试卷组成

第一章图
 第二章图
第二章图
第三章图

第四章图
第五章图
第六章图
第九章图
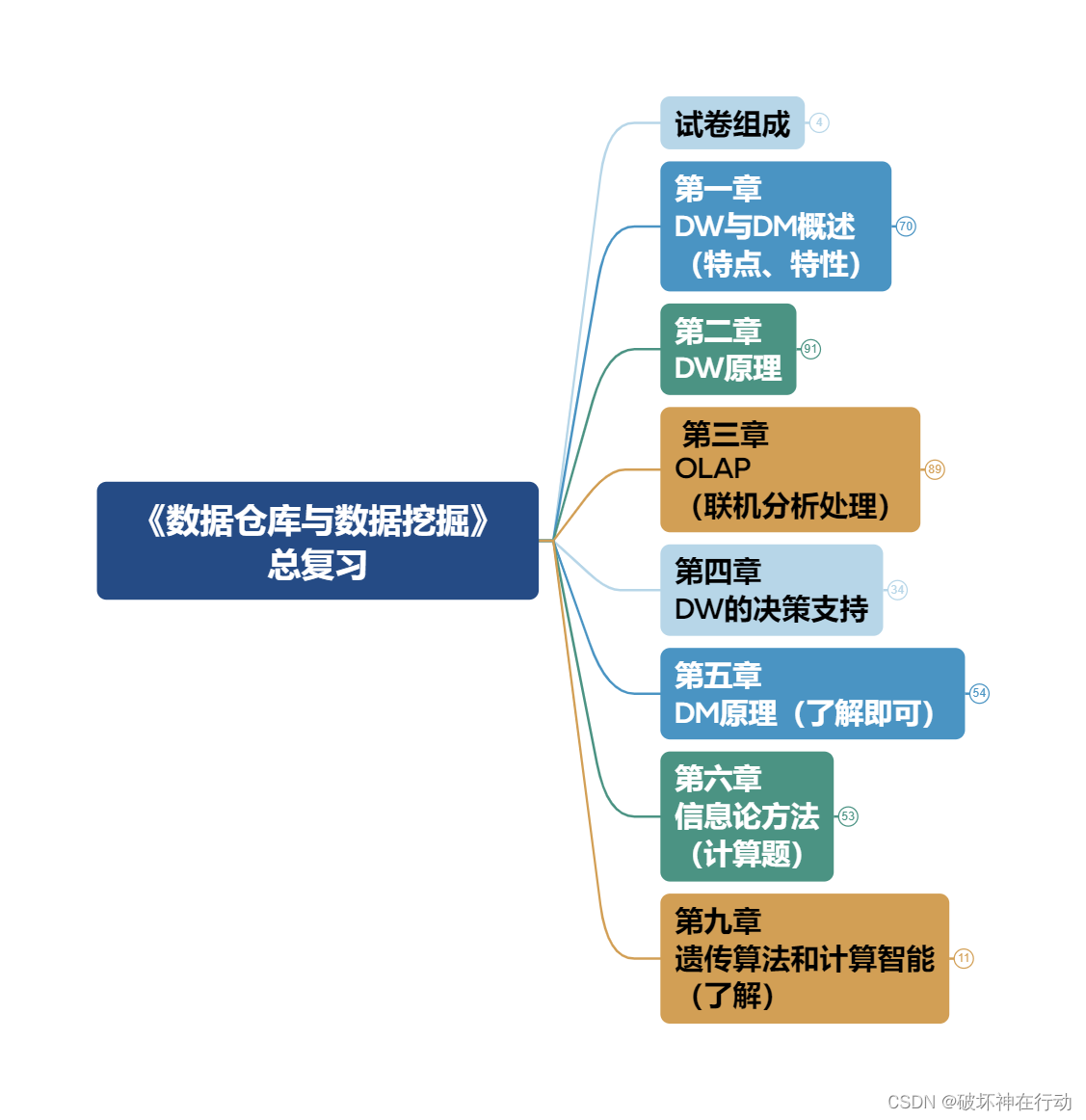
第一章 DW与DM概述 (特点、特性)
DB到DW
主要特征
(1)数据太多,信息贫乏(Data Rich, Information Poor)。
(2)异构环境数据的转换和共享。(不同数据库数据结构不一样,如何整合?)
(3)利用数据进行事务处理转变为利用数据支持决策。
总结:D多,异构,事决
好多D,DB和DW发生争执给他们异构体,事情解决
演变4点
(1)DB用于事务处理,DW用于决策分析。
(2)DB保持事务处理的当前状态。 DW既保存过去的数据又保存当前的DB中的数据。
随业务的变化一直更新,保存当前数据。
不随时间变化而变化,保留历史数据和当前数据。
(3)DW的数据是大量DB的集成。
(4)对DB的操作比较明确,操作数据量少。 对DW操作不明确(通过某种算法),操作数据量大。
总结:事决,状态,集成,操作
想要事情解决,D保持良好状态,集成精力施以操作
OLTP到 OLAP
联机事务处理 (On Line Transaction Processing,OLTP)
概念:用户的数据可以立即传送到计算中心进行处理,短时间内给出处理结果。
实时系统(Real Time System)
联机分析处理 (On Line Analytica Processing,OLAP)
概念:多维数据库和多维分析
元数据 (Meta Data)
什么是元数据?
描述数据的数据(Data About Data)
为什么研究?
数据越多,越需要能对数据进行描述说明的数据。
重要性:数据仓库中数据的描述(数据字典)
元数据的分类?
