在adult数据集的例子中,分类变量被编码为字符。一方面可能会有拼写错误,但另一方面,它明确的将一个变量标记为分类变量。无论是为了便于存储还是因为数据的手机方式,分类变量通常被编码为整数。
假设adult数据集中的人口普查数据是利用问卷收集的,workclass的回答会被记录为0、1、2、3等。现在该列包含数字0到8,而不是"private"这样的字符串。如果要观察数据集的表格,很难一眼看出这个变量应该被视为连续变量还是分类变量。但是如果知道这些数字表示的是就业状况,那么很明显它们是不同的状态,不应该用单个连续变量来建模。
pandas的get_dummies函数将所有数字看作是连续的,不会为其创建虚拟变量。为了解决这个问题,可以使用scikit-learn中的OneHotEncoder,指定哪些变量是连续的、哪些变量是离散的,也可以将数据框中的数值列转换为字符串。
为了说明这一点,我们创建一个两列的DataFrame对象,其中一列包含字符串,另一列包含数字:
python
demo_df=pd.DataFrame({'Tnteger Feature':[0,1,2,1],
'Categorical Feature':['socks','fox','socks','box']})
display(demo_df)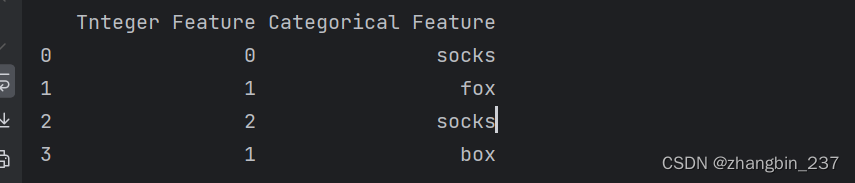
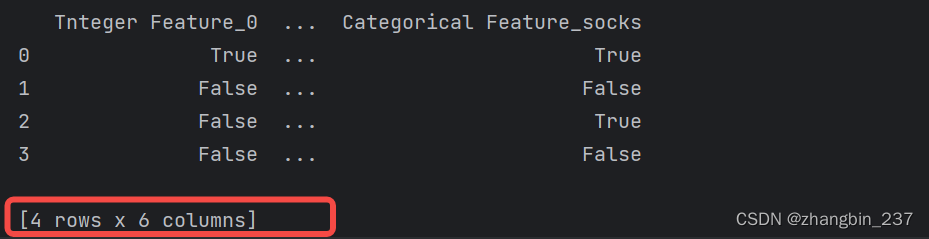
使用get_dummies只会编码字符串特征,不会改变整数特征:
python
pd.get_dummies(demo_df)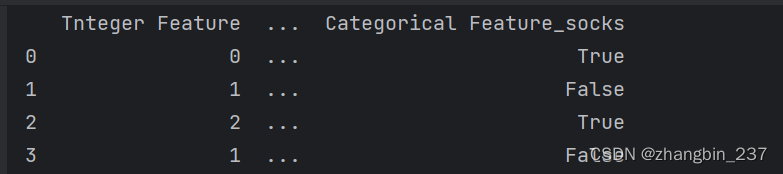
如果想为"Integer Feature"这一列创建虚拟变量,可以使用columns参数显式地给出想要编码的列,于是两个特征都会被当作分类特征处理: