摘 要
在当前互联网飞速发展的时代,计算机应用给我们的工作生活带来了极大的便利。如今我们的生活离不开电商平台,其随之而来的是各种各样的销售数据与消费者信息,这些数据和信息的分析应用成为了当前互联网领域研究的重要部分。
本论文以基于Python的电商平台生活用品销售数据分析与应用为研究主题。采用了流行的Python Web框架Django,使得系统易于扩展和维护。在数据获取方面,采用爬虫技术获取淘宝的销售数据,并将这些数据储存在MySQL数据库中,用于后续的数据处理分析,以便为商家提供决策依据。在数据展示上,选用HTML、CSS、JS等构建前端页面,同时利用了Bootstrap框架及Echarts图进行数据的可视化展示,提供了极佳的用户体验。
本文详细研究了销售数据分析与预测的过程。通过Python编写了爬虫程序,对淘宝上的生活用品销售数据进行了抓取。再运用了随机森林回归算法来预测销售额,从而为商家提供了科学的决策依据。总而言之,整合运用了多种技术和方法,来达到帮助商家提升销售预测、决策水平的目的。
关键词:Bootstrap;Mysql;Django;Echarts
3.2功能需求
3.2.1 数据收集
数据源来自淘宝网站。淘宝网站上有丰富的关于生活用品销售信息的数据,因此选择爬取淘宝网的数据。
数据采集方式:Python的Selenium库被用来进行自动化Web浏览器操作采集数据,并实时获取数据。
数据获取频率:由于数据来源于淘宝平台,其更新频率较高,因此设定的采集频率为每30秒爬取一页数据,以适应数据的实时变动。根据实际商品数量和销售频率的变动,收集的销售数据原始大小会有所不同,经过数据清洗选后,将适量的数据保存到了MySQL数据库中,这些数据会被用于后续的模型测试和数据分析。
数据格式和结构:销售数据主要以数字类型为主,商品相关的字段则使用文本方式存储,这不仅有助于减少存储空间,也便于进行数据处理与可视化分析。
通过对数据收集的功能需求进行分析和定义,可以确保数据采集过程的顺利进行,并为后续的数据处理和分析提供高质量的数据基础。
3.2.2 数据整理与选择
数据清洗和预处理:数据清洗的代码主要工作是对淘宝销售数据进行清洗和预处理,其中一个重要步骤是把相对日期(如'3天前'、'2月前')转化为真实日期。在连接MySQL数据库后,对"xitong_comments"表中的"id"和"createtime"字段进行处理,若日期存在,就进行日期转换。同时,为确保数据质量,还进行了重复值处理和缺失值处理,这为后续模型训练提供了重要基础。
特征工程:其中使用XGBoost方法计算特征与模型之间的关系,并根据数据特性选择合适的特征嵌入到适当的模型进行训练,有效地提升了模型的准确性、精度、可靠性和稳定性。
3.2.3 数据展示
数据展示的主要任务是从数据库提取数据,进一步分析并进行可视化展示。
连接并查询MySQL数据库后,代码抓取了数据表中的相应数据,并进行了分词。然后,使用jieba库抽取了关键词。
展示了数据可视化的重要几步:首先是数据收集和预处理;接着是数据的汇总和聚合;最后是数据的可视化和评估,包括生成柱状图、折线图。
具体到可视化,利用了pyecharts库来创建词云、柱状图和折线图等多种图表类型。也应用了数据筛选和过滤,以便选择合适的关键词作为词云的内容,计算得到不同种类商品的销售量作为柱状图和折线图的数据。同时,数据的汇总与聚合也是必不可少的一步。此外,这个过程还展示了如何使用可视化工具来展示多维数据,比如柱状图展示了商品名称与其对应的销量的关系。最后,使用了结果的评估和可视化,这里提供了直观的可视化图表来评估各种生活用品对应的销量的变化。
3.2.4 数据预测
数据预测主要完成了数据采集、清洗、转换、特征提取、训练模型以及结果可视化几个步骤。
首先,读取原始数据,并对数据进行初步的清洗处理,包括缺失值分析、删除含有过多缺失值的列、删除重复行等,然后将处理后的数据导入数据库中。
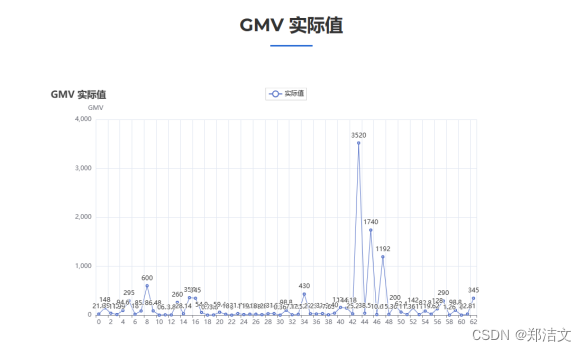
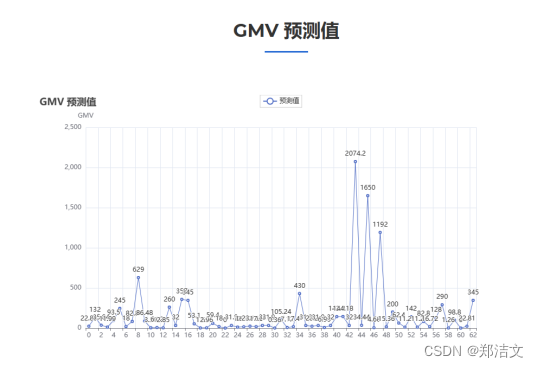
