本文核心观点:
- 基于大模型的 AI 原生应用将越来越多,容器和微服务为代表的云原生技术将加速渗透传统业务。
- API 是 AI 原生应用的一等公民,并引入了更多流量,催生企业新的生命力和想象空间。
- AI 原生应用对网关的需求超越了传统的路由和负载均衡功能,承载了更大的 AI 工程化使命。
- AI Infra 的一致性架构至关重要,API 网关、消息队列、可观测是 AI Infra 的重要组成。
大家好,我是阿里云云原生微服务技术负责人李艳林,我所在的团队是做云原生应用的架构、开发和运维的,并以开源和云产品的方式服务广大开发者和企业客户。随着大模型的流行,我们看到了越来越多 AI 原生的应用,因此做了非常多的实践。今天我将分享一些实践中的感悟。
- AI 给业务带来了哪些变化?
- AI 给应用和架构带来了哪些变化?
- 我们正在探索的实践场景。
AI 到底给我们带来了哪些变化?

工业化时代,我们利用工具解放了手脚,从忙碌的体力劳动中释放出来。大模型时代,我们利用 AI 释放了部分脑力劳动,从忙碌的重复劳动中释放出来。例如程序员群体利用通义灵码等智能编码助手,就可以搞定代码注释、单元测试,甚至一些简单的程序。
现在一些早期的程序员,包括我在内,上大学的时候学的都是自动化,那时候的编程范式是面对机器进行汇编。我不知道今天来现场的人是否写过汇编,应该很多年轻人是没写过汇编的。
汇编就是人类用计算机能识别的语言和计算机进行对话,但如今我们已经开始用自然语言和计算机对话了,这给人机对话效率带来了革命性的改变,同时对程序员的思维模式也是一种改变。大家都知道,用计算机语言和计算机对话多了,自己的思考方式也会很计算机,失去了生活的灵性,大家肯定听过不少吐槽程序员思维方式的段子。
以自己为例,我上大学的时候,讲成语是信手拈来,但工作了十年,现在连说个成语都费劲了。就是因为天天跟机器打交道,整个人都变得很机械了。但如果是通过自然语言进行编程,那就是驱动机器像人一样思考,机器会越来越接近人的思维方式。例如我们对微服务进行拆解,拆解成订单服务、会员服务,是指令性编程,AI 时代就是声明式编程,只需要告诉计算机你的最终诉求,而不需要考虑过程指令。
前阵子参加了InfoQ 组织的 AI Agent 的小型交流会,大家讨论的焦点之一是我们当前是高估了 AI 的能力,还是低估了 AI 的能力。按我的实践来看,短期是高估了,长期是低估了。未来,AI 会进一步把我们从重复的工作解放出来,想象力真的是无限的。
但是,为什么今天大家所期待的和当时 APP Store 出现时那样,AIGC 应用的蓬勃发展并没有出现?本质是 AI 的拐点还没有到。
第一个原因是大模型的理论研究还不够透彻,深度学习网络仍是一个黑盒。 大家只是信仰 Scaling Law 会实现 AGI,不过这并不影响应用场景的落地。举个例子,历史上我们在没有研究透火的原理之前,其实已经用火来推动了人类的发展历程了。大模型发展至今,已经在代码工程、客服、信息搜索、设计等领域落地了大量生产场景。
第二个原因是算力限制和投入产出的考量。 我不知道今天在场的多少家公司买了 GPU,在大模型上投入了多少费用,但是产出是否能带来足够的经济效益。好消息是各个云厂商大幅降低了大模型的训练和推理成本,很多公司的 ROI 就立马转正了。另外,AI Infra 在资源利用率、研发效率、业务稳定性上的成熟度远不如云原生的这套基础设施,也缺少开源、商业产品等带来的最佳实践。例如用 GPU 每次调用做一次搜索区间的成本更高,这些都对拐点的到来会产生影响。
第三个原因是合规性、价值观对齐、算法偏见和公平性等的约束。 没有这些约束,大模型就会衍生出大量的社会问题、道德问题等。我们和做大模型落地的企业聊,好奇为什么你们在 AI 上落地了这么多场景,为啥外边看不到呢?原因就是要保证合规,放慢了应用上线的节奏。

GPU 和 CPU 正在相互融合,摩尔定律决定了 CPU 性能每两年提升1倍,但 GPU 的性能每两年能增加10倍。未来10年,GPU 性能能提升100倍,成本持续下降,如果每个手机都内置一个 GPU,在端上进行推理,那对 AI 的落地会是非常大的推进。在座的各位都见证了 CPU 给我们生活带来的变化,我相信演进速度更快的 GPU ,会给我们这个时代带来更大的变化。
AI 给应用和架构带来了哪些变化?
有人会问,AI 时代,应用和应用架构发生了哪些变化,我们从下方这个图来看下演进过程。

左边是以容器、微服务、声明式 API 构成的云原生应用架构 ,这是当下构建在线应用的主流架构,比如电商业务、金融业务、SaaS 服务、社交应用、交通物流等,我想大部分企业都已经采用了这套架构,或者至少已经有一部分业务跑在这套架构上。右边是以大模型、AI Agent、面对自然语言编程 构成的 AI 原生应用架构 ,更大的概念是 AI Infra,采用 GPU 资源进行模型的训练和推理,并以模型和自然语言为核心,驱动业务发展,而承接端侧的流量,不再是一个个微服务,而是一个个 Agent,以后人手一个 Agent 的时代相信离我们不会太远。整体上,我们认为基于大模型的 AI 原生应用将越来越多,容器和微服务技术为代表的云原生技术会加速渗透传统业务,并引入更多流量,催生企业新的生命力和想象空间。
那么 AI 原生应用架构有什么特点呢?
以模型为核心、Agent 进行驱动、面对自然语言编程为 AI 原生应用架构的核心要素,"API First"、"Agent 编排" 、"消息解耦"、"AIOps"是架构 AI 原生应用的核心理念。

