可扩展性
负载均衡
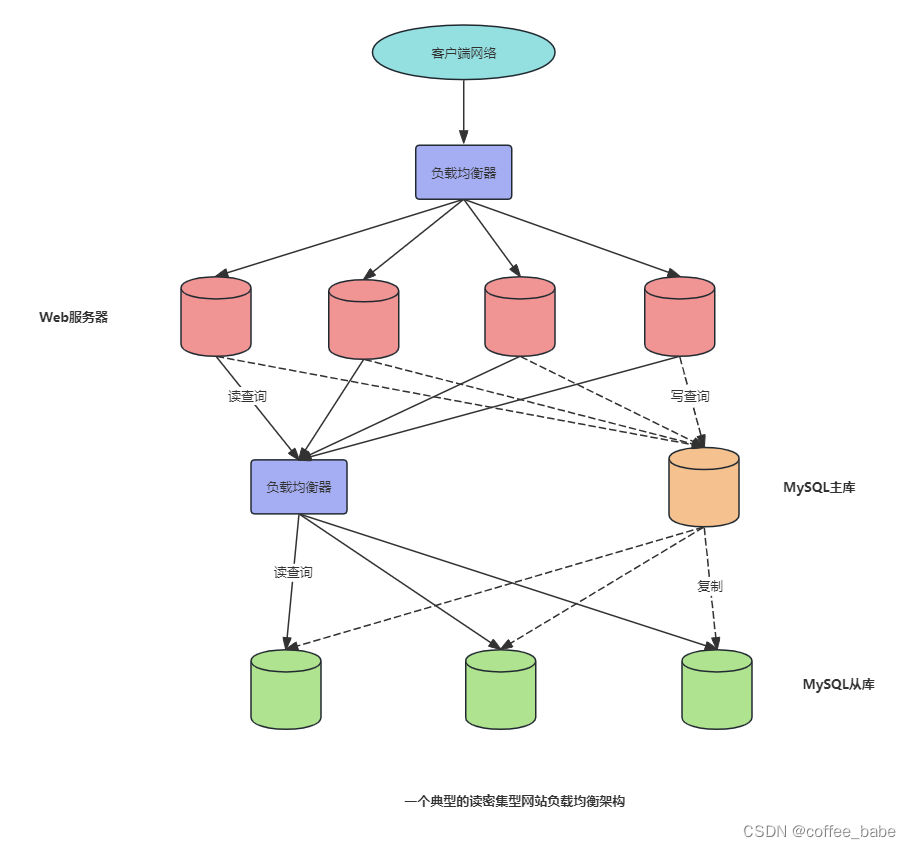
负载均衡的基本思路很简单:在一个服务器集群中尽可能地平均负载量。通常的做法是在服务器前端设置一个负载均衡器(一般是专门的硬件设备)。然后负载均衡器将请求的连接路由到最空闲的可用服务器。如图显示了一个典型的大型网站负载均衡设置,其中一个负载均衡器用于HTTP流量,另一个用于MySQL访问。负载均衡有五个常见目的。
- 1.可扩展性
负载均衡对某些扩展策略有所帮助,例如读写分离时从备库读数据 - 2.高效性
负载均衡有助于更有效地使用资源,因为它能够控制请求被路由到何处。如果服务器器处理能力各不相同,这就尤为重要:你可以把更多的工作分配给性能更好的机器 - 3.可用性
一个灵活的负载均衡解决方案能够使用时刻保持可用的服务器 - 4.透明性
客户端无须知道是否存在负载均衡设置,也不需要关心在负载均衡器的背后有多少机器,它们的名字是什么。负载均衡器给客户端看到的只是一个虚拟的服务器 - 5.一致性
如果应用是有状态的(数据库事务、网站会话等),那么负载均衡器就应该将相关的查询指向同一个服务器,以防止状态丢失。应用无须跟踪到底连接的是哪个服务器。
在与MySQL相关的领域里,负载均衡架构通常和数据分片及复制紧密相关。你可以把负载均衡和高可用性结合在一起,部署到应用的任一层次上。例如,可以在MySQL Cluster集群的多个SQl节点上做负载均衡,也可以在多个数据中心间作负载均衡,其中每个数据中心又可以使用数据分片架构,每个节点实际上是拥有多个备库的主------主复制对结构,这里又可以作负载均衡。对于高可用性策略也同样如此:在一个架构里可以配置多层的故障转移机制。负载均衡有许多微妙之处,举个例子,其中一个挑战就是管理读/写策略。有些负载均衡技术本身能够实现这一点,但其他的则需要应用自己知道哪些节点是可读的或可写的。在决定如何实现负载均衡时,应该考虑到这些因素。有许多负载均衡解决方案可以使用,从诸如Wackamole这样基于端点的(peer-based)实现,到DNS、LVS(Linux Virtual Server)硬件负载均衡器、TCP代理、MySQL Proxy,以及在应用中管理负载均衡。最普遍的策略是使用硬件负载均衡器,大多是使用HAProxy,它看起来很流行并且工作得很好。还有一些人使用TCP代理,例如Pen.但MySQL Proxy用得并不多
直接连接
有些人认为负载均衡就是配置在应用和MySQL服务器之间的东西。但这并不是唯一的负载均衡方法。你可以在保持应用和MySQL连接的情况下使用负载均衡。事实上,集中化的负载均衡系统只有在存在一个对等置换的服务器池时才能很好工作。如果应用需要做一些决策,例如在悲苦上执行读操作是否安全,就需要直接连接到服务器。除了可能出现的一些特定逻辑,应用为负载均衡做决策是非常高效的。例如,如果有两个完全相同的备库,你可以使用其中的一个来处理特定分片的数据查询,另一个处理其他的查询。这样能够有效利用备库的内存,因为每个备库只会缓存一部分数据。如果其中一个备库失效,另外一个备库拥有所有的数据,仍然能提供服务。
1.复制上的读/写分离
MySQL复制产生了多个数据副本,你可以选择在悲苦还是主库上执行查询。由于备库复制是异步的,因此主要的难点是如何处理备库上的脏数据。应该将备库用作只读的,而主库可以同时处理读和写查询。通常需要修改应用以适应这种分离需求。然后应用就可以使用主库来进行写操作,并将读操作分配到主库和备库上;如果不太关心数据是否是脏的,可以使用备库,而对需要即时数据的请求使用主库。我们将这种称为读/写分离。如果使用的是主动------被动模式的主------主复制对,同样也要考虑这个问题。使用这种配置时,只有主动服务器接受写操作。如果能够接受读到脏数据,可以将读分配给被动服务器。
最大的问题时如何避免由于读了脏数据引起的奇怪问题。一个典型的例子时当一个用户做了某些修改,例如增加了一条博客文章的评论,然后重新加载页面,但并没有看到更新,因为应用从备库读取到了脏的数据。比较常见的读/写分离方法如下:
- 1.基于查询分离
最简单的分离方法时将所有不能容忍脏数据的读和写查询分配到主动或者主库服务器上。其他的读查询分配到备库或者被动服务器上。该策略很容易实现,但事实上无法有效地使用备库,因为只有很少的查询能容忍脏数据 - 2.基于脏数据分离
这是对基于查询分离方法的小改进。徐奥做一些额外的工作,让应用检查复制延迟,以确定备库数据是否太旧。许多报表类应用都使用这个策略:只需要晚上加载到备库即可,它们并不关心是不是100%跟上了主库 - 3.基于会话分离
另一个决定能否从备库读数据的稍微复杂一点的方法时判断用户自己是否修改了数据,用户不需要看到其他用户的最新数据,但需要看到自己的更新。可以在会话层设置一个标记位,表明做了更新,就将该用户的查询在一段时间内总是指向主库。这是我们通常推荐的策略,因为它是在简单和有效性之间的一种很好的妥协。如果有足够的想象力,可以把基于会话的分离方法和复制延迟监控结合起来。如果用户在10秒前更新了数据,而所有备库延迟在5秒内,就可以安全地从备库中读取数据,但为整个会话选择同一个备库是一个很好的主意,否则用户可能会奇怪有些备库的更新速度比其他服务器要慢。 - 4.基本版本分离
这和基于会话的分离方法相似:你可以跟踪对象的版本好以及/或者时间戳,通过从备库读取对象的版本或时间戳来判断数据是否足够新。如果备库的数据太久,可以从主库获取最新的数据。即使对象本身没有变化,但如果是顶层对象,只要下面的任何对象有比那花,也可以增加版本好,这简化了脏数据检查(只需要检查顶层对象一处就能判断是否有更新)。例如,在用户发表了一篇新文章后,可以更新用户的版本。这样就会从主库去读取数据了 - 5.基于全局版本/会话分离
这个办法是基于版本分离和基于会话分离的变种。当应用执行写操作时,在提交事务后,执行一次SHOW MASTER STATUS操作。然后在缓存中存储主库日志坐标,作为被修改对象以及/或者会话的版本号。当应用连接到备库时,执行SHOW SLAVE STATUS并将备库上的坐标和缓存中的版本号相对比。如果备库相比记录点更新,就可以安全地读取备库数据。
大多数读/写分离解决方案都需要监控复制延迟来决策读查询的分配,不管时通过复制或负载均衡器,或是一个中间系统。如果这么做,需要注意通过SHOW SLAVE STATUS得到的Seconds_behind_master列的值并不能准确地用于监控延迟。Percona Toolkit中的pt-heartbeat工具能够帮助监控延迟,并维护元数据,例如二进制日志未知,这可以减轻之前我们讨论的一些策略存在的问题。
如果不在乎用昂贵的硬件来承载压力,也就可以不适用复制来扩展读操作,这样当然更简单。这可以避免在主备上分离读的复杂性。有些人认为这很有意义;也有人认为浪费硬件。这种分歧时由于不同的目的引起的:你是只需要可扩展性,还是要同时具有可扩展性和高利用率?如果需要高利用率,那么备库除了保存数据副本还需要承担其他任务,就不得不处理这些额外的复杂度