其次,对销售额进行清洗和转换,将销售量从字符串格式转为整数。并通过相应的计算得到GMV(商品交易总额),作为后续分析的重要特征。
然后,分词并剔除停用词,得到干净的标题数据,进一步进行关键词提取和统计。并且,对标题中各个关键词对应的销售总量进行统计分析,并进行可视化展示。
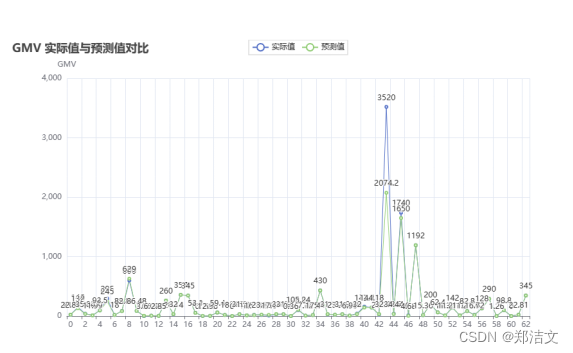
同时还通过随机森林模型对GMV进行预测分析。在这个过程中,首先对商品价格和销量数据进行标准化处理,然后将数据集分为训练集和测试集,使用网格搜索法寻找最优参数并训练随机森林模型。最终,对模型的预测结果进行可视化展示,并输出模型的均方误差,评估模型的性能。
这个过程展示了数据集成、预处理、特征抽取与建模等关键步骤,以及数据可视化的重要性。这些步骤和技术的结合,有助于提供对预测结果的理解和评估,使得结果更具解释性和应用价值。
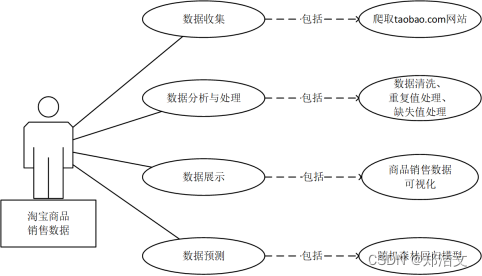
3.2.5用例图
用例图可以了解商品销售数据处理的步骤和方法,如图3-1所示。
4.5数据分析与可视化
4.5.1商品销售数据分析与可视化
首先,通过连接MySQL数据库,提取xitong_productdata表中所有记录的shop和sales字段,然后使用正则表达式从sales字段中提取数字,并依据shop字段(也就是商品名称)累计各个商品的总销售量。
然后,使用Pyecharts库创建并渲染柱状图,其中横轴为商品名称,纵轴为销售量,以直观地展示各商品的销售情况。
以下是商品销售数据可视化部分代码:
top20_sales = data.sort_values('sales', ascending=False).head(20)
echarts_bar_top20 = (
Bar()
.add_xaxis(top20_sales.productname.tolist())
.add_yaxis("销量", top20_sales.sales.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="销量前20的商品"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-45)),
yaxis_opts=opts.AxisOpts(name="销量"))
.render("E:\\python\\电商平台生活用品销售数据分析与应用\\xitong\\templates\\xitong\\keyword_sales_analysis.html")
)
echarts_bar = (
Bar()
.add_xaxis(df_w_s.word.tolist())
.add_yaxis("销量之和", df_w_s.w_s_sum.tolist())
.set_global_opts(title_opts=opts.TitleOpts(title="关键词销量之和分析"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-45)),
datazoom_opts=opts.DataZoomOpts())
.render("xitong/templates/xitong/keyword_sales_analysis.html")
)根据代码得到商品销售数据柱状图,如图4-6所示:
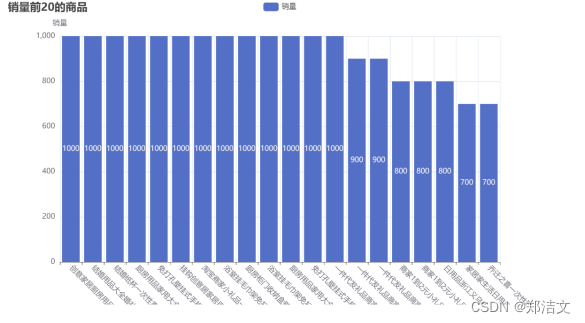
(图4-6数值解释:由于淘宝平台未对商品销量的具体数值进行公开,故不能爬取到商品销量的具体数值,因此在可视化展示时,结果显示的1000代表销量为1000+,即商品的真实销量大于1000,其他数值同理。)
图4-6呈现的是商品销售数据柱状图,其中横轴代表各种生活用品的名称,纵轴代表与其对应的销量。结合图4-6分析可以得出:在淘宝这个电商平台中,销量较高的生活用品为:厨房用品、浴室毛巾、一次性纸杯、收纳盒及一些低价的小礼品等。因此商家可以考虑对这几类销量较高的商品更多的进货,以此获得更多的利润。

由于时间有限,没有细描述。如需要参考,可以联系!下方有联系方式!