目录
[sum : 求和函数](#sum : 求和函数)
[prod : 求乘积函数(product)](#prod : 求乘积函数(product))
[cumsum : 计算累积和(cumulative sum)](#cumsum : 计算累积和(cumulative sum))
[diff : 计算差分(difference)](#diff : 计算差分(difference))
[mean : 计算平均值 (average)](#mean : 计算平均值 (average))
[median : 计算中位数](#median : 计算中位数)
[mode : 计算众数](#mode : 计算众数)
[var : 计算方差 (variance)](#var : 计算方差 (variance))
[std : 计 算 标 准 差 (standard deviation)](#std : 计 算 标 准 差 (standard deviation))
[min : 求最小值 (minimum value)](#min : 求最小值 (minimum value))
[max : 求最大值 (maximum value)](#max : 求最大值 (maximum value))
调用函数运算
常见的数学运算函数,例如abs,sin,round,log 等。这些函数可以 直接应用到矩阵上,所表示的含义是:对矩阵中的每个元素分别运用这些数学运算函数,因此 返回的结果也是一个矩阵。下面我们来举几个例子:

除了这些最基础的数学运算函数外,这一小节我们还要学习下表这些使用频率较高的函数, 大家需要熟练掌握它们的用法(点击函数名称可以快速跳转到相应的位置):
sum : 求和函数
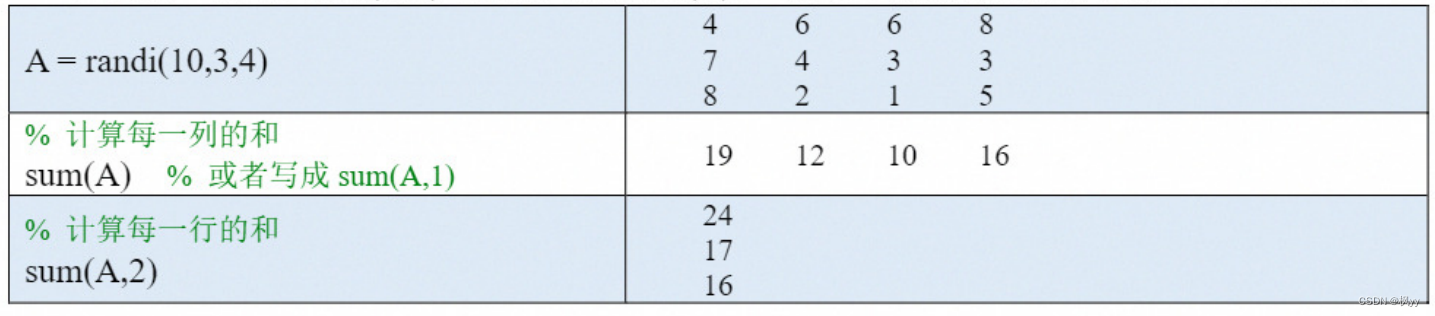
(1)如果A是一个向量,则sum(A)可以计算A中所有元素的和。

(2)如果A 是一个矩阵,则sum(A,dim)可以计算A矩阵沿维度dim 中所有元素的和。
● dim=1表示沿着行方向进行计算,即计算矩阵每一列的和,返回一个行向量;
● dim=2表示沿着列方向进行计算,即计算矩阵每一行的和,返回一个列向量。
当dim=1时,sum(A,1)可以简写成sum(A)。
(3)**计算一个矩阵中所有元素的总和。**可以先用一次 sum 函数计算矩阵A 每一列的和,返回一个行向量;然后再用一次 sum 函数计算这个行向量的和;也可以先使用 A(:) 语句把 A 中的所有元素按照线性索引的顺序拼接成一个向量,然后直接计算这个向量的和。

(4)指定如何处理 NaN 值。NaN 指不定值或缺失值(Not a Number)。默认情况下,求和时有一个元素为NaN 值,那么最终的和也为NaN;我们可以在最后加一个输入参数:'omitnan',这样计算时会忽略NaN值。