API First
第一是 API First,API 成为 AI 原生应用的一等公民。现在每家企业都做降本增效,降本很好衡量,就是用 IT 支出,减少计算设备、提升算力利用率,优化数据存储,但是效率提升要用数字来做显性化衡量就比较难。我们实施敏捷开发的时候,会引入 DevOps、低代码、AI 编程,提效是提效了,但是如何用标准化的方式来衡量呢?人均产出么?计算方式过于复杂,口径不一,影响因子太多。
API First 在国外其实已经非常火、市场接受度也很高,因为以往在线应用都是通过 Service 对外暴露提供服务能力,但是基于大模型的 AI 原生应用将会通过 API 对外提供服务能力,因此,企业的数字化资产管理和上下游生态,均会基于 API 标准来构建。但国内仍处于布道期,我们都是 Code First,前后端各自把代码写好,然后怼在一起,反复修改调试,协作效率不高,业务规模越大,技术债越重。API First 则是先定义好 API 规范,再 code,并能借助 AI 来自动生产代码、自动化单元测试,甚至包括攻防演练的代码、前端代码等,都能自动搞定。API 定义世界,AI 生成世界,API 会成为企业的核心资产,并作为衡量效率的标准化方式。
此外,大量的非 AIGC 应用例如物流系统、体育赛事、娱乐活动、天气信息等,作为 Agent 编排的被调用方,将加速把规范 API 设计提上日程,避免接口调用的兼容性问题,改变 Code First 的开发习惯、提升开发效率,融入 AIGC 大生态。
Agent 编排
OpenAI 的 API 日调用量已经超过国内一线互联网公司的日活用户数,但是今天围绕 API First 的后端协同还未发生变化。大部分企业仍然是用信息聚拢的方式,来提供搜索结果。当 API 成为企业服务用户不可或缺的方式后,将会产生大量的 AI 原生应用,对各家的 API 进行智能编排,提供更加智能的服务。因此,Agent 编排将成为 AI Engineering 领域必不可缺的一环。
简单的场景只需要单 Agent,结合提示词优化和提示词模版就可以解决,但是例如 AI 工程师的场景,就需要多个 Agent 做编排和协同,以便于解决复杂问题。 从 Agent 角色上看,需要 PD Agent、研发 Agent、测试 Agent 等组合,才能做好协调,最后得到整体结果的提升。再举一个生活中的例子,我们要做一个团建计划,现在的做法是小红书找旅游攻略,然后同飞猪去看火车票和机票,再找合适的酒店,还要去点评找饭店。以后可能只需要做好提示词工程,例如输入团建的时间、地点、人数,以及其他定制化需求(团建额度、表格对比输出...),就能直接给出团建方案了,甚至由 AI 以一问一答的方式来引导我们输入提示词,进一步降低自然语言对话的门槛。
Langchain 已经提供了面向 Python 开发者非常友好的 Agent 的编排能力,对于国内占比 65% 的 Java 开发者群体,我们将基于 Spring AI 帮助 Java 程序员快速掌握 AI 编程能力。
消息解耦
第二是消息解耦。我不知道大家做 AIGC 开发的时候,平均 RT 大概多少?有能做到延迟 3 秒以下的么?早期文生文的时候,没有机制去实时检索和整合训练集外的知识,RT 是比较低的。但是 RAG 技术出现后,除了在库内进行检索,还会基于大模型利用更加具体和即时的信息,来提升输出内容的准确性和实效性。信息传输过程中的报文是非常大的,推理对算力的消耗也非常大。例如通义在春节期间上线过一个全民舞王,视频生成的 RT 是非常高的,要等10几分钟。
另外,大模型推理链路中,会涉及图片、视频消息的传输,存在消息体大小限制过低的痛点。所以如何通过消息解耦来降低 RT,并支持更大的消息体,都是 AIGC 应用必然会应用到的技术。 并且,面对大模型或大数据量,消息量显著增加,AI 开发者不仅需要通过架构演进降低消息队列成本、提升消息队列的数据处理能力,还需要完善消息队列运维体系的建设,确保系统的稳定性和可靠性。
AIOps
第三是 AIOps。这里的 AIOps 是指 OPS for AI,而不是 AI for OPS。我们提炼三个应用场景。
- 模型优化:大模型普遍依赖数据、训练、部署、验证、调优等,需要做到对大模型生命周期的全方位了解以及问题发现,从而制定优化策略。
- 模型选择:选择合适的大模型并判断其实际效果,通过访问跟踪数据,可以轻松地将各种请求路由到不同的 LLM 模型并衡量其性能和成本。
- 模型应用:LLM 应用的生命周期还会和很多工具或者组件进行交互,包含 Prompt 调优、输入输出,模型调用、RAG、用户交互、效果评估、成本费用、故障排查等多方面。
以模型应用的故障排查的场景展开为例,目 前大部分 LLM 应用都是单体架构,提供独立的交互入口,虽然应用架构相比微服务简单很多,但是入口应用到后端应用和模型,失败率较高,排查代价非常大,缺少成熟的可观测技术和实践。 之前我拜访过一家大模型企业,他的报文非常大,日志经常打不起来。这里要是用 Java 那一套可观测体系肯定是搞不定的,因此我们正在开发 Go 和 Python 的 Agent 技术,去完善 LLM 应用的可观测生态。
API 网关
AI 原生应用,对网关的需求已经超越了传统的路由和负载均衡功能,还需要为 AI 应用开发者提供便利,例如统一不同 LLM 提供商的 API 协议,并提供 API 编排、安全、稳定性和成本控制等扩展功能。因此 AI 时代,网关承载了更大的工程化使命,需要在网关侧做好 AI 场景的深度扩展和集成。
阿里云网关开源项目 Higress 升级为 AI 原生的 API 网关,提供了丰富的 AI 插件扩展 和 生态集成, 让开发者一键构建 AI 应用。Higress 在支撑通义、云产品 PAI 和百炼的过程中,积累了大量 AI 应用工程话的能力,下面我们将详细介绍。
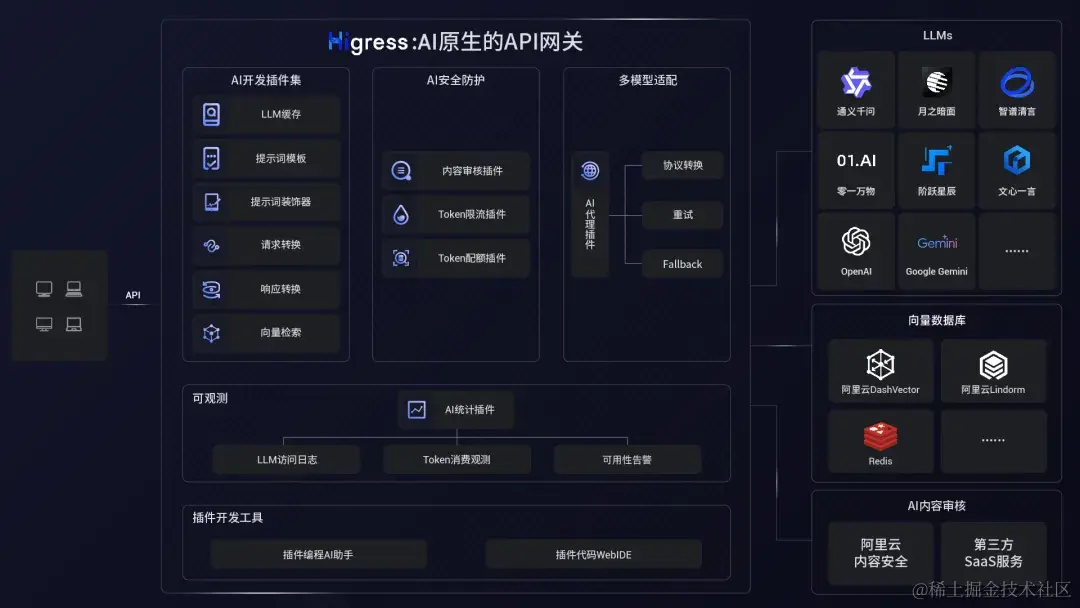
热更新场景
在 AI 原生应用架构中,网关上都是长链接,没短链接了,基本采用的都是 SSE 协议 或者 WebSocket。因为文生文的过程中,都是砰砰自动的连续性生成。此时,网关的热更新能力对用户体验就非常关键了,如果还是用传统的 Nginx 网关,每次更新网关都要 reload,对应用有感,那会很影响用户的体验。我们开源的 Higress 网关(商业产品是阿里云 MSE),就可以实现证书的变更、路由规则的变更、插件的变更,都是热更新的,对长链接无损。

