取指定位置的子串 | 左截取 LEFT LEFTB 、右截取 RIGH RIGHB、中间截取MID MIDB | ||
| 4 | 分割字符串用得到后的结果形成新的列 | 用界面的"分列"功能 | ||
| 5 | 计算指定字符串的字符、字节长度 | LEN LENB | ||
| 6 | 文本替换 | REPLACE REPLACEB | ||
| 7 | 指定正则表达抽取相关的内容 | 待补充 | ||
| 8 | 字母大小写转换 | UPPER LOWER | ||
| 9 | 查找字符串 | FIND FINDB 区分大小写;SEARCH SEARCHB不区分大小写 | =FIND("abc,","aabc,ccc",1) 返回结果:2;-- | 函数 FIND 和 FINDB 用于在第二个文本串中定位第一个文本串,并返回第一个文本串的起始位置的值,该值从第二个文本串的第一个字符算起。 |
| 10 | 指定一个字符串,自动生成重复多次的新字符串,用于构造数据使用 | REPT | =REPT("123",2) 结果为:123123 |
1 把多列内容拼接在一起,作为新的一列的内容

2 某列的内容是数值,但是格式是字符串形式,需要转换为数值类型,方便计算

3 截取指定位置的子串
3.1 左截取LEFT、LEFTB
官方说明:
根据所指定的字符数,LEFT 返回文本字符串中第一个字符或前几个字符。
LEFTB 基于所指定的字节数返回文本字符串中的第一个或前几个字符。
要点
函数 LEFT 面向使用单字节字符集 (SBCS) 的语言,而函数 LEFTB 面向使用双字节字符集 (DBCS) 的语言。您计算机上的默认语言设置对返回值的影响方式如下:
无论默认语言设置如何,函数 LEFT 始终将每个字符(不管是单字节还是双字节)按 1 计数。
当启用支持 DBCS 的语言的编辑并将其设置为默认语言时,函数 LEFTB 会将每个双字节字符按 2 计数,否则,函数 LEFTB 会将每个字符按 1 计数。
=LEFT("SH上海",3) 结果为:SH上
=LEFTB("SH上海",3) 结果:SH
=LEFTB("SH上海",4) 结果:SH上
3.2 右截取RIGHT、RIGHTB
字节方式的时候,不够一个完整的汉字的时候,多的部分去除,保证不会中文乱码。
=RIGHT("SH上海",3) 结果为:H上海
=RIGHTB("SH上海",3) 结果为:海
=RIGHTB("SH上海",4) 结果为:上海
3.3 中间截取 MID MIDB
=MID("SH上海",1,3) 结果为:SH上
=MIDB("SH上海",1,3) 结果为:SH
=MIDB("SH上海",1,4) 结果为:SH上
语法
MID(text,start_num,num_chars)
MIDB(text,start_num,num_bytes)
Text 是包含要提取字符的文本字符串。
Start_num 是文本中要提取的第一个字符的位置。文本中第一个字符的 start_num 为 1,以此类推。
Num_chars 指定希望 MID 从文本中返回字符的个数。
Num_bytes 指定希望 MIDB 从文本中返回字符的个数(按字节)。
注解
如果 start_num 大于文本长度,则 MID 返回空文本 ("")。
如果 start_num 小于文本长度,但 start_num 加上 num_chars 超过了文本的长度,则 MID 只返回至多直到文本末尾的字符。
如果 start_num 小于 1,则 MID 返回错误值 #VALUE!。
如果 num_chars 是负数,则 MID 返回错误值 #VALUE!。
如果 num_bytes 是负数,则 MIDB 返回错误值 #VALUE!。
4 分割字符串用得到后的结果形成新的列
9 查找字符串
9.1 FIND FINDB 区分大小写
语法
FIND(find_text,within_text,start_num)
FINDB(find_text,within_text,start_num)
Find_text 要查找的文本。
Within_text 包含要查找文本的文本。
Start_num 指定要从其开始搜索的字符。within_text 中的首字符是编号为 1 的字符。如果省略 start_num,则假设其值为 1。
注解
函数 FIND 与 FINDB 区分大小写并且不允许使用通配符。如果您不希望执行区分大小写的搜索或者要使用通配符,可以使用 SEARCH 和 SEARCHB 函数。
如果 find_text 为空文本 (""),则 FIND 会匹配搜索字符串中的首字符(即编号为 start_num 或 1 的字符)。
Find_text 不能包含任何通配符。
如果 within_text 中没有 find_text,则 FIND 和 FINDB 返回错误值 #VALUE!。
如果 start_num 不大于 0,则 FIND 和 FINDB 返回错误值 #VALUE!。
如果 start_num 大于 within_text 的长度,则 FIND 和 FINDB 返回错误值 #VALUE!。
使用 start_num 可跳过指定的字符数。以 FIND 函数为例,假设要处理文本字符串"AYF0093.YoungMensApparel"。若要在文本字符串的说明部分中查找第一个"Y"的编号,请将 start_num 设置为 8,这样就不会搜索文本的序列号部分。函数 FIND 从第 8 个字符开始,在下一个字符处查找 find_text,并返回数字 9。FIND 总是返回从 within_text 的起始位置计算的字符的编号,如果 start_num 大于 1,则会计算跳过的字符。