prod : 求乘积函数(product)
prod 函数的用法和sum 函数的用法相同,它是用来计算乘积的,我们直接来看例子。

cumsum : 计算累积和 (cumulativ e sum)
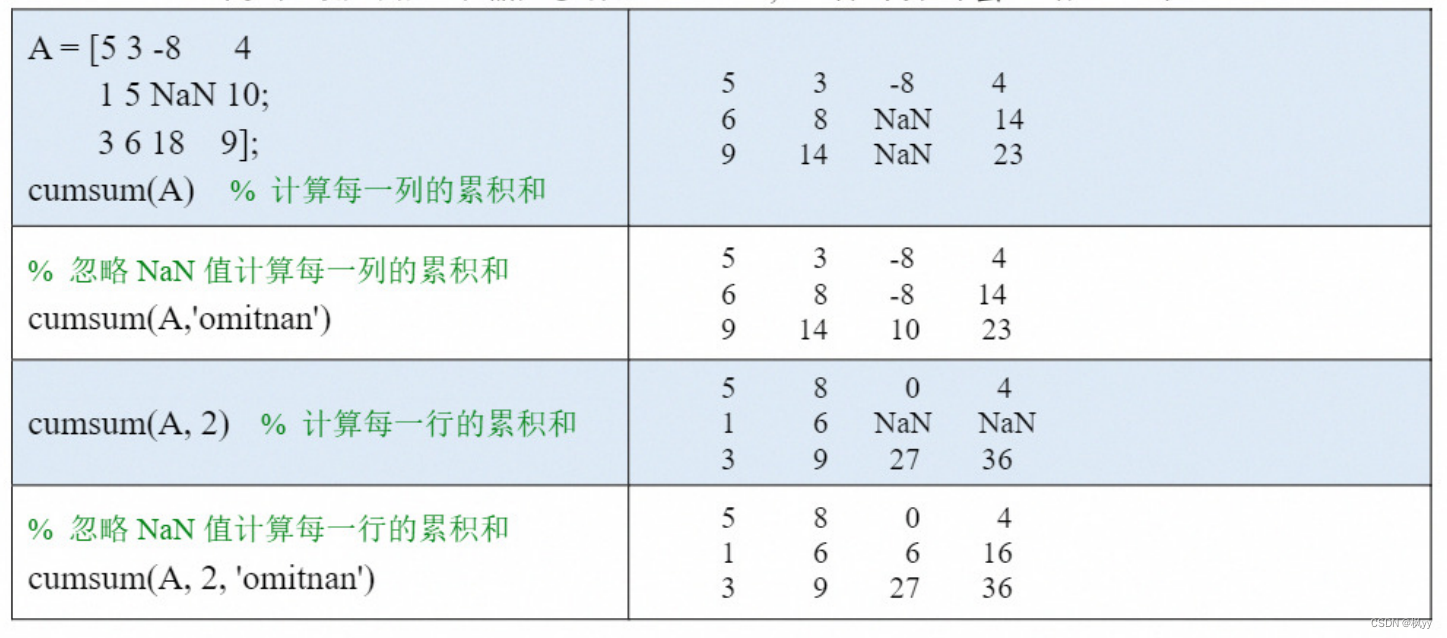
(1)如果A 是一个向量,则cumsum(A)可以计算向量A 的累积和(累加值)。

(2)如果A 是一个矩阵,则cumsum(A,dim)可以计算A 沿维度 dim 中所有元素的累积和,具体的使用方法和sum函数类似。
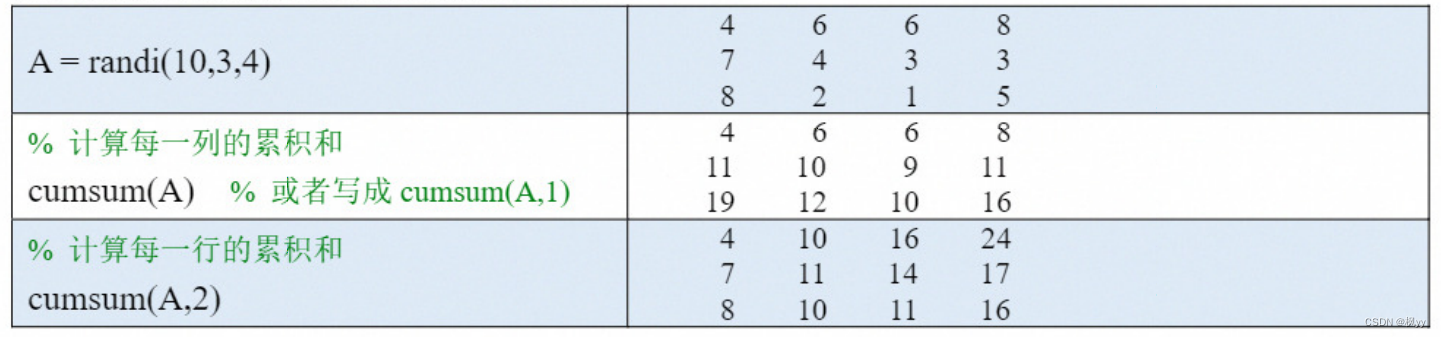
(3)也可以在最后加一个输入参数:'omitnan',这样计算时会忽略NaN值。
diff : 计算差分(difference)
差分运算在和时间相关的数据中用的比较多。在原始序列中用下一个数值减去上一个数值可以得到一个新的序列,这个过程就是一阶差分;在一阶差分结果的基础上再进行一次一阶差分,就是二阶差分,举个例子,下表是8年来的体重变化,我们可以计算一阶差分和二阶差分的结果:

diff 函数也可以用在矩阵上面: diff(A,n,dim)表示沿矩阵A 的维度dim 方向上计算差分, 当dim=1 时沿着行方向计算 ,即得到每列的n 阶差分;当dim=2 时沿着列方向计算,即得到每行的n 阶差分。类似的,dim=1时 ,diff(A,n,1)也可以简写成diff(A,n)。

