开发人员在编写网络爬虫程序时若遇到解析网页数据的问题,则需要花费大量的时间编
写与测试路径表达式,以确认是否可以解析出所需要的数据。为帮助开发人员在网页上直接
测试路径表达式是否正确,我们在这里推荐一款比较好用的 XPath 开发工具------ XPath Helper 。
XPath Helper 是一款运行在 Chrome 浏览器上的插件,它支持在网页上单击元素生成路径
表达式,也支持对照网页源代码手动编写路径表达式。在使用 XPath Helper 进行测试之前,
我们需要先在 Chrome 浏览器上添加 XPath Helper 插件。下面为大家分别介绍安装与使用 XPath
Helper 插件
1.安装 XPath Helper 插件
安装 XPath Helper 插件的方式比较简单。我们既可以通过 Chrome 网上应用店进行安装,
也可以通过下载到本地的 XPathHelper.crx 文件进行安装。在这里,我们以 XPathHelper.crx 文
件为例演示如何安装 XPath Helper 插件,具体步骤如下。
( 1 )在 Chrome 浏览器的右上角单击" "按钮,打开自定义及控制 Google Chrome 菜单,
在该菜单中单击"更多工具"→"扩展程序"进入扩展程序页面,如图 4-2 所示。
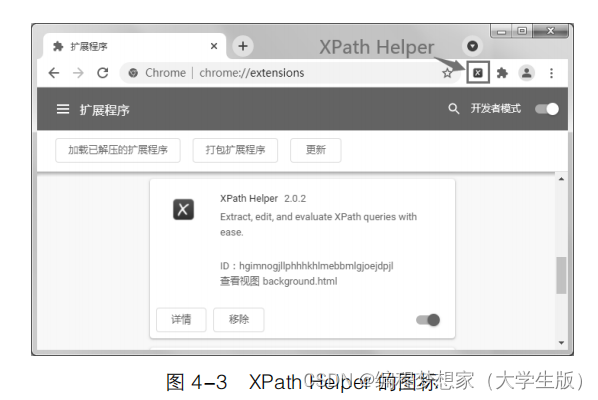
( 2 )将 XPathHelper.crx 文件拖入扩展程序页面,可以看到该页面中增加了扩展程序 XPath
Helper ,然后打开该扩展程序对应的开启按钮,此时扩展程序页面的右上角位置显示了 XPath
Helper 的图标 ,如图 4-3 所示。
( 3 )在图 4-3 中,单击 图标可以看到浏览器顶部弹出一个 XPath Helper 界面,具体如
图 4-4 所示。

在图 4-4 中,界面左侧的编辑区域用于输入路径表达式,右侧区域用于展示该路径表达式
选取的结果,并且会将结果总数目(默认显示的值为 0 )显示到 RESULTS 后面的括号里。
2.使用 XPath Helper 插件
下面以豆瓣网站上喜剧电影排行榜页面为例,为大家分步骤演示如何使用 XPath Helper
工具测试路径表达式,具体步骤如下。
(1 )在浏览器中打开豆瓣电影首页,在该页面中单击"排行榜" → "喜剧"进入喜剧电
影排行榜首页。喜剧电影排行榜首页中默认展示 20 部电影,当滚动条滑至页面底部时,会有
新的电影加载到页面中。在该页面顶部第一部电影名称"美丽人生"的上方单击鼠标右键,
打开快捷菜单,在该菜单中选择"检查"。页面底部弹出了 Elements 的面板,并定位到了电影
名称"美丽人生"对应元素源代码的位置,具体如图 4-5 所示。

(2 )分析图 4-5 中元素的层次结构后,推断出最终的路径表达式可以为:
//div@class='movie-info'/div/span/a/text()
需要说明的是,路径表达式并不唯一,既可以是从根节点开始的绝对路径,也可以是从
任意节点开始的相对路径。
(3 )打开 XPath Helper 工具,在左侧的编辑区域中输入上述路径表达式。此时右侧区域
中展示了路径表达式选取的结果及数目,如图 4-6 所示。

从图 4-6 中可以看出,根据左边的路径表达式,该页面展示了所有的电影名称。