前言:近日,OpenAI的首个文生视频模型Sora横空出世,引发了一波Sora热潮。与其相关的概念股连续多日涨停,多家媒体持续跟踪报道,央视也针对Sora进行了报道,称这是第一个真正意义上的视频生成大模型。
01
Sora 打破了现实世界与虚拟世界的边界
Sora模型是OpenAI继文本、图像后,在视频领域的再次技术拓展。Sora可根据用户的文本指令输出长达60秒的视频内容,截至目前为止,Sora官方网站上已更新48个视频demo。与其他的视频生成大模型输出的画面相比,Sora输出的视频内容更加逼真,视频细节、色彩、画面、转场处理更加细致生动,让人如临其境,难以区分是虚拟还是现实。
除了支持文字生成视频外,Sora模型也支持文字+图片、文字+视频、视频+视频的方式创作新的视频内容。还可以对现有的视频或者图片进行帧填充,将图片或者视频原有的时间和空间进行拓展延伸。
Sora模型的出现打破了虚拟世界和现实世界的边界,在OpenAI发布的技术报告中认为,Sora是现实世界的模拟器,它的出现为实现模拟真实世界模型,找到了一条可行的路。
02
Sora的技术理念
在发布Sora这一新技术的同时,OpenAI也将其详细的技术报告一并发布。在报告中,Sora详细阐述所利用的设计理念和技术原理,Sora在实现过程中,主要利用了Diffusion model(扩散模型)+ Transformer两种技术架构的结合。
一、Diffusion model:是一种生成模型,用于图像的生成。
二、Transformer: Transformer结构是一种深度学习模型的架构
这里我们重点聊一下Transformer结构,Transformer结构是Sora核心模块,最初是为了改进机器翻译任务而设计的。现在,它被广泛应用于各种不同的领域,包括Sora的其它几个组件,图片字幕模型、视频和图片压缩模型,以及Sora扩散模型。
用一句话概括Sora扩散模型的实现过程:将原视频训练素材压缩后给Sora学习,学习如何将压缩后的视频内容还原和生成新的视频。
这里包含了两个关键步骤:Encoder-编码、Decoder-解码。