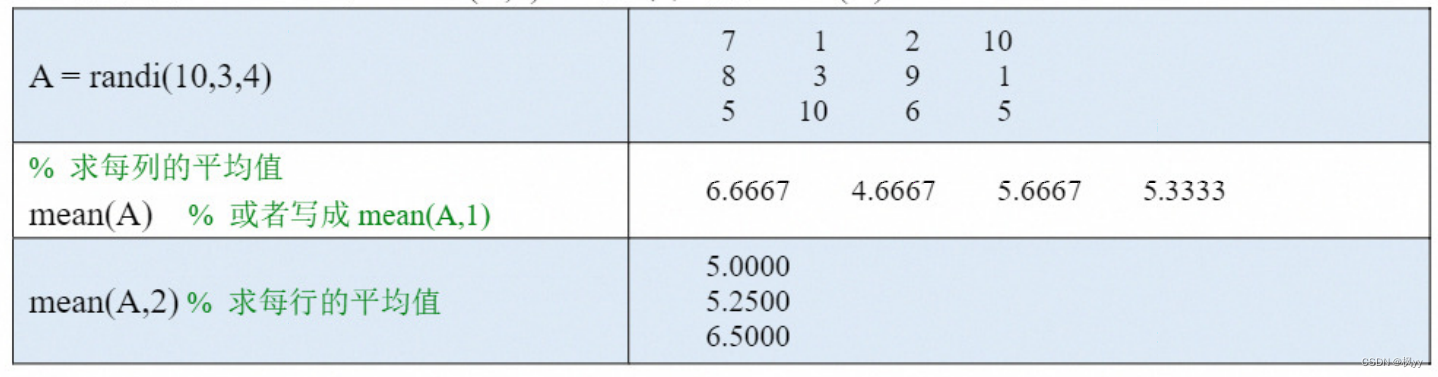
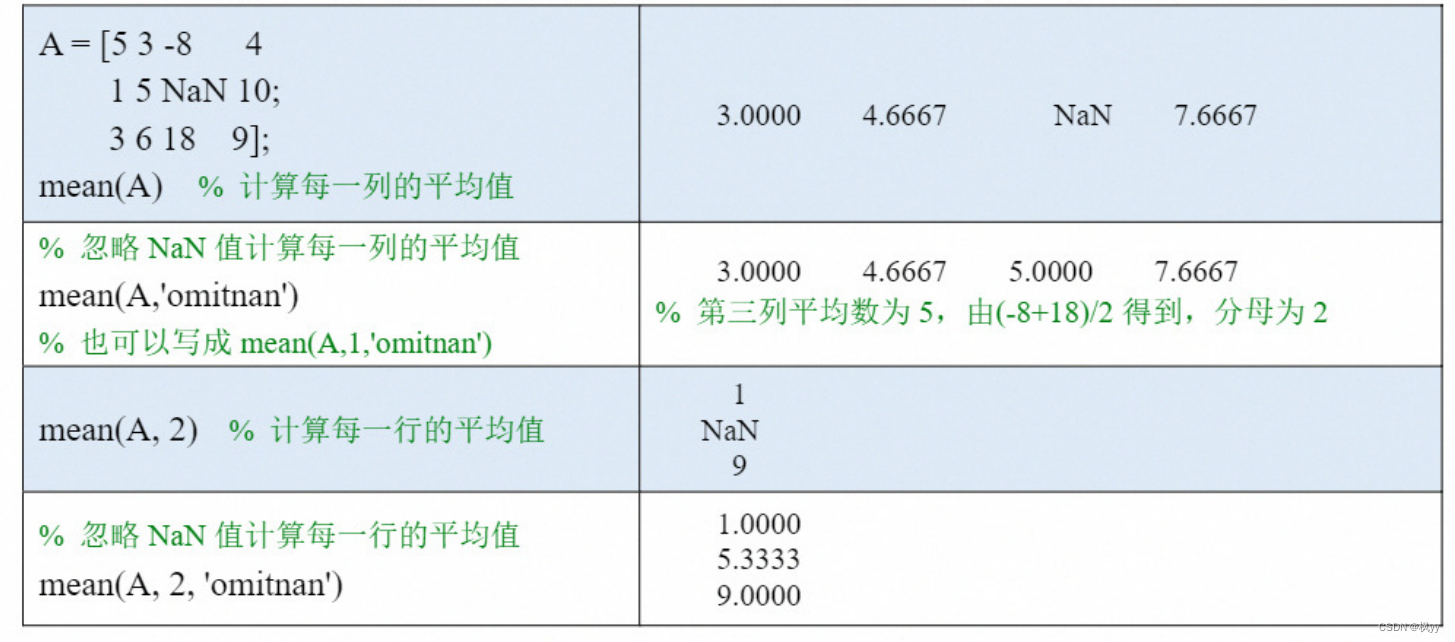
mean : 计算平均值 (average )

