看api看麻了不知道意义在哪里,所以就简单总结点我觉得有用的东西
基本数据结构解析
分为了文档,索引和映射
索引可以理解为一张表,映射描述了索引的数据结构,而文档就是一个个具体的行
所以一般我们需要在申明索引的时候同时申明映射,然后就可以对索引进行增删改文档了。如果对索引的映射有调整,那就得直接删除索引重建了。
在查询的时候,我们可以使用不同的关键字达到不同效果,比如term就是全词匹配,fuzzy就是对当前词语模糊匹配,multi_match,query_string就是对传入的词语分词后再匹配
值得一提的是spring-data支持elastic search,我们可以在spring中直接进行依赖对接
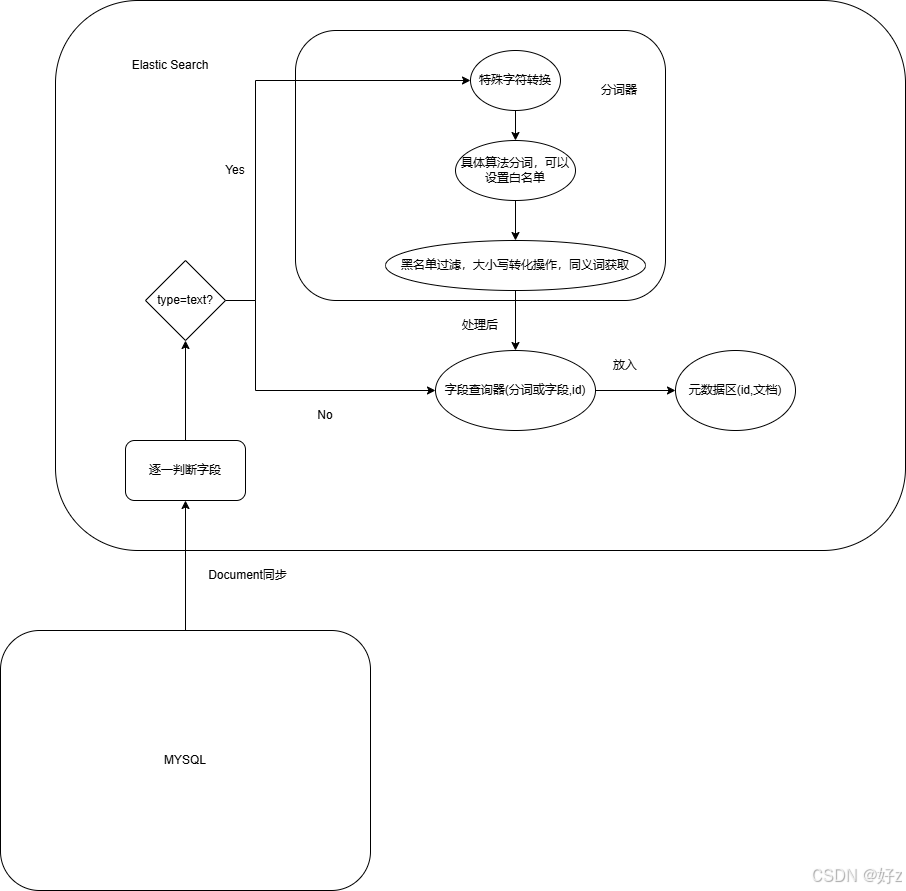
基本架构分析图