安全防护和敏感词过滤场景
Higress 网关的另一个优势是处理大报文时的内存消耗非常少。传统的 Nginx 网关处理大报文会有 OOM 内存溢出的问题,我遇到过一个客户,一开始用的就是 Nginx 网关,就出现了把内存踩爆的情况。其他的例如敏感词过滤、安全防护等,都会基于网关来实现,因此在 AI 原生应用架构下,网关承载了更多的业务需求。
流控场景
我们的企业客户有时候都是诚惶诚恐的。每年耗费几十几百万采购云计算资源,黑产可能只需要几百几千 QPS 就能搞垮你的系统,甚至迁移走你的数字资产。AI 时代,客户屯的 GPU 资源越来越多,黑客攻击轻轻松松就把 GPU 资源跑满,资产损失大幅提升。因此,在网关入口做整个的流量防护和安全防护,意义和必要性会变得更大。Token 级别的流控、IP级别的流控,以及面向全链路的观测体系,就显得非常关键了。但我们现在看到的是围绕 GPU 的配套体系,效率是非常低的。
负载均衡场景
不同的场景,对 GPU 的消耗量是不同的。有的场景只需要一张卡,文生视频就需要多个卡并行去处理。在 CPU 场景,我们通过容器的调度技术提升计算资源的利用率,GPU 场景还没见成熟的资源调度方案,因此负载均衡对 GPU 的利用率提升就很关键了。我们有一个客户,手里有几百张卡,有的卡负载很高、有的卡负载很低,导致大量的闲置资源,没法充分的压榨 GPU。然后我们基于长链接后端的最小负载进行优化,通过长链接的负载均衡技术,慢慢优化 GPU 的利用率。常规的文生文、文生图的场景都可以通过网关的负载均衡,再结合重试和容错功能,来提升利用率。
目前阿里的通义系列、云产品百炼和 PAI,外部用户 Sealos、Lepton.ai 都跑在了我们的 Higress 网关上。比如说 Sealos,他的开发者用户已经非常多了,一个用户一个模型,模型特别多的时候,网关的域名就非常的多,会影响推送性能。因此他们用 Higress 网关实现按需订阅、差量推送,来降低大批量域名对网关的消耗。
AI Proxy
上面我们讲了网关的 4 个典型场景,接着我们来看下 AI Proxy。今天搞大模型的公司毕竟是少数,更多的企业是基于大模型做应用的落地,去对接多个大模型,例如通义GPT、通义、还有 Google 的羊驼等。但是不同模型的通信协议是不一致,身份体系也不同。
第一类需求,以 Sealos 为例,他优先调用的是 GPT,次选是通义,使用 Higress 网关就可以在 GPT 调用失败的时候实现容错,来调用通义。第二个需求,很多大型企业主账号接入了大模型,给每个员工开通一个使用的子账号,并可以对每个子账号开放或屏蔽模型类型进行自由选择,同时提供体验一致、高可用的服务,这个就是通过 Higress 网关的统一身份的能力来实现的。