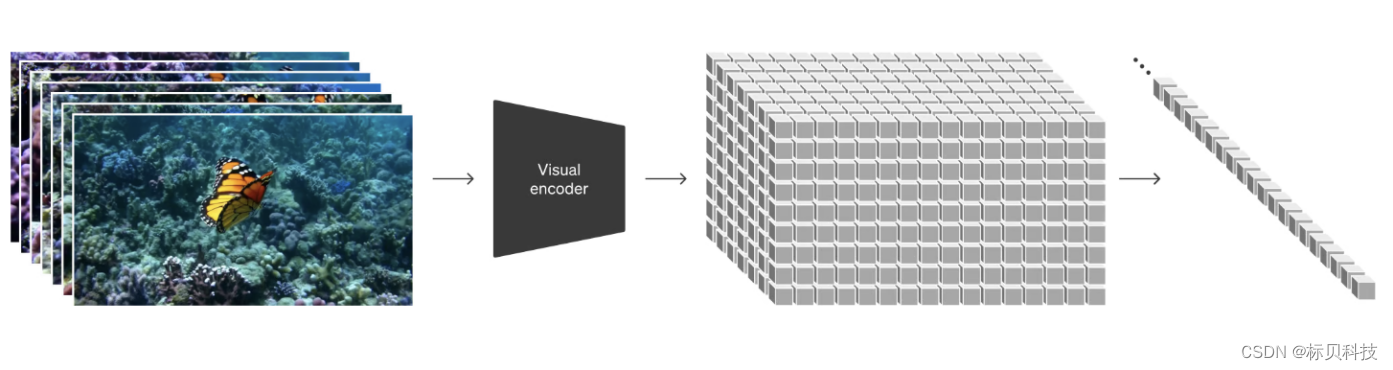
- Encoder
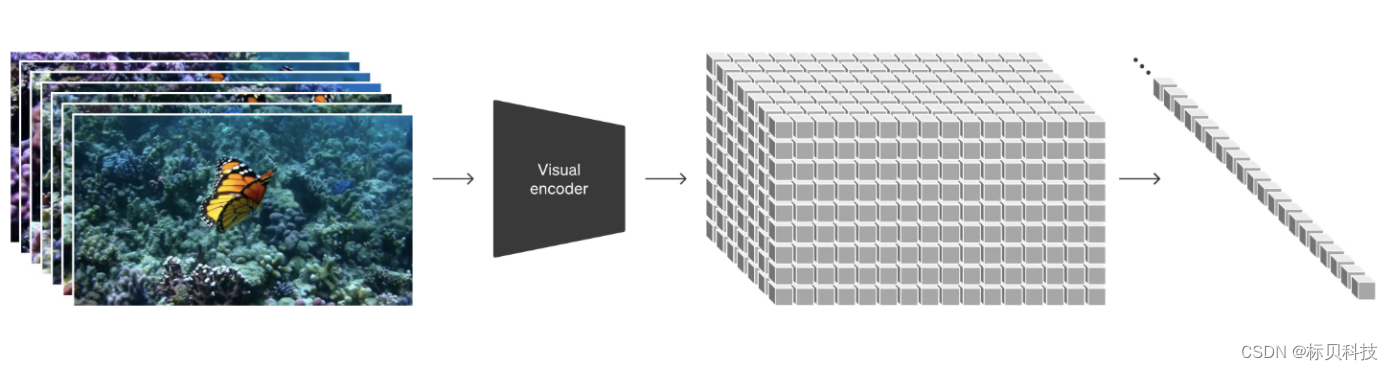
Encoder就是将原视频进行压缩,压缩至一个低维度的空间,压缩后视频充满了噪点,Sora就是学习压缩后的数据。
- Decoder
Decoder就是将压缩后的视频进行还原或创造,恢复至高清的像素空间。
OpenAI认为,Sora的诞生建立在过去对DALL:E和GPT模型的研究基础上。Sora使用了来自DALL:E3的字幕技术,使得该模型能够更忠实地遵循用户在生成的视频中的文本指令。DALL:E3的字幕技术涉及为视觉训练数据生成高描述性字幕,这项技术可以有效提高文本的保真度及视频的整体质量。
03
Sora背后的数据支持
Sora模型的成功依赖海量高质量数据和与之相匹配的视频内容的匹配性和大量反复性训练。Sora模型的文生视频能力是通过通过深度学习和大规模的训练数据结合而来的。其诞生的基础是大量的数据采集以及数据训练。
通过Sora技术原理可以发现,Sora的训练起始于对大量视频数据的收集与标注。在这些数据中,有的视频已经附有标注信息,而其他一些则没有。这些数据为Sora提供了学习和理解多样化视觉内容的基础。标贝科技自有大规模、高质量通用场景视频描述成品数据集近百万段,内容涵盖广泛,可以满足各种模型数据训练的需求。
标贝科技拥有大量的满足客户需求的文生视频数据集,这些视频数据内容要求涵盖主体数量、主体各表向因素以及主体情绪、姿态、方位、场景等重要逻辑关系文本描述内容。为研发人像类领域文生视频模型提供高质量的数据支持。
尽管Sora在视频生成领域产生了突破性的进展,然而在面对空间感知能力等方面,仍呈现不足。但国内已有应用针对逻辑关系理解不足等问题进行着重训练。
04
结语
Sora的出现,让我们再一次领略了人工智能带来的无限可能。其在视频领域展现出了巨大的应用潜力。AI技术的进步将推动着各个行业向着更高端、更创新的方向快速发展。标贝也继续深耕大模型和小伙伴们协力成长,共同助力AI领域服务人类生活。