(2)如果A 是一个矩阵,则mean(A,dim)可以计算A 沿维度dim 中所有元素的平均值。
● 当dim=1 时沿着行方向进行计算,即得到每列的平均值;
● 当 dim=2 时沿着列方向进行计算,即得到每行的平均值。
类似的,dim=1时,mean(A,1)也可以简写成mean(A).
(3)也可以在最后加一个输入参数:'omitnan',这样计算时会忽略NaN值。
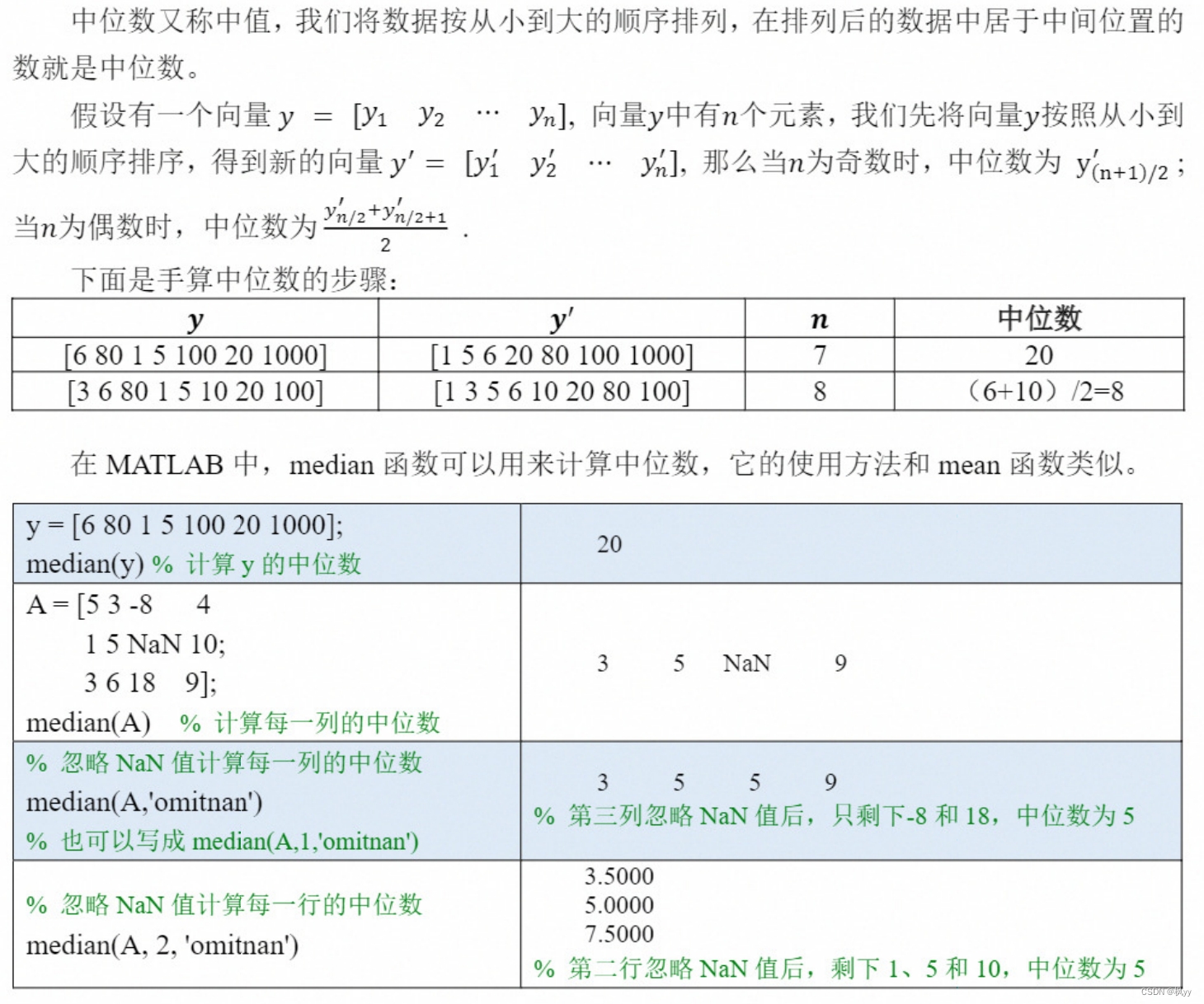
median: 计算中位数
mode : 计算众数
众数是指一组数据中出现次数最多的数。 一组数据可以有多个众数,例如向量1 3 -1 2 1 3 中,1和3都出现了两次,它们都是这组数据中的众数。
MATLAB 中可以使用mode 函数计算数据的众数,调用方法也和 mean 函数类似,但是 mode 函数可以有多个返回值。
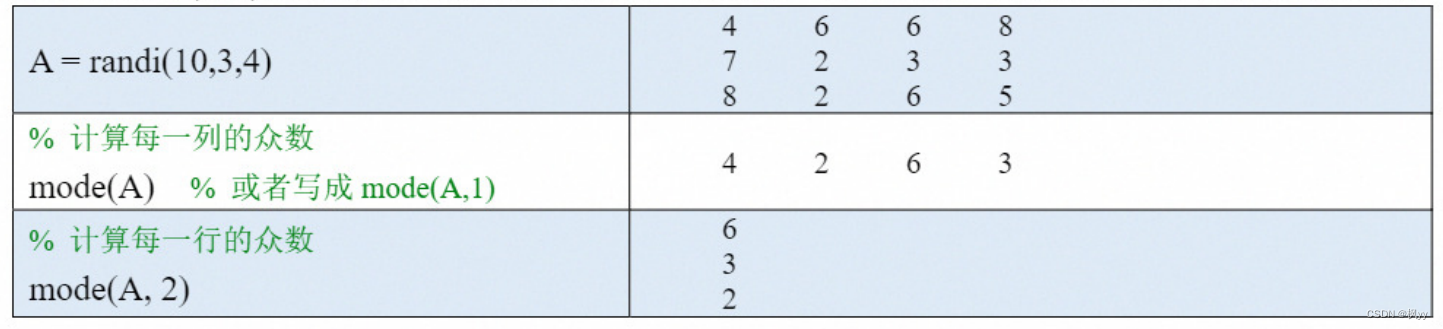
以计算向量A 的众数为例,直接调用mode(A)会返回A 中出现次数最多的值。如果有多个值以相同的次数出现,mode 函数将返回其中最小的值。

如果A 是一个矩阵,则mode(A,1)或者mode(A)可以沿着行方向进行计算,得到每一列的众数;mode(A,2)可以沿着列方向进行计算,得到每一行的众数,这里的1和2表示维度dim。
注意:使用mode 函数计算众数时会自动忽略NaN 值,我们不能额外添加'omitnan'参数, 否则会报错。

现在我们来看 mode 函数有两个返回值的例子,如果A 是一个向量,M,F=mode(A) 得到的M表示向量A的众数,F表示众数M在向量A中出现的次数。

上面这个例子中,有两个众数,分别是0和8,它们出现的次数都是3次,此时MATLAB 会返回最小的那个数作为众数。MATLAB 能不能把这些众数都输出呢?
当然可以,我们需要用到mode 函数的第三个返回值:M,F,C=mode(A), 这里的C 是一个元胞数组,元胞数组里面有一个列向量,列向量中的每个元素都是向量 A 的众数 。(注意,元胞数组(cell array)是使用大括号{ }括起来的,元胞数组里面的元素可以包含不同的数据类型,例如标量、向量、矩阵、字符串等)
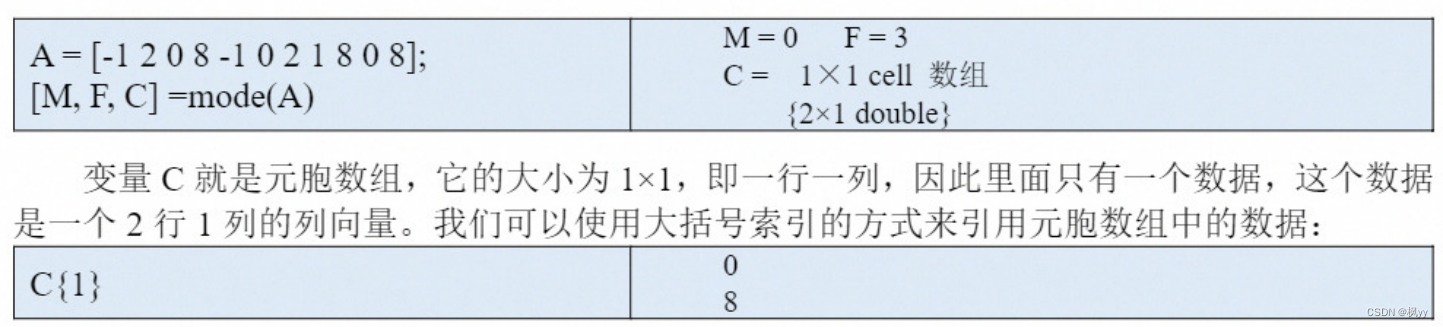
命令C{1}可以提取出元胞数组C 中的第一个数据:列向量0;8。这个列向量中的元素0 和8都是向量A 的众数。
以上是A 为向量时的情况,如果A 是一个矩阵,mode 函数也可以有两个返回值或三个返 回值,后两个返回值代表的含义与A 为向量时类似。我们直接看下面的例子:

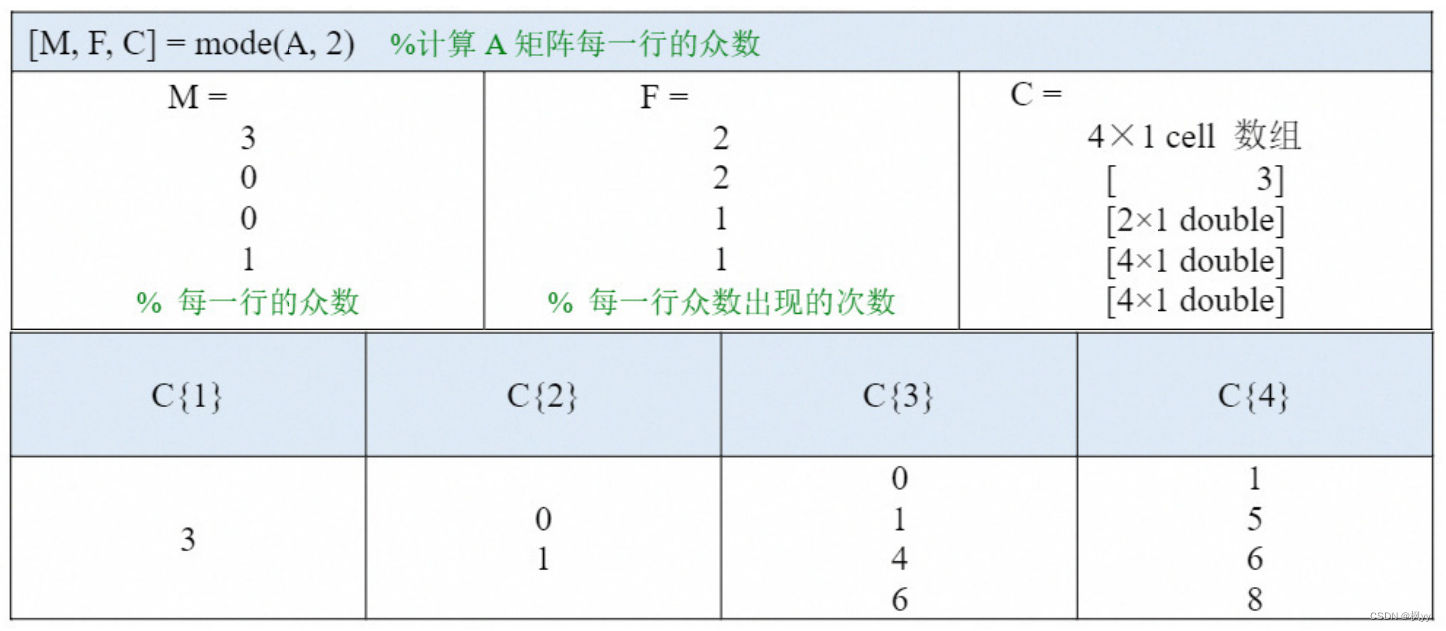
M 是一个包含四个元素的行向量,里面第k 个元素表示第k 列的众数,例如第1列的众数为0;如果有多个众数,那么会返回最小的那个值,因此第2列返回的众数为0。
F 也是一个包含四个元素的行向量,它表示M 中的各个众数在其所在列中出现的次数, 例如第1列的众数0在第1列出现了2次。
C 是一个大小为1×4的元胞数组,里面的第k 个数据表示第k 列的所有众数。从元胞数组 C 的结果来看,第一个和第四个数据分别为0和4,这说明第1列和第4列都只有一个众数,分别是0和4;C 中第二个数据是一个4行1列的列向量,这说明第2列有四个众数;C 中第 三个个数据是一个2行1列的列向量,这说明第3列有两个众数。
我们可以使用大括号索引提取C 中的每个数据:

类似的,我们也可以计算A矩阵每一行的所有众数,结果如下:
var : 计算方差 (variance)
方差是概率论与数理统计里面的知识点,我们先简单回顾一下相关的内容。
先来看个例子:第一组数据是6、8、10、12、14;第二组数据是-10、0、10、20、30。显 然两组数据的均值都是10,但第二组数据的离散程度更大一些。
方差就是用来描述这种离散程度的一个统计量,当两组数据的平均值相同时,方差较大的一组数据的离散程度更大。有一个常举的例子: 一个射击队要从两名运动员中选拔一名参加比赛,选拔赛上两人各打了10发子弹,在得分均值相差不大的情况下,应选择方差更小的队员。
在现实生活中,我们收集到的数据可分为下面两类:
◇总体数据:所要考察对象的全部个体叫做总体;
◇样本数据:从总体中所抽取的一部分个体叫做总体的一个样本。 根据收集的数据类型的不同,我们计算方差的公式也有所区别。

从上方的计算公式可以看出,总体方差和样本方差在计算时的区别在于分母上是否要减1。
MATLAB中使用var 函数计算方差:
(1)如果A 是一个向量,那么 var(A,w)可以计算A 的方差,当w=0 时,表示计算样本 方 差 ,w=1 时表示计算总体方差,另外,var(A,0) 也可以直接简写为var(A)。
(2)如果A 是一个矩阵,则var(A,w,dim) 可以计算矩阵A沿维度dim 上的方差。
● dim=1时表示沿着行方向进行计算,即得到每一列的方差;
● dim=2时表示沿着列方向进行计算,即得到每一行的方差。
当 dim 为 1 时 ,var(A,w,1) 可以简写为var(A,w);若 w 为0,则可以进一步简写为
var(A),即默认情况下MATLAB会沿行方向计算得到每一列的样本方差。
(3)如果数据中存在NaN 值,可以在var函数的最后加上'omitnan'参数来忽略NaN.

