Whisper是一个开源的自动语音识别(ASR)模型,最初由OpenAI发布。要在本地Linux系统上部署Whisper,你可以按照以下步骤进行:
1. 创建虚拟环境
为了避免依赖冲突,建议在虚拟环境中进行部署。创建并激活一个新的虚拟环境:
如果不知道 conda如何安装
找作者这篇文章 最后面有安装conda教程
https://blog.csdn.net/yhl18931306541/article/details/129141060?spm=1001.2014.3001.5501
打开上方网址,划到最后位置,按照作者的一步一步来即可
bash
conda create --name whisper python=3.11.7
conda activate whisper进入到虚拟环境执行下方命令

2. 安装Whisper及其依赖项
使用pip安装Whisper及其依赖项:
bash
pip install git+https://github.com/openai/whisper.git
pip install torch
pip install faster-whisper3. 测试安装
你可以运行以下命令来测试Whisper是否安装成功:
bash
python -m whisper如果看到帮助信息,说明安装成功。
4. 使用Whisper
Whisper可以通过命令行或Python脚本来使用。以下是一个基本的使用示例:
命令行使用:
whisper audio_file.mp3 --model large-v2
将 audio_file.mp3 换成 你准备识别的语音,回车等待即可python脚本使用:
python
# 导入模块
from faster_whisper import WhisperModel
# 模型路径,
# # model_path = WhisperModel("large-v3")
# 注释:下载路径需要使用代理出外网下载,将下载好的模型上传到linux服务中
model_path = "/root/.cache/huggingface/hub/models--Systran--faster-whisper-large-v3/snapshots/edaa852ec7e145841d8ffdb056a99866b5f0a478"
# 初始化 WhisperModel
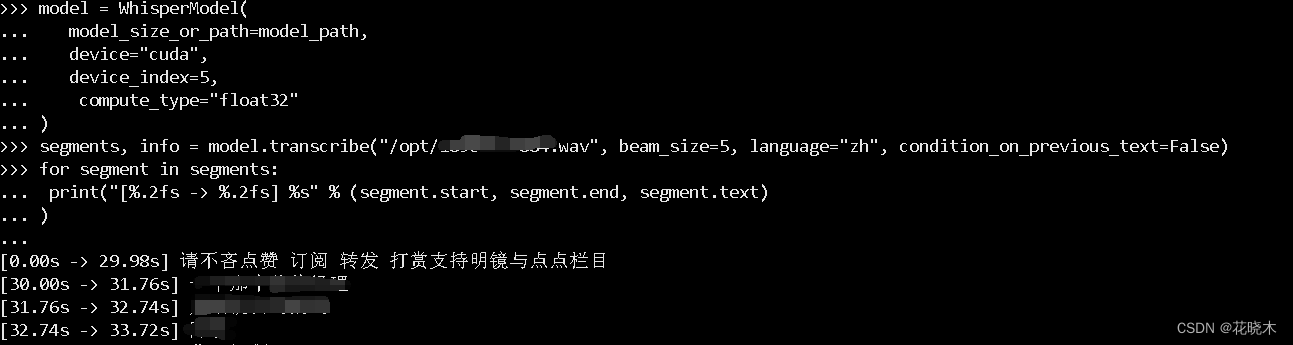
model = WhisperModel(
model_size_or_path=model_path, # 必须提供模型路径或模型大小
device="cuda", # 使用 GPU
device_index=1, # 指定第二个 GPU(从 0 开始计数)
compute_type="float32" # 使用 float32 精度计算
)
# 进行语音识别
segments, info = model.transcribe("/opt/189****2345.wav", beam_size=5, language="zh", condition_on_previous_text=False)
# 注释 189****2345.wav 换成你准备识别的语音 .mp3文件可以
# 打印识别结果
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text)
)输入如下即可
如果报错:
Could not load library libcudnn_ops_infer.so.8. Error: libcudnn_ops_infer.so.8: cannot open shared object file: No such file or directory
已放弃 (核心已转储)处理:
find / -name 'libcudnn_ops_infer.so.8'
虚拟用户目录下
whisper/lib/python3.11/site-packages/nvidia/cudnn/lib/libcudnn_ops_infer.so.8
cp -rp /data/anaconda3/envs/whisper/lib/python3.11/site-packages/nvidia/cudnn/lib/*.8 /usr/lib/
cp -rp /data/anaconda3/envs/whisper/lib/python3.11/site-packages/nvidia/cudnn/lib/*.8 /usr/lib64/
继续运行即可