Spring AI
在中国,差不多 65% 的后端程序员都是搞 Java 的,我们在 Java 领域也有比较深厚的积累。这里介绍下我们在 AI Agent 开发框架上的进展。左边是 Spring AI 最基础的模拟模型的对接部分,右边是 RAG 能力,最上面是 Spring AI 和 Langchain 的对比和差异,并通过 Langchain 组装不同的 Agent 进行协调,这些都已经开发完成,建议大家去 sca.aliyun.com 来体验下。
很多公司基于 Langchain 的链式能力已经可以做些拖拖拽拽、低代码的事情,像包括阿里云的百炼,对于模型的训练、部署都是非常简单的。后续我们会把 AI 相关的更多工程化能力,通过 Spring AI 对接起来,方便广大 Java 开发者。

以上只是 AI 应用的应用架构视角,若从 AI Infra 的视角看,还有计算、存储、网络、操作系统等,这些构成了完整的 AI Infra,而 AI Infra 的一致性架构至关重要, 这里暂不展开,网关、消息队列、可观测是 AI Infra 的重要组成。
我们正在探索的实践场景
基于 AI 的实践场景很多,选择哪个先落地的商业判断很重要。一类是只解决 50% 的问题,但是可用性 100%。另一类是解决 80% 的问题,但是可用性只有 60%,这是不同的选择。
举个例子,我们让 AI 把网关的插件全部写了,如果网关层出问题,这个锅是谁的?网关的容错性很低,目前这个阶段,显然是不能靠 AI 解决的。这就像汽车的自动驾驶能力,我理解很长一段时间内,都是起到辅助驾驶的功能。因此,我们更倾向于用 AI 解决的是结构性强、容错性高的场景。

所以我们优先上线的场景是在 Spring Cloud Alibaba 的官网,和通义深度集成,构建了一个 AI 答疑工程师。使用 Spring Cloud Alibaba 过程中遇到的开发问题或难题,都可以向这个 AI 答疑工程师进行提问,我们现在每天有几百个 ID 在和 AI 答疑工程师进行交互,问题的解决率可以达到 90% 以上。 然后,我们有一个后台能持续的去完善答案。有数据、有场景、能根据实际的反馈去完善答案,形成正循环。这就是一个真正管用的 AI 工具的基本三要素。
开发者 AI 答疑工程师,我们经历了 3 种选型。

- 提示词增强模式:早期我们用的是提示词增强模式。通义 1.0 的时候,模型能力还比较弱,使用提示词对答疑效果帮助非常大。但随着 2.0、2.5 的出现,最新已经是 3.0 了,我们发现提示词对结果的优化价值越来越弱化,因为模型能力在不断增强,上面每一层做的价值其实都在被弱化。
- 微调:理想情况是我们希望 AI 答疑工程师每天都能提升答疑能力,实现快速迭代,但是每一次微调的资源成本是比较高的。
- RAG:先把所有的开源信息和语料,基于通义完成训练,然后把开发者输入的 Top 问题整理出来,压缩后再给大模型进行抽链,来获得更好的答疑效果。
这是我们 AI 答疑工程师的架构图,相比传统答疑系统的几万行代码,我们的代码只有几百行,其中很多还是基于通义灵码生成的,不到一周就搭完了,这就是大模型给我们带来的技术红利。如果再通过百炼这种易用性更高的大模型开发平台,效率可能比自己写代码效率更高,适用群体还更广泛。

这个架构图里,我们入口网关选择的 MSE 云原生网关,在入口建立安全、高可用的防线,解决一些敏感词过滤的问题,然后在应用管理这层是选择了 SAE,他是免运维的,后端接的是通义2.5的大模型。所以总的来看,构建应用的代码少了、构建应用需要的人力少了,整个开发运维效率都提升了,然后大模型的调用成本在不断下降,能力在不断演进,我的应用可以持续享受用户体验提升的红利。整个过程的感受是非常震撼的。因此,我认为从云原生架构到 AI 原生架构的演进,会持续加速。
未来计划
Spring AI
我们会把 RAG 的能力近期对外开放,并陆续发布已经沉淀的 Java 版的 Langchain 能力,这对国内广大 Java 开发者是一大福音,很方便的基于 Java 大模型应用。欢迎访问 sca.aliyun.com。
AI 网关
我们会逐步发布 Higress 的 API 自动设计能力、测试代码的自动生成能力和插件的自动生成能力。欢迎访问 higress.io。
点击此处,下载专场资料合集。