std : 计 算 标 准 差 (standard deviation)
**标准差是方差的算术平方根,它也是用来反应数据离散程度的一个统计量。**那么问题来了, 既然有了方差为什么还需要标准差呢?这是因为方差和数据原本的量纲(即单位)是不一致的, 对方差的计算公式进行量纲分析容易看出,方差的量纲是原始数据量纲的平方,因此对方差开 根号,得到的标准差的量纲和原始数据的量纲一致。
在MATLAB 中,我们可以使用std函数计算样本标准差和总体标准差,它和var函数的使 用方法完全相同。

min : 求 最 小 值 (minimum value)
min函数主要有两种用法:
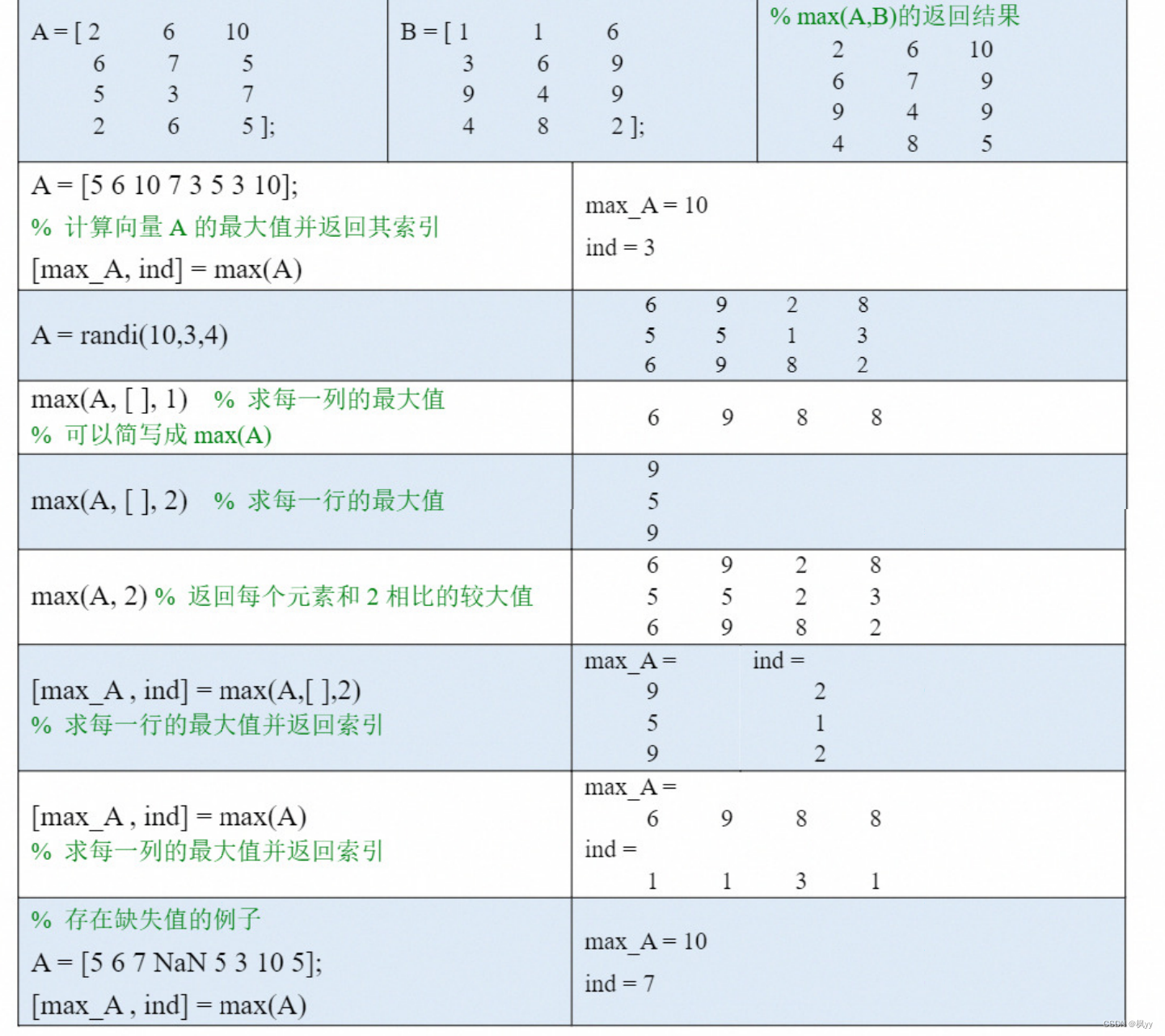
用法一:求两个矩阵对应位置元素的最小值:min(A, B)。

