文章目录
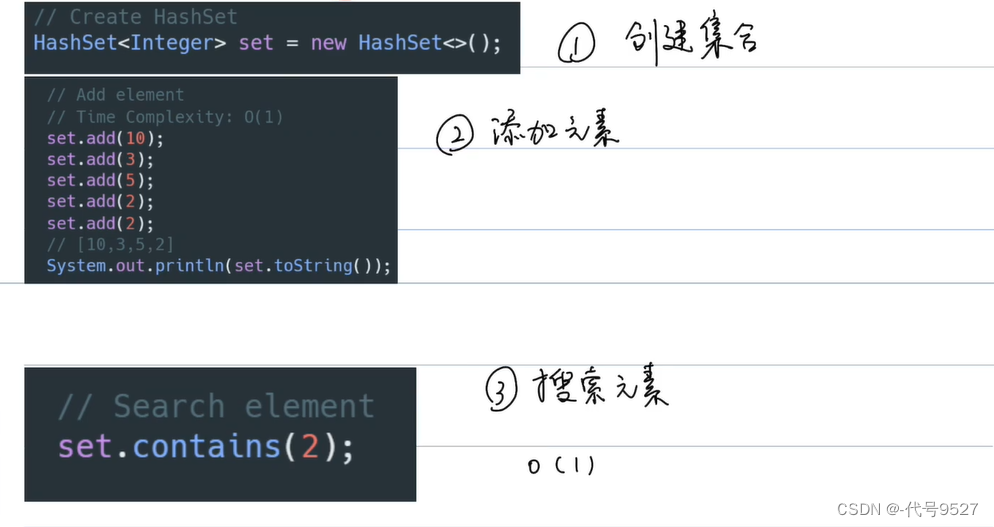
1、Set集合
- 无序:写进去的顺序和遍历读出来的顺序不一样
- 不重复

主要作用:查看是否有重复元素(给一个数组,转为set,数组的长度 > set的长度,即有重复元素)

时间复杂度:

2、Java中的Set集合

3、leetcode217:存在重复元素

思路:重复的判断,借助数据结构的set,数组的长度 > set集合的长度,即有重复。相比之前对这个题的解法,很明显的感觉到,用上数据结构,比无脑for循环要快很多。
java
public class P217Two {
public static boolean isExistSameElement(int[] array) {
if (array == null || array.length == 0) {
return false;
}
HashSet<Integer> set = new HashSet<>();
for (int i : array) {
set.add(i);
}
return array.length > set.size();
}
}测试:
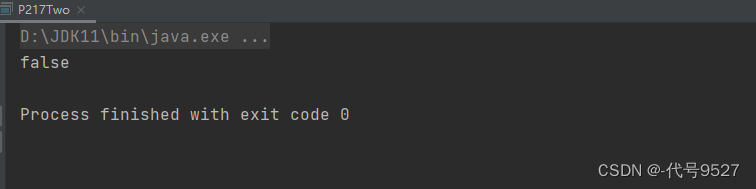
java
public class P217Two {
public static void main(String[] args) {
int[] array = {1, 2, 3, 4, 5};
System.out.println(isExistSameElement(array));
}
}
4、P705:设计哈希集合

实现自己的HashSet类,那也就要达到搜索、插入、删除的时间复杂度为O(1),考虑用一个boolean类型的数组,每个元素默认值自然是boolean的默认值false,此时,放进来一个1,就把下标索引为1的地方改为true,删除一个10,就把下标索引为10的地方改为false,重复放进来同一个值,仍然为true,符合Set集合的不重复
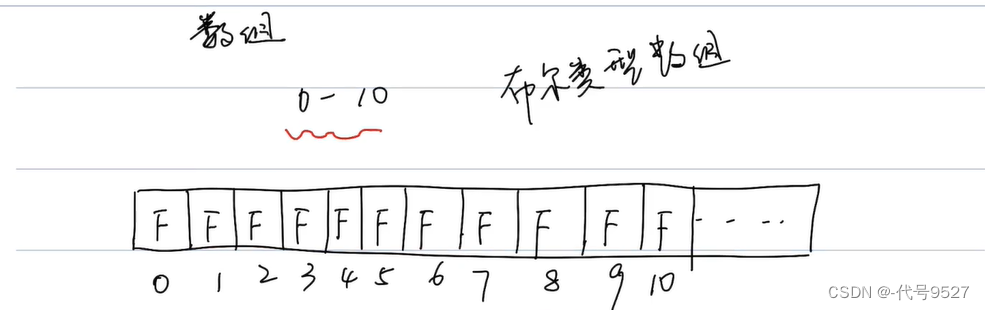
这种解法的缺点:
- 数组初始化长度怎么确定(int\[\] array; 只定义不初始化数组,没法往里面放元素)
- 比如题目规定了数据范围在0 - 1000w,一下创建这么长一个数组,对连续的内存空间要求太高
java
class MyHashSet {
boolean[] array;
public MyHashSet() {
array = new boolean[10000];
}
public MyHashSet(int size) {
array = new boolean[size];
}
// 新增元素
public void add(int key) {
array[key] = true;
}
// 移除元素
public void remove(int key) {
array[key] = false;
}
// 是否包含某个元素
public boolean contains(int key) {
return array[key];
}
}测试:
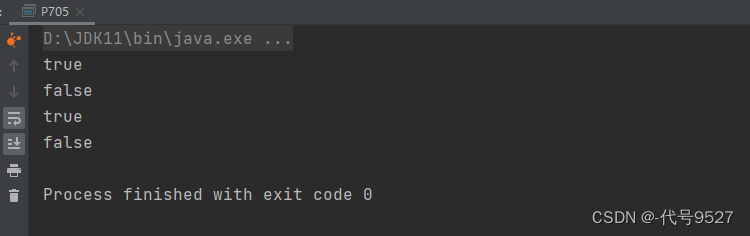
java
public class P705 {
public static void main(String[] args) {
MyHashSet myHashSet = new MyHashSet();
myHashSet.add(1);
myHashSet.add(2);
System.out.println(myHashSet.contains(1)); // 返回True
System.out.println(myHashSet.contains(3)); // 返回 False ,(未找到)
myHashSet.add(2);
System.out.println(myHashSet.contains(2)); // 返回 True
myHashSet.remove(2);
System.out.println(myHashSet.contains(2)); // 返回 False ,(已移除)
}
}