- 关于数据源的元数据
对不同平台上的数据源的物理结构和含义的描述。(提示我们如何将数据转换到DW中)- 关于数据模型的元数据
描述了DW中有什么数据以及数据之间的关系。- 关于DW映射的元数据
是数据源与DW数据间的映射。 (获取数据的第一步)- 元数据反映DW中的数据项从哪个数据源抽取的,经过哪些ETL
关于DW使用的元数据。- DW中信息使用情况的描述。
总结:D源模W映用,物含关系,映射使用
元数据的分类查看原魔应用
DW特点(6)
- 面向主题
每一个主题基本对应一个宏观的分析领域。(对什么决策?)- 集成的
对不同的数据来源进行统一数据结构和编码。- 稳定的
大量的历史数据(只进不出)- 随时间变化(长时间)
- 数据量很大
- 软、硬件要求较高
巨大的硬件平台
并行的数据库系统特点总结:题集稳时数要求
DW提及问题时要数要求
本书核心
数据仓库是为辅助决策而建立的
DM
- 知识发现 (Knowledge Dicovery in Database,KDD):从数据中发现有用知识的整个过程。主要算法是归纳学习算法。
- KDD过程中的一个特定步骤,它用专门算法从数据中抽取知识。
DM与OLAP比较
- OLAP多维分析:切片、切块、钻取操作。辅助决策。
- DM:任务在于聚类(如神经网络聚类)、分类(如决策树分类)、预测等。
确定一个高价值的客户或可能离开的客户特征。
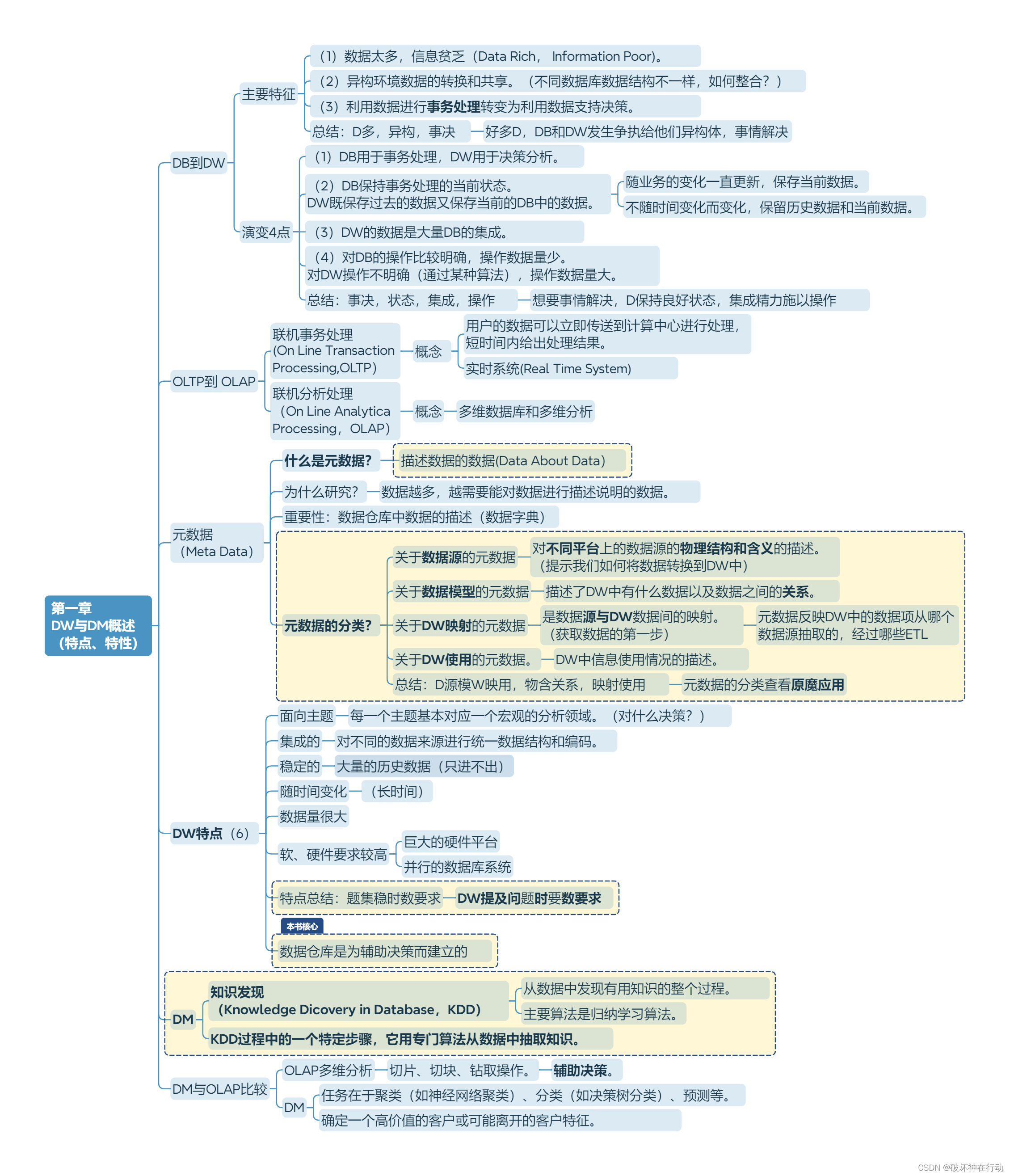
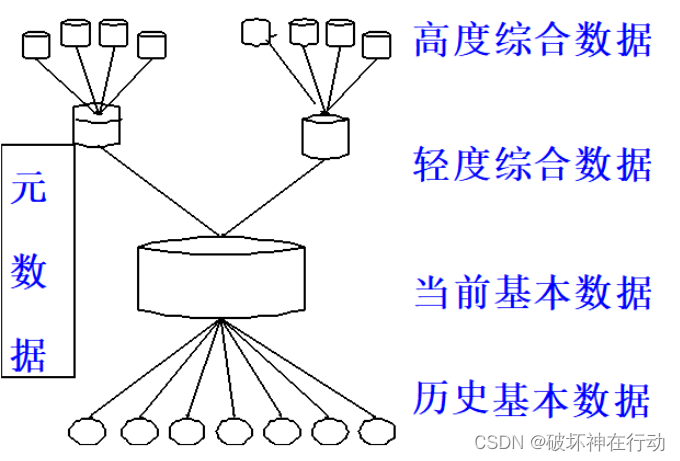
第二章 DW原理
DW结构包含哪几类数据?
(5:历当轻高元)
数据集市 (Data Marts)
概念:更小、更集中、具特定应用的DW。
特性:规模小、特定应用、面向部门、快速实现、投资快速回收、可升级到完整DW。
分类?
独立数据集市 (Dependent Data Mart)
数据来源:直接来源于各生产系统
从属数据集市 (Independent Data Mart)
数据来源:直接来自中央DW
数据集市与DW差别?
- 主题
DW:面向企业范围。
数据集市:面向某一特定部门。- 数据详细程度
DW:非常详细
数据集市:低,概要多- 数据组织
DW:第三范式等。
数据集市:星型模型。总结:题详细组织,企部,高低,三星
主题公园的D详细组织,起步高低的三星
DW系统结构
由数据仓库(DW)、仓库管理和分析工具三部分组成。
1、仓库管理包括什么? (4部分)
(1)数据建模:是建立DW的数据模型(Data Model)
DW数据模型按设计过程分类?
概念数据模型
- 最高层次的数据模型, 它定义了组织的数据仓库的业务概念和需求。
逻辑数据模型
- 概念数据模型的具体化, 它描述了数据元素之间的关系,但不涉及存储细节。
物理数据模型
- 逻辑数据模型的实现, 它详细描述了数据在数据库中的存储方式。
总结:概逻物,需求关系存储
盖螺屋,rrs
(2)数据抽取、转换、装载 (ETL: Extract、Transform、Load) 70%工作量
抽取(Extract)
- 第一步,从各种数据源中收集数据。 批量实时提取数据。
转换(Transform)
核心步骤,将原始数据转换成适合DW格式的数据。
转换过程
数据清洗 (去除错误和不一致的数据)
数据集成 (合并来自不同源的数据)
数据聚合 (汇总数据以减少数据量)
数据映射 (将数据映射到数据仓库模型)
......
转换过程确保数据的一致性、准确性,并满足数据仓库的业务需求。
装载(Load)
- 最后一步,涉及将转换后的数据加载到DW中。
总结:ETL,收集数据,转格式,加载DW
(3)元数据
- 3功能:DW字典,指导ETL工作,指导用户使用DW。
(4)系统管理
- 4部分:数据管理、性能监控、存储器管理、安全管理。
总结:数性存安
dpss
2、分析工具
(1)查询工具:可视化工具
(2)多维分析工具(OLAP工具)
(3)数据挖掘(DM)工具
(4)C/S工具
DW运行结构
- 典型的客户/服务器(C/S)
- DW应用的三层C/S结构
C/S(OLAP,DW) 有个公用OLAP层,工作效率更高

DW的数据模型
多维数据模型
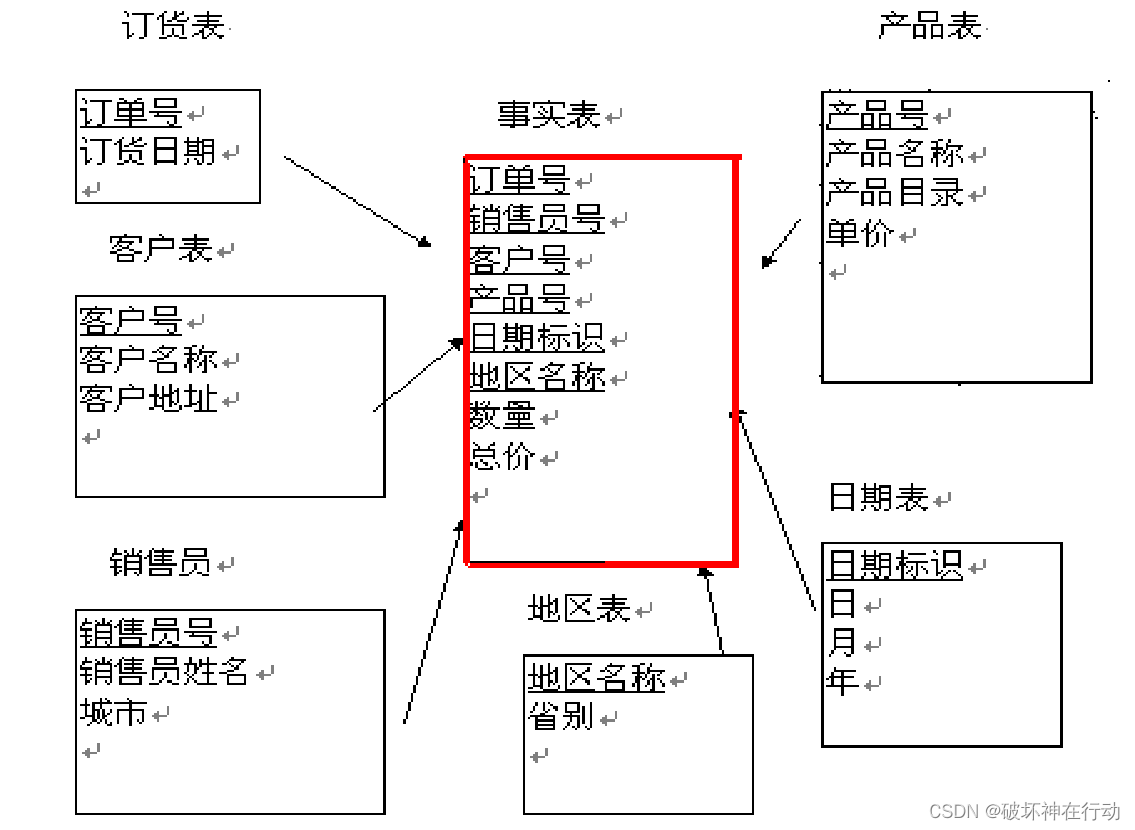
星型模型
由"事实表"(大表)以及多个"维表"(小表)所组成。
雪花模型
- 对星型模型的维表进一步层次化,原来的各维表可能被扩展为小的事实表,形成一些局部的"层次"区域。
星网模型
- 将多个星型模型连接起来形成网状结构。
第三范式
传统DB设计理论
- 减少数据冗余
优势
星型模型
多维数据分析时速度很快
- 但是增加维度将是很困难的事情。
第三范式
