ES的写入过程
ES支持的写操作
- create: create操作不同于put操作,put操作的时候如果当前put的数据存在则会被覆盖,如果put操作的时候加上操作类型create,如果数据存在则会返回失败,比如:PUT /pruduct/_create/1/
- delete:删除文档,ES对文档的删除是懒删除机制,即标记删除
- index:在ES中,写入操作被称为Index这里的Index为动词,即将数据创建在ES中的索引里面
- update:指向partial update,(全量替换,部分替换)
ES写入流程图解
- ES中数据写入均发生在Primary shard(主分片),当数据在Primary写入完成之后会同步到其他Relica Shard。如下图
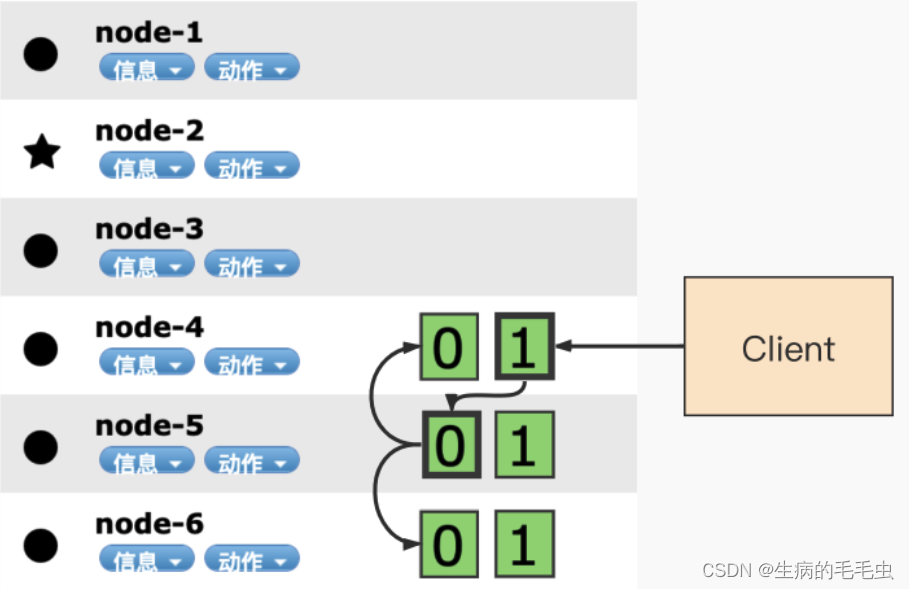
-
第一步:客户端发起请求到node4的1分片
-
第二步:node 4 通过文档id在路由表中的映射信息确定当前数据的位置为分片0,分片0的主分片位于node 5,将数据妆发到node5
-
第三步:数据在node 5写入,写入成功后数据的同步请求转发到副本所在的node 4和node 6
-
第四步:等待所有副本数据写入完成后,node5 返回结果给node4,node4 将结果返回给客户的
-
node 4 转到node 5 的依据是通过如下算法来完成的:
java
shard_num = hash(_routing)% num_primary_shards- _routing :默认值是文档id
- num_primary_shards:现有的分片总数
写一致性策略
- ES 5.x 之后,一致性策略配置:wait_for_active_shards 参数控制,默认1,
- 写入操作,必须等数据同步到 wait_for_active_shards 配置的制定个分片后才能返回成功,默认1个,最多是number_of_replicas + 1 也就是all
ES写入原理
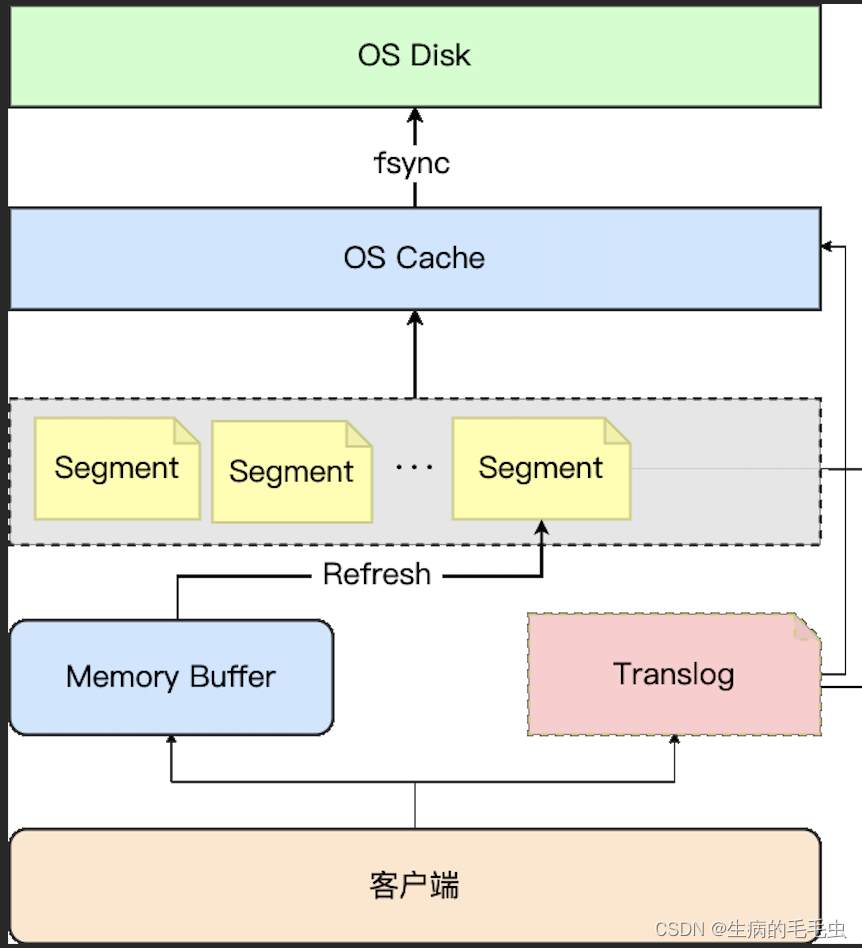
-
ES的写入优化和其他数据库存储类似,就是避免直接对磁盘进行操作,通过加缓存的方式,如果加一层缓存不行,那么久多加一层缓存,通过backup文件追加写的方式来做crash-safe。大体思路就是如此,流程如下
-
ES是用java实现的,在写入的时候为写入实现提供了一个缓冲区 Memory Buffer,数据显写入缓冲区,缓冲区固定大小
-
Memory Buffer 有空间阈值 10% JVM heap,时间阈值 1s钟,当任意一个满足的时候,ES会对MemoryBuffer 进行Refresh,将缓存中数据写入Segment
-
MemoryBuffer 写入Segment文件并没有落盘,而是生成了一个临时的Segment索引这部分数据存储在文件系统缓存中,此时就能查询到新写入的数据
-
因为缓存数据可能丢失,为了做crash-safe,es从Memory Buffer到生成Segment索引缓存同时会通过追加写的方式 写入translog
-
Es会定期进行flush ,将缓存中的Segment写入到磁盘,写完后,会讲Segment索引标记为可用,所以写入到查询有1s延迟
对Translog的控制(flush的时机)
- 配置一:index.translog.sync_interval
- 无论写入操作如何,translog 默认每隔 5s (可以设置更大时间)被 fsync 写入磁盘一次,不允许设置小于 100ms 的提交间隔。
- 配置二:index.translog.durability
- 同步刷盘还是异步刷盘,默认情况是fsync(同步刷盘)
- 配置三:index.translog.flush_threshold_size
- 也就是translog的容量大小,默认为 512mb. 在达到translog的最大容量的时候,会立刻停止写入同坐一次flush,晴空translog
refresh原理
- refresh的过程是从jvm的内存索引缓冲区 写入到 文件系统缓冲区(这个是两个缓存直接数据交换,消耗低)。
- 数据在进入文件缓存后,它可以像任何其他文件一样打开和读取。文件缓存是文件系统的一部分,这个位置由操作系统控制了
- 配置信息:index.refresh_interval:可以设置刷新的间隔时间
Segment 的Merge操作
- 由于默认每一秒都从缓冲区refresh 到Segment,所以会生成非常多的小数据量的Segment。而Segment段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
- Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。 这个就是Merge操作,Merge操作发生在Jvm 中
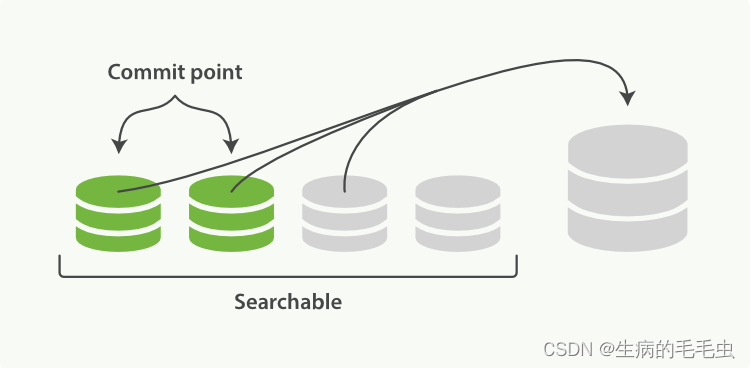
- Elasticsearch 中的一个 shard 是一个 Lucene 索引,一个 Lucene 索引被分解成段。段是存储索引数据的索引中的内部存储元素,并且是不可变的。较小的段会定期合并到较大的段中,并删除较小的段
- Merge操作是一个需要消耗大量的I/O和CPU资源的操作,会影响搜索性能。Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然 有足够的资源很好地执行。
写入性能调优
-
第一点:多Merge的限制:
- 原因:merge 过程发生在 JVM中,频繁的生成 Segmen 文件可能会导致频繁的触发 FGC,导致 OOM
- 方法一:增加refresh的间隔时间
- 方法二:增加Memory Buffer的空间阈值
-
生产经常面临的写入可以分为两种情况:
- 高频低量:高频的创建或更新索引或文档一般发生在 处理 C 端业务的场景下。
- 低频高量:一般情况为定期重建索引或批量更新文档数据。
具体优化配置
- 第一:增加 flush 时间间隔 ,目的减少写入磁盘的次数,减少磁盘IO频率
- 第二:增加index.refresh_interval 配置值,减少Segment文件创建,减少merge发生频率
- 第三:增加memory Buffer大小,减少Segment文件创建,减少merge发生频率,最小值 48MB< 默认值 JVM 空间的10% < 默认最大无限制
- 第四:关闭副本,当需要单次写入大量数据,或者就是es数据初始化的时候,建议关闭副本,暂停搜索服务,或选择在检索请求量谷值区间时间段来完成。通过index.number_of_replicas 为0 设置,同步完成后在复原
- 第一可以减少读写资源的抢占,读写分离
- 第二 副本的存在会导致主从之间频繁的进行数据同步,大大增加服务器的资源占用。
- 第五:使用多个工作线程,设置为 cpu 数 + 1
- 第六:避免使用避免使用稀疏数据,稀疏数据就是你有100 个字段,但是每条数据都只占用其中一个字段,这就是稀疏数据
- 第七:合理的max_result_window参数,分页返回的最大数值,默认值为10000,是JVM的一种保护机制
查询性能调优
- 首先明确:读写性能不可兼得
具体优化方法:
第一:避免单次召回大量数据
- 搜索引擎最擅长的事情是从海量数据中查询少量相关文档,而非单次检索大量文档。非常不建议动辄查询上万数据。如果有这样的需求,建议使用滚动查询,条件限制查询尽量减少返回数据量
第二:避免单个文档过大
- 鉴于默认http.max_content_length设置为 100MB,所以单个文档(一行数据)不要超过100M
第三:单次查询10条文档 好于 10次查询每次一条(批量的优势)
- 批量请求将产生比单文档索引请求更好的性能。但是每次查询多少文档最佳,不同的集群最佳值可能不同,为了获得批量请求的最佳阈值,建议在具有单个分片的单个节点上运行基准测试,测试方式可以逐次增加批量级别,观察索引速度取一个合适的量级
第四:给系统留足够的内存
- luncene数据Segment 的flush到磁盘是发生在缓存中的,因此要给OS cache预留足够的内从大小
第五:预索引
- 在能预知的业务场景下,我们给必须的查询字段创建索引,例如我们知道每个文档都有 price 价格字段,那么我们预先打开 price的doc values属性来创建正排索引,之后通过price来完成聚合查询。
第六:使用 filter 代替 query
- filter查询的是是不计算评分的,另外filter有相应的缓存机制,可以提高查询效率。query是要对查询的每个结果计算相关性得分的因此更慢,如果我们认为评分排序对业务并不重要,可以考虑
第七:避免深度分页
第八:使用 Keyword 类型
- 并非所有数值数据都应映射为数值字段数据类型。Elasticsearch为 查询优化数字字段,例如integeror long。如果不需要范围查找,对于 term查询而言,keyword 比 integer 性能更好。只不过keyword只能是等值查询
第九:避免使用脚本
- Scripting是Elasticsearch支持的一种专门用于复杂场景下支持自定义编程的强大的脚本功能。相对于 DSL 而言,脚本的性能更差,DSL能解决 80% 以上的查询需求,如非必须,尽量避免使用 Script