文章目录
文章目录
- [00 写在前面](#00 写在前面)
- [01 SVM算法简介](#01 SVM算法简介)
- [02 SVM算法的基本原理](#02 SVM算法的基本原理)
- [03 基于Python 版本的SVM算法](#03 基于Python 版本的SVM算法)
- [04 优化目标表达式理解:](#04 优化目标表达式理解:)
- [05 约束条件表达式理解](#05 约束条件表达式理解)
00 写在前面
SVM算法可以结合鲸鱼算法、飞蛾扑火算法、粒子群算法、灰狼算法、蝙蝠算法等等各种优化算法一起,进行回归预测或者分类预测。
01 SVM算法简介
支持向量机(Support Vector Machine, SVM)是一种用于分类和回归分析的监督学习模型。SVM的基本思想是通过寻找一个超平面,将不同类别的样本进行最大间隔分离。SVM在高维空间中表现出色,特别适用于小样本、非线性及高维数据的分类。
02 SVM算法的基本原理
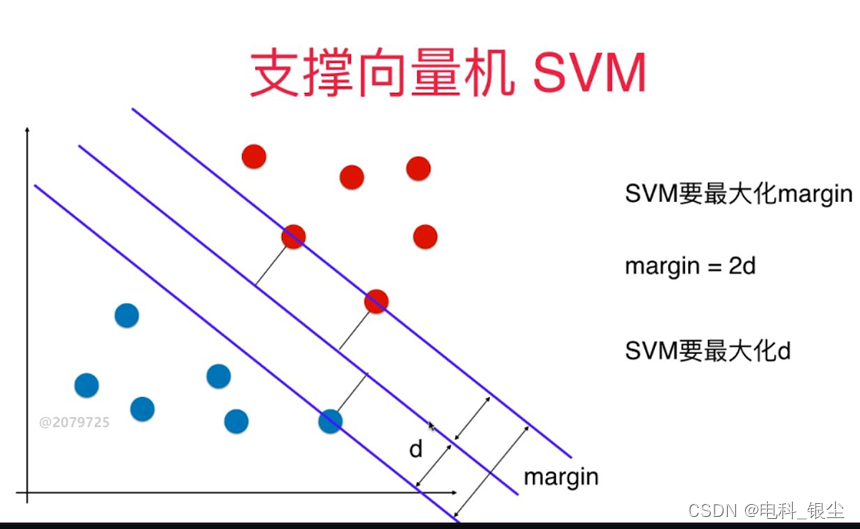
SVM的核心目标是找到一个最优分离超平面,使得不同类别的样本之间的间隔(margin)最大化。SVM分为线性SVM和非线性SVM。
线性SVM
对于线性可分的数据集,SVM通过找到一个线性超平面来分离两类数据。假设我们有一个训练数据集 ( x i , y i ) (x_i, y_i) (xi,yi),其中 x i x_i xi 是特征向量, y i ∈ { − 1 , 1 } y_i \in \{-1, 1\} yi∈{−1,1} 是类别标签。SVM要找到一个超平面:
w ⋅ x + b = 0 \mathbf{w} \cdot \mathbf{x} + b = 0 w⋅x+b=0使得所有正类样本和负类样本的间隔最大化。
目标函数 :
min w , b 1 2 ∥ w ∥ 2 \min_{w,b}\frac{1}{2} \left \| w \right \| ^{2} w,bmin21∥w∥2
约束条件 :
y i ( w ⋅ x i + b ) ≥ 1 , ∀ i y_i (\mathbf{w} \cdot \mathbf{x_i} + b) \geq 1, \quad \forall i yi(w⋅xi+b)≥1,∀i
通过求解上述优化问题,得到最优的权重向量 w \mathbf{w} w 和偏置 b b b,从而确定最优分离超平面。
非线性SVM
对于线性不可分的数据集,SVM使用核函数(Kernel Function)将数据映射到高维空间,使得在高维空间中可以找到线性可分的超平面。常用的核函数包括:
-
多项式核(Polynomial Kernel):
K ( x i , x j ) = ( x i ⋅ x j + c ) d K(x_i, x_j) = (\mathbf{x_i} \cdot \mathbf{x_j} + c)^d K(xi,xj)=(xi⋅xj+c)d -
高斯核(RBF核,Radial Basis Function Kernel):
K ( x i , x j ) = exp ( − γ ∥ x i − x j ∥ 2 ) K(x_i, x_j) = \exp(-\gamma \|\mathbf{x_i} - \mathbf{x_j}\|^2) K(xi,xj)=exp(−γ∥xi−xj∥2) -
Sigmoid核:
K ( x i , x j ) = tanh ( α x i ⋅ x j + c ) K(x_i, x_j) = \tanh(\alpha \mathbf{x_i} \cdot \mathbf{x_j} + c) K(xi,xj)=tanh(αxi⋅xj+c)
使用核函数后,SVM的目标函数变为:
min w , b 1 2 ∥ w ∥ 2 + C ∑ i = 1 n ξ i \min_{\mathbf{w}, b} \frac{1}{2} \|\mathbf{w}\|^2 + C \sum_{i=1}^{n} \xi_i w,bmin21∥w∥2+Ci=1∑nξi
约束条件 :
y i ( w ⋅ ϕ ( x i ) + b ) ≥ 1 − ξ i , ξ i ≥ 0 , ∀ i y_i (\mathbf{w} \cdot \phi(\mathbf{x_i}) + b) \geq 1 - \xi_i, \quad \xi_i \geq 0, \quad \forall i yi(w⋅ϕ(xi)+b)≥1−ξi,ξi≥0,∀i
其中, ξ i \xi_i ξi 是松弛变量,允许误分类的样本, C C C 是惩罚参数,控制模型复杂度和误分类的权衡。
03 基于Python 版本的SVM算法
python
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data # 特征数据
y = iris.target # 类别标签
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建和训练线性核函数的SVM分类器
linear_clf = SVC(kernel='linear')
linear_clf.fit(X_train, y_train)
linear_pred = linear_clf.predict(X_test)
linear_accuracy = accuracy_score(y_test, linear_pred)
print(f'Linear Kernel Accuracy: {linear_accuracy:.2f}')
# 创建和训练多项式核函数的SVM分类器
poly_clf = SVC(kernel='poly', degree=3)
poly_clf.fit(X_train, y_train)
poly_pred = poly_clf.predict(X_test)
poly_accuracy = accuracy_score(y_test, poly_pred)
print(f'Polynomial Kernel Accuracy: {poly_accuracy:.2f}')
# 创建和训练RBF核函数的SVM分类器
rbf_clf = SVC(kernel='rbf', gamma='scale')
rbf_clf.fit(X_train, y_train)
rbf_pred = rbf_clf.predict(X_test)
rbf_accuracy = accuracy_score(y_test, rbf_pred)
print(f'RBF Kernel Accuracy: {rbf_accuracy:.2f}')
# 创建和训练Sigmoid核函数的SVM分类器
sigmoid_clf = SVC(kernel='sigmoid')
sigmoid_clf.fit(X_train, y_train)
sigmoid_pred = sigmoid_clf.predict(X_test)
sigmoid_accuracy = accuracy_score(y_test, sigmoid_pred)
print(f'Sigmoid Kernel Accuracy: {sigmoid_accuracy:.2f}')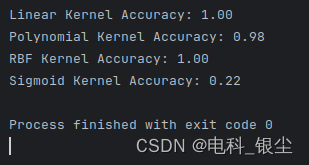
04 优化目标表达式理解:
超平面的一般形式 : 在 (n) 维空间中,超平面是一个 (n-1) 维的子空间。为了更好地理解这一点,考虑几种低维情况:
- 在二维空间中,一个超平面是一个一维的直线。
- 在三维空间中,一个超平面是一个二维的平面。
法向量 w \mathbf{w} w
法向量 w \mathbf{w} w 指向超平面正交(垂直)的方向。法向量的长度 ∣ ∣ w ∣ ∣ \mathbf{||w||} ∣∣w∣∣ 影响分类间隔的大小。
偏置 b b b
偏置 b b b 决定了超平面在法向量方向上的位置。改变 b b b 的值会平行地移动超平面。具体来说,当 b b b 增加时,超平面沿法向量的方向移动,反之亦然。
点 x \mathbf{x} x 到超平面的距离可以通过以下公式计算:
距离 = ∣ w ⋅ x + b ∣ ∥ w ∥ \text{距离} = \frac{|\mathbf{w} \cdot \mathbf{x} + b|}{\|\mathbf{w}\|} 距离=∥w∥∣w⋅x+b∣
这个公式的推导过程如下:
假设有一个超平面,其方程为 w ⋅ x + b = 0 \mathbf{w} \cdot \mathbf{x} + b = 0 w⋅x+b=0。要计算点 x 0 \mathbf{x_0} x0 到这个超平面的距离,我们可以通过以下步骤推导出公式。
- 超平面的几何意义
首先,我们知道一个超平面可以通过其法向量 w \mathbf{w} w 和偏置 b b b 来定义。超平面上的点 x \mathbf{x} x 满足:
w ⋅ x + b = 0 \mathbf{w} \cdot \mathbf{x} + b = 0 w⋅x+b=0
- 投影向量
为了找到点 x 0 \mathbf{x_0} x0 到超平面的距离,我们可以先找到从点 x 0 \mathbf{x_0} x0 到超平面的垂直投影点 x 1 \mathbf{x_1} x1。这个投影点 x 1 \mathbf{x_1} x1 可以表示为:
x 1 = x 0 − λ w \mathbf{x_1} = \mathbf{x_0} - \lambda \mathbf{w} x1=x0−λw
其中, λ \lambda λ 是一个标量,表示从点 x 0 \mathbf{x_0} x0 沿着法向量 w \mathbf{w} w 的距离。我们需要找到合适的 λ \lambda λ 使得 x 1 \mathbf{x_1} x1 落在超平面上。
- 投影点在超平面上
由于 x 1 \mathbf{x_1} x1 在超平面上,所以必须满足超平面的方程:
w ⋅ x 1 + b = 0 \mathbf{w} \cdot \mathbf{x_1} + b = 0 w⋅x1+b=0
将 x 1 = x 0 − λ w \mathbf{x_1} = \mathbf{x_0} - \lambda \mathbf{w} x1=x0−λw 代入得到:
w ⋅ ( x 0 − λ w ) + b = 0 \mathbf{w} \cdot (\mathbf{x_0} - \lambda \mathbf{w}) + b = 0 w⋅(x0−λw)+b=0
展开并整理得到:
w ⋅ x 0 − λ ∥ w ∥ 2 + b = 0 \mathbf{w} \cdot \mathbf{x_0} - \lambda \|\mathbf{w}\|^2 + b = 0 w⋅x0−λ∥w∥2+b=0
解出 λ \lambda λ:
λ = w ⋅ x 0 + b ∥ w ∥ 2 \lambda = \frac{\mathbf{w} \cdot \mathbf{x_0} + b}{\|\mathbf{w}\|^2} λ=∥w∥2w⋅x0+b
- 距离公式
点 x 0 \mathbf{x_0} x0 到投影点 x 1 \mathbf{x_1} x1 的距离即为垂直距离:
距离 = ∥ x 0 − x 1 ∥ \text{距离} = \|\mathbf{x_0} - \mathbf{x_1}\| 距离=∥x0−x1∥
将 x 1 \mathbf{x_1} x1 代入得到:
x 0 − x 1 = x 0 − ( x 0 − λ w ) = λ w \mathbf{x_0} - \mathbf{x_1} = \mathbf{x_0} - (\mathbf{x_0} - \lambda \mathbf{w}) = \lambda \mathbf{w} x0−x1=x0−(x0−λw)=λw
因此,距离为:
距离 = ∥ λ w ∥ = ∣ λ ∣ ∥ w ∥ \text{距离} = \|\lambda \mathbf{w}\| = |\lambda| \|\mathbf{w}\| 距离=∥λw∥=∣λ∣∥w∥
将 λ = w ⋅ x 0 + b ∥ w ∥ 2 \lambda = \frac{\mathbf{w} \cdot \mathbf{x_0} + b}{\|\mathbf{w}\|^2} λ=∥w∥2w⋅x0+b代入得到:
距离 = ∣ w ⋅ x 0 + b ∥ w ∥ 2 ∣ ∥ w ∥ = ∣ w ⋅ x 0 + b ∣ ∥ w ∥ \text{距离} = \left| \frac{\mathbf{w} \cdot \mathbf{x_0} + b}{\|\mathbf{w}\|^2} \right| \|\mathbf{w}\| = \frac{|\mathbf{w} \cdot \mathbf{x_0} + b|}{\|\mathbf{w}\|} 距离= ∥w∥2w⋅x0+b ∥w∥=∥w∥∣w⋅x0+b∣
对于最优分离超平面,两类样本的支持向量(即离超平面最近的样本)满足以下条件:
对于正类支持向量: w ⋅ x + b = + 1 \mathbf{w} \cdot \mathbf{x} + b = +1 w⋅x+b=+1
对于负类支持向量: w ⋅ x + b = − 1 \mathbf{w} \cdot \mathbf{x} + b = -1 w⋅x+b=−1
这些支持向量定义了间隔边界。分类间隔(margin)是这两个边界之间的垂直距离。
对于正类支持向量, w ⋅ x + b = 1 \mathbf{w} \cdot \mathbf{x} + b = 1 w⋅x+b=1,所以到超平面的距离为:
距离 = 1 ∥ w ∥ \text{距离} = \frac{1}{\|\mathbf{w}\|} 距离=∥w∥1
同样,对于负类支持向量, w ⋅ x + b = − 1 \mathbf{w} \cdot \mathbf{x} + b = -1 w⋅x+b=−1,到超平面的距离也是:
距离 = 1 ∥ w ∥ \text{距离} = \frac{1}{\|\mathbf{w}\|} 距离=∥w∥1
05 约束条件表达式理解
-
若 w ⋅ x i + b > 0 \mathbf{w} \cdot \mathbf{x}_i + b > 0 w⋅xi+b>0,则 x i \mathbf{x}_i xi 被分类为正类。
-
若 w ⋅ x i + b < 0 \mathbf{w} \cdot \mathbf{x}_i + b < 0 w⋅xi+b<0,则 x i \mathbf{x}_i xi 被分类为负类。
-
当 y i = + 1 y_i = +1 yi=+1 时, y i ( w ⋅ x i + b ) = w ⋅ x i + b y_i (\mathbf{w} \cdot \mathbf{x}_i + b) = \mathbf{w} \cdot \mathbf{x}_i + b yi(w⋅xi+b)=w⋅xi+b,表示正类样本与超平面的距离。
-
当 y i = − 1 y_i = -1 yi=−1 时, y i ( w ⋅ x i + b ) = − ( w ⋅ x i + b ) y_i (\mathbf{w} \cdot \mathbf{x}_i + b) = -(\mathbf{w} \cdot \mathbf{x}_i + b) yi(w⋅xi+b)=−(w⋅xi+b),表示负类样本与超平面的距离的相反数。
-
约束条件 y i ( w ⋅ x i + b ) ≥ 1 y_i (\mathbf{w} \cdot \mathbf{x}_i + b) \geq 1 yi(w⋅xi+b)≥1 或 y i ( w ⋅ x i + b ) ≤ − 1 y_i (\mathbf{w} \cdot \mathbf{x}_i + b) \leq -1 yi(w⋅xi+b)≤−1能够清晰地定义正类和负类样本相对于超平面的位置关系。
为什么是大于1?(个人理解)
-
最大化分类间隔 :
SVM的目标是找到一个超平面,使得所有数据点到超平面的距离(即 ∣ w ⋅ x i + b ∣ | \mathbf{w} \cdot \mathbf{x}_i + b | ∣w⋅xi+b∣)尽可能大。约束条件 y i ( w ⋅ x i + b ) ≥ 1 y_i (\mathbf{w} \cdot \mathbf{x}_i + b) \geq 1 yi(w⋅xi+b)≥1 确保了正类和负类样本离超平面的距离至少为1。这样做的好处是可以确保分类间隔最大化,因为超平面距离数据点的越远,分类间隔就越大。
-
避免分类错误 :
如果约束条件是 y i ( w ⋅ x i + b ) ≥ 0 y_i (\mathbf{w} \cdot \mathbf{x}_i + b) \geq 0 yi(w⋅xi+b)≥0,则意味着只要数据点在超平面的正确一侧,就被认为是正确分类的。这种情况下,可能会出现分类间隔较小或者出现分类错误的情况,因为数据点可以非常接近超平面而仍然被认为是正确分类的。而约束条件 y i ( w ⋅ x i + b ) ≥ 1 y_i (\mathbf{w} \cdot \mathbf{x}_i + b) \geq 1 yi(w⋅xi+b)≥1 确保了只有在距离超平面足够远的情况下,数据点才被认为是正确分类的,从而提高了分类的准确性和泛化能力。