- 海量数据(如TB级),大量的动态业务分析
第三章 OLAP (联机分析处理)
概念
定义
OLAP是共享多维信息的快速分析。
4个特征
1、快速性
2、可分析性
3、多维性
4、信息性
总结:快可多信
快速的多维分析信息值得信赖
特点
1.线性(On Line),由网络上的C/S结构完成。
2.多维分析,OLAP的核心所在。
准则 (主要4条)
(1)多维数据分析;
(2)客户/服务器结构;
(3)多用户支持;
(4)一致的报表性能等。
- 数据维数和数据的综合层次增加时, 提供的报表能力和响应速度不应该有明显的降低。 (即便D量,维度增加,速度不应该下降)
OLAP的数据模型
分类
MOLAP数据模型
Multidimensional Online Analytical Processing
基于多维数据库存储方式建立的OLAP
表现为"超立方"结构,采用类似于多维数组的结构。
ROLAP数据模型
Relational Online Analytical Processing
是基于关系数据库的OLAP。
是一个平面结构,用关系数据库表示多维数据时,采用星型模型。
比较
1.数据存取速度(MOLAP的响应速度快 )
M
R需要转化SQL语句
2.数据存储的容量( ROLAP存储容量上没有限制)
R
M立体方式存放数据,数据量级不大
3.多维计算的能力(MOLAP能够支持高性能计算 )
M
R无法多行/维计算
4.维度变化的适应性(ROLAP对于维表的变更有很好的适应性 )
R
M增维需重建DB
5.数据变化的适应性( ROLAP对于数据变化的适应性高 )
R
M在数据频繁变化时需要大量重新计算
6.软硬件平台的适应性(ROLAP适应性很好 )
- R
7.元数据管理
- 均无成形标准。
总结:as计维变适管,多关多关关关无
- 存计为多,其余为关
多维数组的表示
(维1,维2,......,维n,变量)
一个4维的结构,即(产品,地区,时间,销售渠道,销售额)。(元组)
多维数据的显示
多维数据的显示只能在平面上展现出来。
多维数据的分析视图
平面显示多维数据,利用行、列和页面三个显示组表示。(页面,行,列,指标维)
- 页面:商店3(商店维) 行:月份(时间维:1月,2月,3月) 列:产品(产品维:上衣,裤子,帽子) 指标维:固定成本,直接销售
多维数据分析的基本操作分别是怎么执行的?
(切片、切块、旋转、钻取)
1.切片
- 选定多维数组的一个二维子集的操作。
- 切块
多维数组的某个维上选定某一区间的维成员的操作。
选定多维数组的一个三维子集的操作。
- 钻取
维度的细分。
向上钻取(drill up )
向上钻取获取概括性的数据。
缩小地图:区-市-省-国
向下钻取(drill down )
向下钻取是使用户在多层数据中能通过导航信息而获得更多的细节性数据。
放大地图:国-省-市-区
4.旋转
- 得到不同视角的数据。 相当于平面数据将坐标轴旋转。
总结:片块上下转,二三概细多视角。
数据立方体
概述:实际为数据仓库结构图中的综合数据层(轻度和高度)。
多维数据集的属性分类?
维属性
度量属性
典型的压缩型数据立方体
(1)冰山立方体
- 数据的筛选:在冰山立方体的生成计算中,仅聚集高于(或低于)某个阈值的子立方体。
(2)紧凑数据立方体
- 用一条数据来代表之前表中的多条数据元组压缩如(产品,地区,时间,销售渠道,销售额)
(3)外壳片段立方体
(4)流式数据立方体
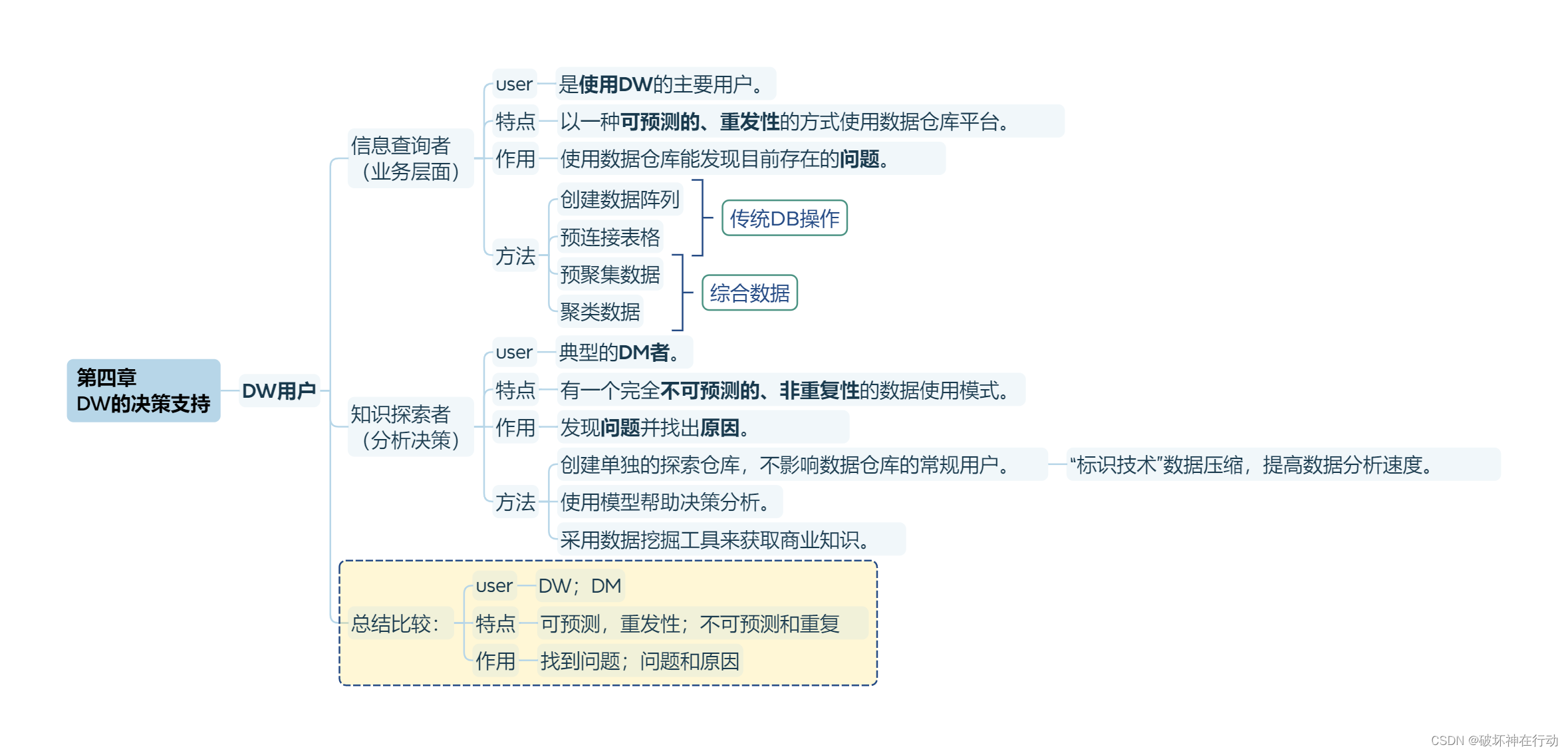
第四章 DW的决策支持
DW用户
信息查询者 (业务层面)
user
- 是使用DW的主要用户。
特点
- 以一种可预测的、重发性的方式使用数据仓库平台。
作用
- 使用数据仓库能发现目前存在的问题。
方法
创建数据阵列
预连接表格
预聚集数据
聚类数据
知识探索者 (分析决策)
user
- 典型的DM者。
特点
- 有一个完全不可预测的、非重复性的数据使用模式。
作用
- 发现问题并找出原因。
方法
创建单独的探索仓库,不影响数据仓库的常规用户。
- "标识技术"数据压缩,提高数据分析速度。
使用模型帮助决策分析。
采用数据挖掘工具来获取商业知识。
总结比较:
user
- DW;DM
特点
- 可预测,重发性;不可预测和重复
作用
- 找到问题;问题和原因
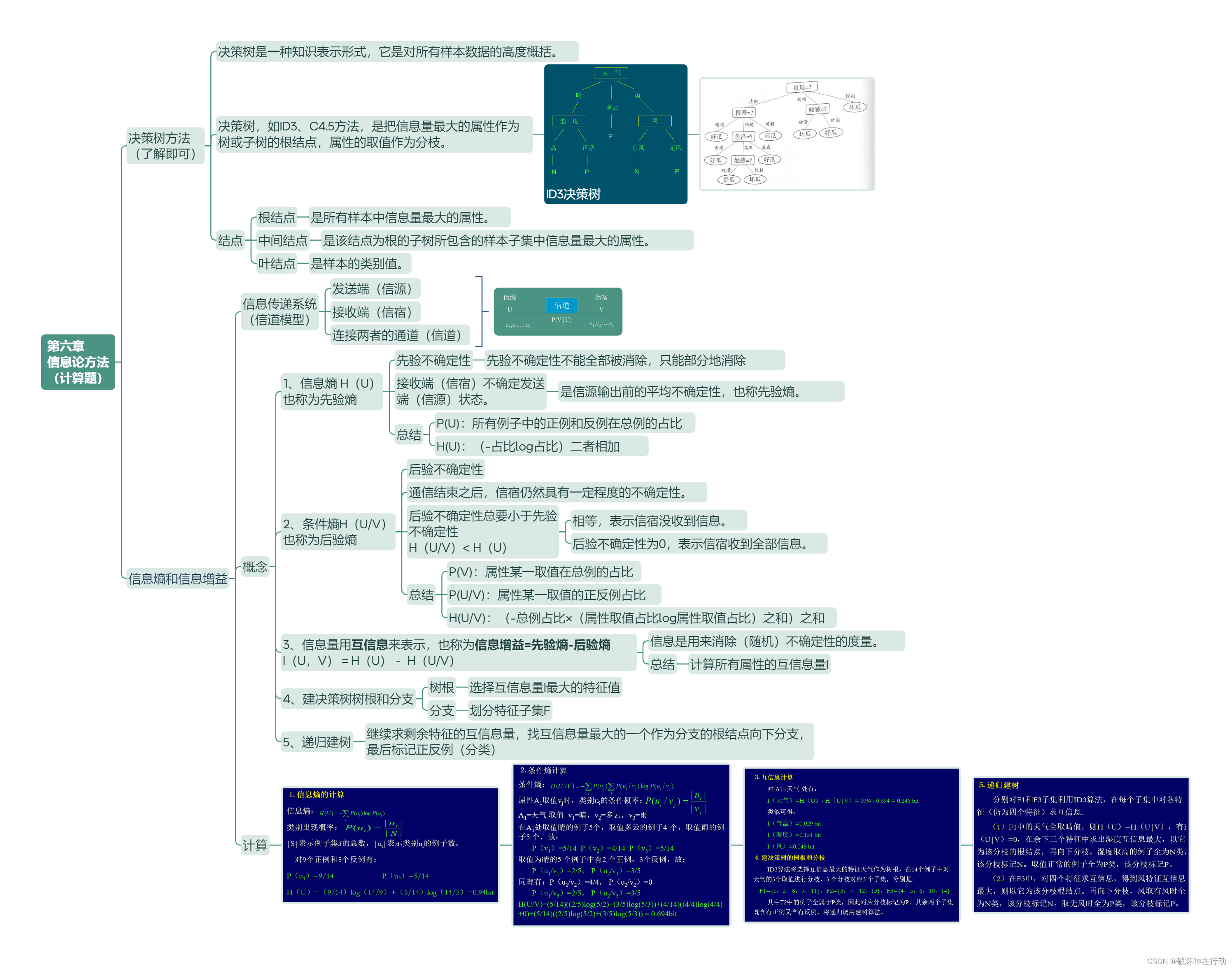
第五章 DM原理(了解即可)
KDD
概念:从数据中发现有用知识的整个过程。
过程
- 数据准备、DM、结果评估
数据准备的三个步骤?
数据选择,数据预处理,数据转换
DM
KDD过程中的一个特定步骤,它用专门算法从数据中抽取模式(patterns)。
按照DM任务采取不同方法
聚类方法 (结果未知)
在没有类别的数据中,按照"距离"远近聚集若干类别。
典型方法:k均值聚类算法,统计分析方法,机器学习方法,神经网络方法等
分类方法 (结果已知)
对有类别的数据,找出各类别的描述知识。
典型方法:ID3、C4.5、IBLE等分类算法
总结
有无类别
结果评估
数据质量好坏的两个影响因素?
DM技术的有效性
挖掘数据的质量和数量
总结:技术和数据
DM任务和分类
DM任务
(1)关联分析
- 两个或多个数据项的取值之间重复出现且概率很高时,它就存在某种关联,可以建立起这些数据项的关联规则。
(2)时序模式
- 通过时间序列搜索出重复发生概率较高的模式
(3)聚类
在没有类的数据中,按"距离"概念聚集成若干类。
距离
同一类别中个体之间的距离较小
而不同类别上的个体之间的距离偏大
(4)分类
在聚类的基础上,对已确定的类找出该类别的概念描述,它代表了这类数据的整体信息。
类的内涵描述
特征描述
- 对类中对象的共同特征的描述。
辨别性描述
- 对两个或多个类之间的区别的描述
(5)偏差检测
- 从数据分析中发现异常情况
(6)预测
- 利用历史数据找出变化规律,建立模型,并用此模型来预测未来数据的种类,特征等
什么是聚类和分类?
决策树知识
ps:在其基础上考计算题 (信息熵和信息增益)
决策树是一种常用的机器学习算法,用于分类和回归任务。
基本概念
- 决策树通过一系列的问题将数据分割成不同的分支,最终达到一个结论或决策。
构建过程
- 从根节点开始,选择一个特征和阈值进行分割,递归地在子节点上重复这个过程,直到满足停止条件。
特征选择
- 特征选择是决策树构建中的关键步骤,用于决定在每个节点上使用哪个特征进行分割。常见的特征选择方法包括信息增益、信息增益率和基尼不纯度。
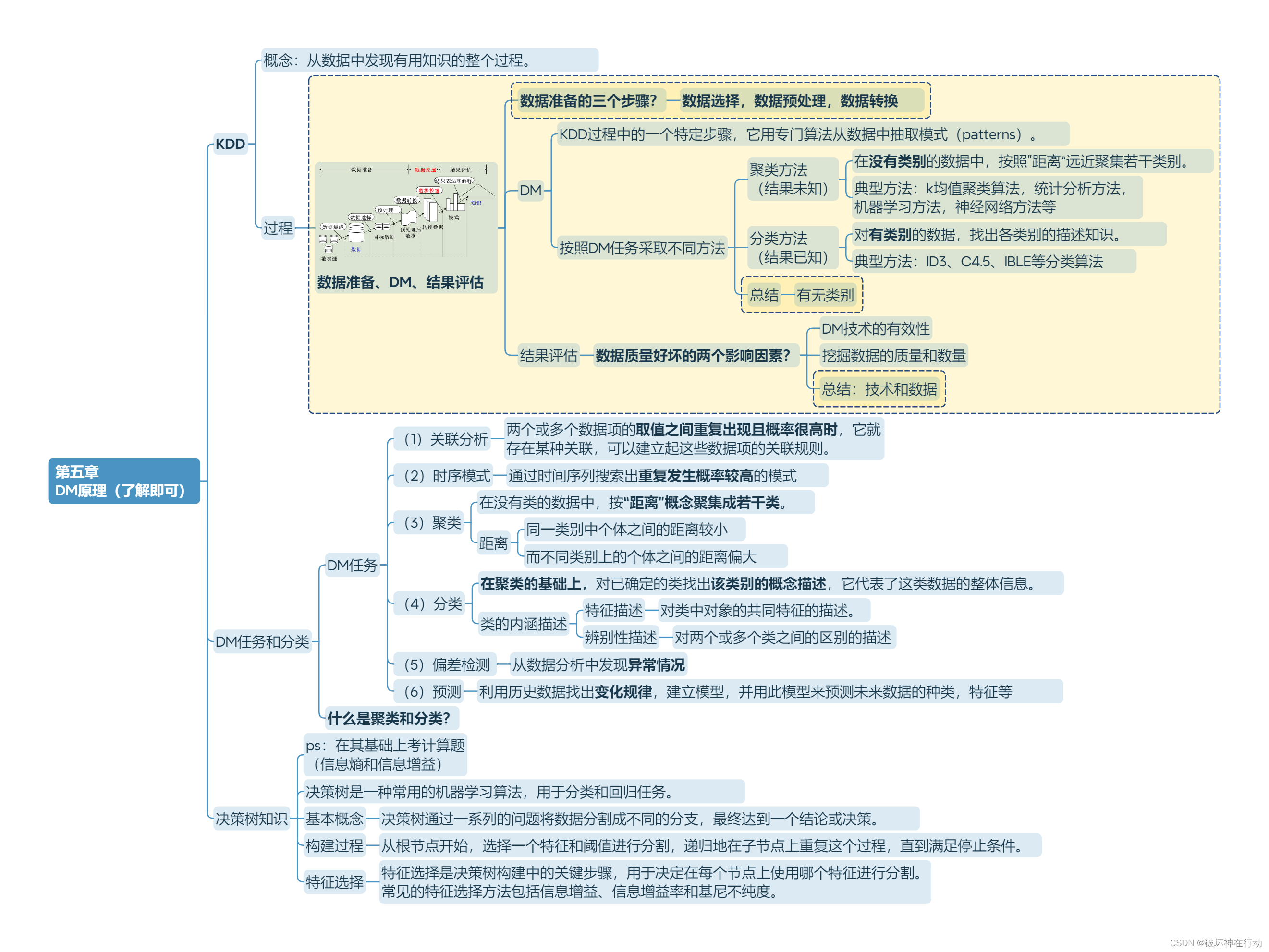
第六章 信息论方法 (计算题)
-
决策树方法 (了解即可)
-
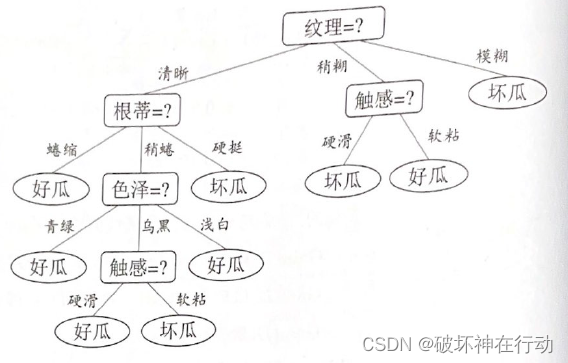
决策树是一种知识表示形式,它是对所有样本数据的高度概括。
-
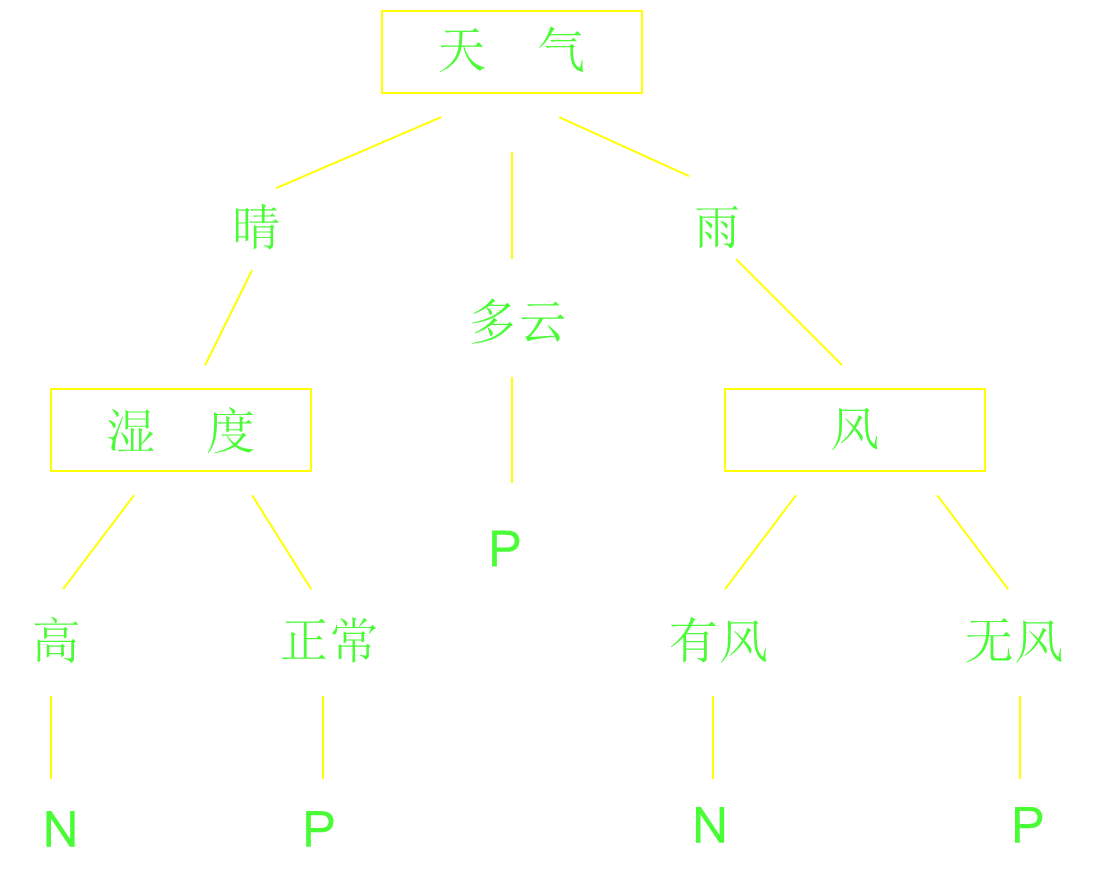
决策树,如ID3、C4.5方法,是把信息量最大的属性作为树或子树的根结点,属性的取值作为分枝。
-
ID3决策树
-
结点
-
根结点
- 是所有样本中信息量最大的属性。
-
中间结点
- 是该结点为根的子树所包含的样本子集中信息量最大的属性。
-
叶结点
- 是样本的类别值。
-
信息熵和信息增益
-
信息传递系统 (信道模型)
-
发送端(信源)
-
接收端(信宿)
-
连接两者的通道(信道)
-
-
概念
-
1、信息熵 H(U) 也称为先验熵
-
先验不确定性
- 先验不确定性不能全部被消除,只能部分地消除
-
接收端(信宿)不确定发送端(信源)状态。
- 是信源输出前的平均不确定性,也称先验熵。
-
总结
-
P(U):所有例子中的正例和反例在总例的占比
-
H(U):(-占比log占比)二者相加
-
-
-
2、条件熵H(U/V) 也称为后验熵
-
后验不确定性
-
通信结束之后,信宿仍然具有一定程度的不确定性。
-
后验不确定性总要小于先验不确定性 H(U/V)< H(U)
-
相等,表示信宿没收到信息。
-
后验不确定性为0,表示信宿收到全部信息。
-
-
总结
-
P(V):属性某一取值在总例的占比
-
P(U/V):属性某一取值的正反例占比
-
H(U/V):(-总例占比×(属性取值占比log属性取值占比)之和)之和
-
-
-
3、信息量用互信息来表示,也称为信息增益=先验熵-后验熵 I(U,V)=H(U)- H(U/V)
-
信息是用来消除(随机)不确定性的度量。
-
总结
- 计算所有属性的互信息量I
-
-
4、建决策树树根和分支
-
树根
- 选择互信息量I最大的特征值
-
分支
- 划分特征子集F
-
-
5、递归建树
- 继续求剩余特征的互信息量,找互信息量最大的一个作为分支的根结点向下分支,最后标记正反例(分类)
-
计算




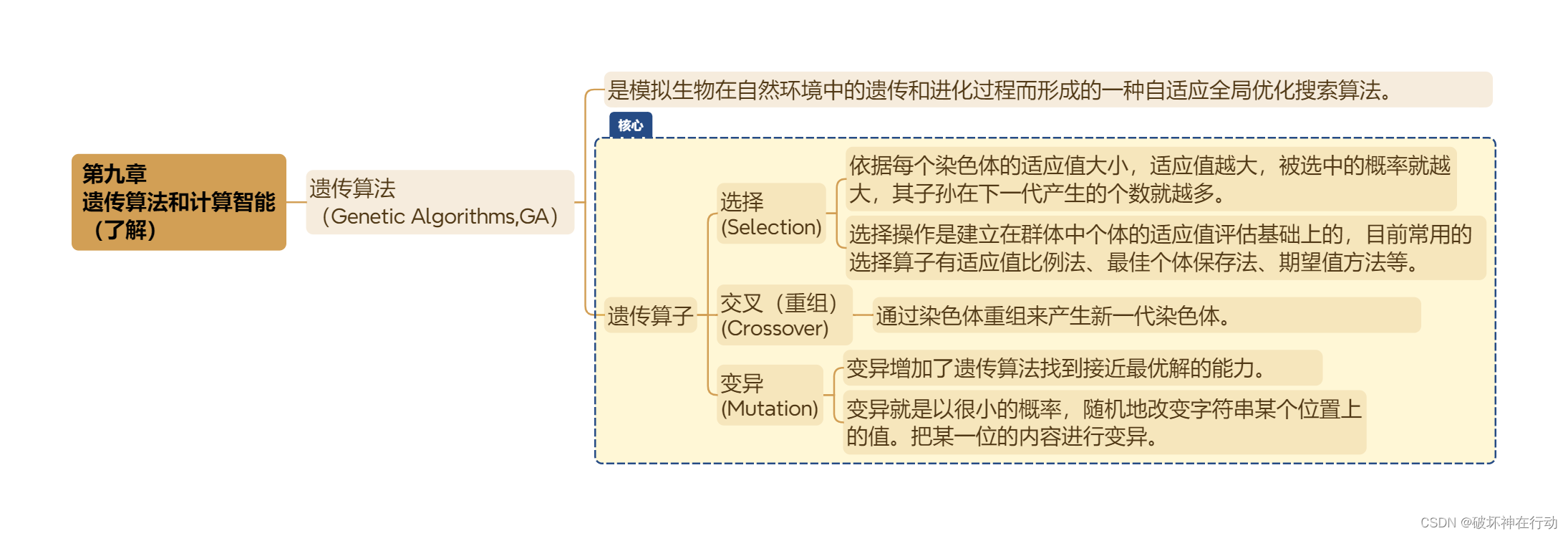
第九章 遗传算法和计算智能 (了解)
遗传算法 (Genetic Algorithms,GA)
是模拟生物在自然环境中的遗传和进化过程而形成的一种自适应全局优化搜索算法。
遗传算子
选择 (Selection)
依据每个染色体的适应值大小,适应值越大,被选中的概率就越大,其子孙在下一代产生的个数就越多。
选择操作是建立在群体中个体的适应值评估基础上的,目前常用的选择算子有适应值比例法、最佳个体保存法、期望值方法等。
交叉(重组) (Crossover)
- 通过染色体重组来产生新一代染色体。
变异 (Mutation)
变异增加了遗传算法找到接近最优解的能力。
变异就是以很小的概率,随机地改变字符串某个位置上的值。把某一位的内容进行变异。