矩阵A和矩阵B的大小可以不一样,只要保证矩阵A和矩阵B具有兼容的大小就能够计算 ,下面再举两个例子:表中第三列是运行min(A,B)后返回的结果。

用法二:求向量或者矩阵中的最小值,可以指定沿什么维度计算并返回索引。
具体用法有以下三种:
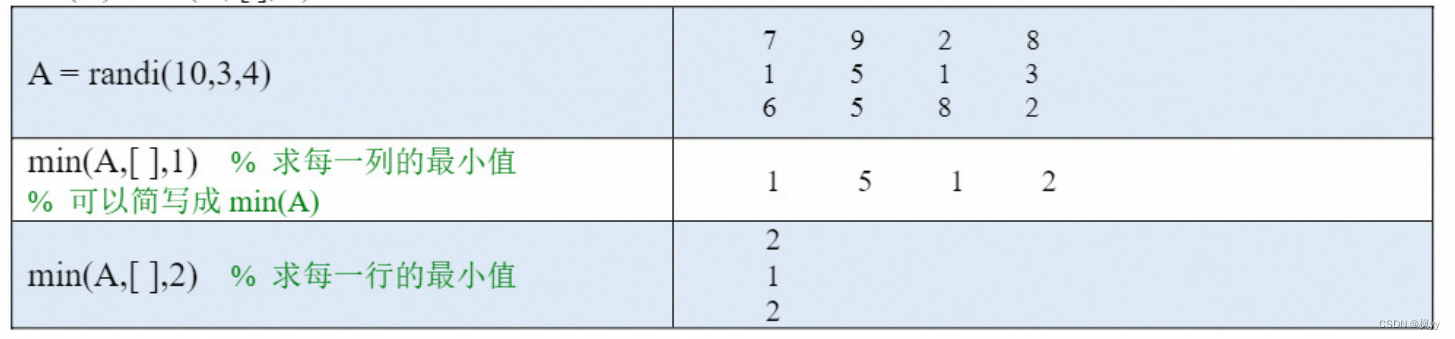
(1)如果A是向量,则min(A)返回A 中的最小值。如果A 中有复数,则比较的是复数的模长。

(2)如果A 是矩阵,则min(A, ,1) 沿着A 的行方向求每一列的最小值,也可以简写为 min(A);min(A, ,2)沿着A的列方向求每一行的最小值。这里的1和2表示矩阵的维度(dim)
为什么中间要加一个空向量 ?如果不加的话,就是将A 中每个元素和 1或者2 比较大小,并返回较小值。

(3)在求向量或矩阵的最小值时,min 函数可以有两个返回值: m,ind=min(A). 第一个返回值m 是我们要求的最小值,ind 是最小值在所在维度上的索引。如果最小元素出现多次, 则ind是最小值第一次出现位置的索引。
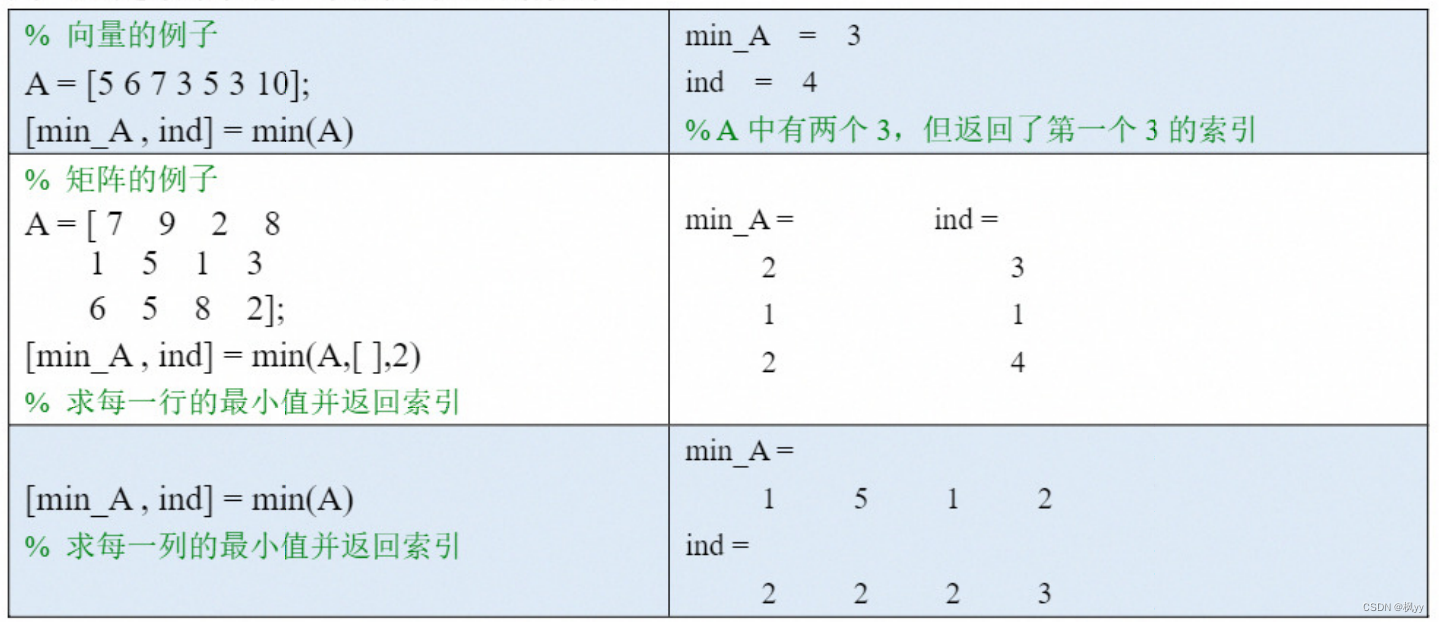
上面我们介绍了min 函数的两种用法,如果向量或者矩阵中存在NaN 值 ,min 函数会自 动忽略,大家不需要单独对NaN值进行处理。

max : 求 最 大 值 (maximum value)
max函数和min函数的用法完全相同,它是用来求最大值的函数,下面我们举几个例子: