- 开发语言:Python
- 框架:flask
- Python版本:python3.8
- 数据库:mysql 5.7
- 数据库工具:Navicat12
- 开发软件:PyCharm
系统展示
系统首页
热门书籍
公告栏
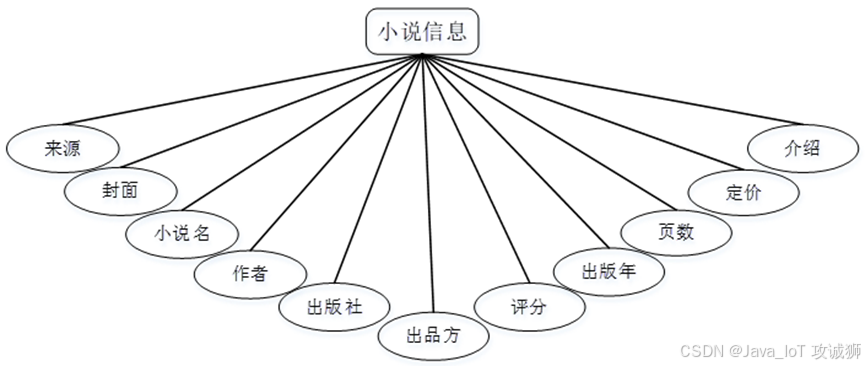
小说信息
在线反馈
个人中心
管理员登录

管理员功能界面
用户管理

热门书籍管理

公告栏管理

小说信息管理
在线反馈管理
系统管理
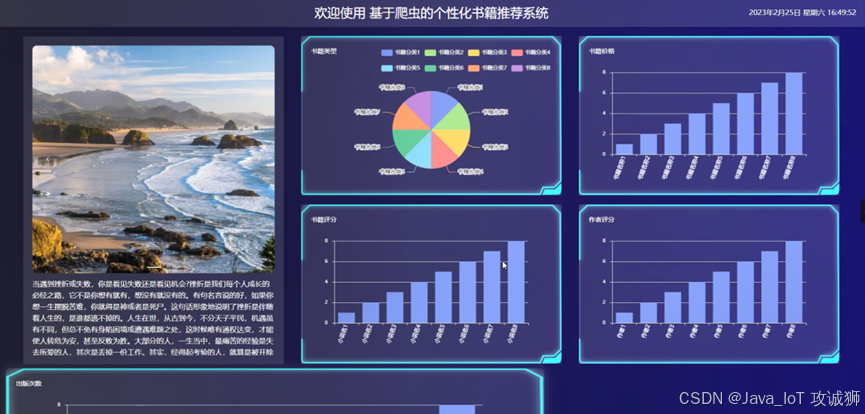
看板展示
摘要
近年来,随着互联网的蓬勃发展,企事业单位对信息的管理提出了更高的要求。以传统的管理方式已无法满足现代人们的需求。为了迎合时代需求,优化管理效率,各种各样的管理系统应运而生,随着各行业的不断发展,个性化书籍推荐系统建设也逐渐进入了信息化的进程。
这个系统的设计主要包括系统页面的设计和方便用户互动的后端数据库,而前端软件的开发则需要良好的数据处理能力、友好的界面和易用的功能。
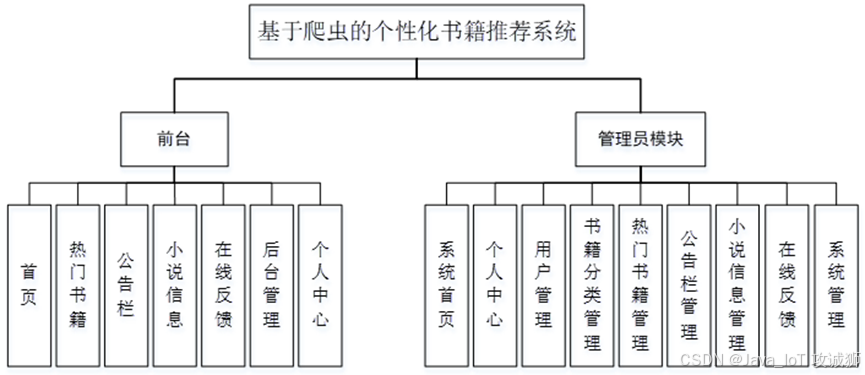
数据要被工作人员通过界面操作传输至数据库中。通过研究,以MySQL为后端数据库,以PYTHON为前端技术,以IDEA为开发平台,采用DJANGO架构,建立一个提供个人中心、用户管理、书籍分类管理、热门书籍管理、公告栏管理、小说信息管理、在线反馈、系统管理等必要功能的、稳定的个性化书籍推荐系统。
研究背景
随着网络的飞速发展,网络技术的应用越来越广泛,而信息技术的飞速发展,计算机管理系统的优势也逐渐体现出来,大量的计算机电子信息已经进入千家万户。基于爬虫的个性化书籍推荐系统已跟随信息时代的重要代表,由于涉及的数据量大,以往人工管理已难以维护,因此采用信息技术进行管理。计算机系统管理模式代替了人工管理的方式,比以往人工管理的方式,采用计算机使个性化书籍推荐信息查询方便,信息准确性高,降低成本,提高效率,本系统的开发主要以个性化书籍推荐为对象,根据功能需求开发信息系统。
关键技术
Python是解释型的脚本语言,在运行过程中,把程序转换为字节码和机器语言,说明性语言的程序在运行之前不必进行编译,而是一个专用的解释器,当被执行时,它都会被翻译,与之对应的还有编译性语言。
同时,这也是一种用于电脑编程的跨平台语言,这是一门将编译、交互和面向对象相结合的脚本语言(script language)。
Flask是一个使用Python编写的轻量级Web应用框架。它被称为一个"微框架"(microframework),因为它只提供Web应用所需的最核心的功能,如路由、会话管理和模板引擎等,而不像一些更全面的框架那样包含数据库层、表单处理等功能。然而,Flask的扩展生态系统非常丰富,开发者可以通过添加扩展来为Flask应用添加这些额外的功能。
Vue是一款流行的开源JavaScript框架,用于构建用户界面和单页面应用程序。Vue的核心库只关注视图层,易于上手并且可以与其他库或现有项目轻松整合。
MYSQL数据库运行速度快,安全性能也很高,而且对使用的平台没有任何的限制,所以被广泛应运到系统的开发中。MySQL是一个开源和多线程的关系管理数据库系统,MySQL是开放源代码的数据库,具有跨平台性。
B/S(浏览器/服务器)结构是目前主流的网络化的结构模式,它能够把系统核心功能集中在服务器上面,可以帮助系统开发人员简化操作,便于维护和使用。
系统分析
对系统的可行性分析以及对所有功能需求进行详细的分析,来查看该系统是否具有开发的可能。
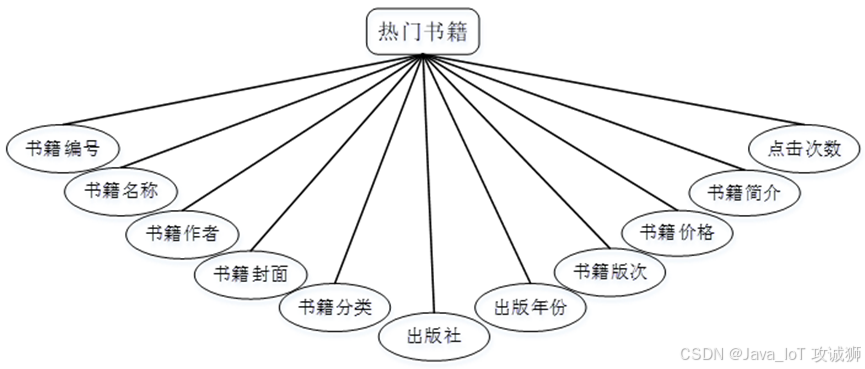
系统设计
功能模块设计和数据库设计这两部分内容都有专门的表格和图片表示。
系统实现
当人们打开系统的网址后,首先看到的就是首页界面。在这里,人们能够看到系统的导航条,通过导航条导航进入各功能展示页面进行操作。用户注册登录进入系统前台,点击后台管理可以对个人信息和密码进行修改操作。管理员进入主页面,主要功能包括对个人中心、用户管理、书籍分类管理、热门书籍管理、公告栏管理、小说信息管理、在线反馈、系统管理等进行操作。管理员进行爬取数据后,点击主页面右上角的看板,可以查看到系统简介、书籍类型、书籍价格、书籍评分、作者评分、出版次数等实时的分析图进行可视化管理;
代码实现
python
# 小说信息
class XiaoshuoxinxiSpider(scrapy.Spider):
name = 'xiaoshuoxinxiSpider'
spiderUrl = 'https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start=0&type=T'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if plat == 'windows_bak':
pass
elif plat == 'linux' or plat == 'windows':
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, '8dd17_xiaoshuoxinxi') == 1:
cursor.close()
connect.close()
self.temp_data()
return
list = response.css('ul.subject-list li.subject-item')
for item in list:
fields = XiaoshuoxinxiItem()
fields["laiyuan"] = self.remove_html(item.css('div.pic a.nbg::attr(href)').extract_first())
if fields["laiyuan"].startswith('//'):
fields["laiyuan"] = self.protocol + ':' + fields["laiyuan"]
elif fields["laiyuan"].startswith('/'):
fields["laiyuan"] = self.protocol + '://' + self.hostname + fields["laiyuan"]
fields["fengmian"] = self.remove_html(item.css('div.pic a.nbg img::attr(src)').extract_first())
fields["xiaoshuoming"] = self.remove_html(item.css('div.info h2 a::attr(title)').extract_first())
detailUrlRule = item.css('div.pic a.nbg::attr(href)').extract_first()
if self.protocol in detailUrlRule:
pass
elif detailUrlRule.startswith('//'):
detailUrlRule = self.protocol + ':' + detailUrlRule
else:
detailUrlRule = self.protocol + '://' + self.hostname + detailUrlRule
fields["laiyuan"] = detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, callback=self.detail_parse)
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
try:
if '(.*?)' in '''div#info span a::text''':
fields["zuozhe"] = re.findall(r'''div#info span a::text''', response.text, re.S)[0].strip()
else:
if 'zuozhe' != 'xiangqing' and 'zuozhe' != 'detail' and 'zuozhe' != 'pinglun' and 'zuozhe' != 'zuofa':
fields["zuozhe"] = self.remove_html(response.css('''div#info span a::text''').extract_first())
else:
fields["zuozhe"] = emoji.demojize(response.css('''div#info span a::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''a[href^="https://book.douban.com/press"]::text''':
fields["chubanshe"] = re.findall(r'''a[href^="https://book.douban.com/press"]::text''', response.text, re.S)[0].strip()
else:
if 'chubanshe' != 'xiangqing' and 'chubanshe' != 'detail' and 'chubanshe' != 'pinglun' and 'chubanshe' != 'zuofa':
fields["chubanshe"] = self.remove_html(response.css('''a[href^="https://book.douban.com/press"]::text''').extract_first())
else:
fields["chubanshe"] = emoji.demojize(response.css('''a[href^="https://book.douban.com/press"]::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''a[href^="https://book.douban.com/producers"]::text''':
fields["chupinfang"] = re.findall(r'''a[href^="https://book.douban.com/producers"]::text''', response.text, re.S)[0].strip()
else:
if 'chupinfang' != 'xiangqing' and 'chupinfang' != 'detail' and 'chupinfang' != 'pinglun' and 'chupinfang' != 'zuofa':
fields["chupinfang"] = self.remove_html(response.css('''a[href^="https://book.douban.com/producers"]::text''').extract_first())
else:
fields["chupinfang"] = emoji.demojize(response.css('''a[href^="https://book.douban.com/producers"]::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''strong[class="ll rating_num "]::text''':
fields["pingfen"] = re.findall(r'''strong[class="ll rating_num "]::text''', response.text, re.S)[0].strip()
else:
if 'pingfen' != 'xiangqing' and 'pingfen' != 'detail' and 'pingfen' != 'pinglun' and 'pingfen' != 'zuofa':
fields["pingfen"] = self.remove_html(response.css('''strong[class="ll rating_num "]::text''').extract_first())
else:
fields["pingfen"] = emoji.demojize(response.css('''strong[class="ll rating_num "]::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''<span class="pl">出版年:</span> (.*?)<br/>''':
fields["chubannian"] = re.findall(r'''<span class="pl">出版年:</span> (.*?)<br/>''', response.text, re.S)[0].strip()
else:
if 'chubannian' != 'xiangqing' and 'chubannian' != 'detail' and 'chubannian' != 'pinglun' and 'chubannian' != 'zuofa':
fields["chubannian"] = self.remove_html(response.css('''<span class="pl">出版年:</span> (.*?)<br/>''').extract_first())
else:
fields["chubannian"] = emoji.demojize(response.css('''<span class="pl">出版年:</span> (.*?)<br/>''').extract_first())
except:
pass
try:
if '(.*?)' in '''<span class="pl">页数:</span> (.*?)<br/>''':
fields["yeshu"] = re.findall(r'''<span class="pl">页数:</span> (.*?)<br/>''', response.text, re.S)[0].strip()
else:
if 'yeshu' != 'xiangqing' and 'yeshu' != 'detail' and 'yeshu' != 'pinglun' and 'yeshu' != 'zuofa':
fields["yeshu"] = self.remove_html(response.css('''<span class="pl">页数:</span> (.*?)<br/>''').extract_first())
else:
fields["yeshu"] = emoji.demojize(response.css('''<span class="pl">页数:</span> (.*?)<br/>''').extract_first())
except:
pass
try:
if '(.*?)' in '''<span class="pl">定价:</span> (.*?)<br/>''':
fields["dingjia"] = re.findall(r'''<span class="pl">定价:</span> (.*?)<br/>''', response.text, re.S)[0].strip()
else:
if 'dingjia' != 'xiangqing' and 'dingjia' != 'detail' and 'dingjia' != 'pinglun' and 'dingjia' != 'zuofa':
fields["dingjia"] = self.remove_html(response.css('''<span class="pl">定价:</span> (.*?)<br/>''').extract_first())
else:
fields["dingjia"] = emoji.demojize(response.css('''<span class="pl">定价:</span> (.*?)<br/>''').extract_first())
except:
pass
try:
if '(.*?)' in '''div.intro''':
fields["detail"] = re.findall(r'''div.intro''', response.text, re.S)[0].strip()
else:
if 'detail' != 'xiangqing' and 'detail' != 'detail' and 'detail' != 'pinglun' and 'detail' != 'zuofa':
fields["detail"] = self.remove_html(response.css('''div.intro''').extract_first())
else:
fields["detail"] = emoji.demojize(response.css('''div.intro''').extract_first())
except:
pass
return fields
# 去除多余html标签
def remove_html(self, html):
if html == None:
return ''
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html).strip()
# 数据库连接
def db_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
# 数据缓存源
def temp_data(self):
connect = self.db_connect()
cursor = connect.cursor()
sql = '''
insert into xiaoshuoxinxi(
laiyuan
,fengmian
,xiaoshuoming
,zuozhe
,chubanshe
,chupinfang
,pingfen
,chubannian
,yeshu
,dingjia
,detail
)
select
laiyuan
,fengmian
,xiaoshuoming
,zuozhe
,chubanshe
,chupinfang
,pingfen
,chubannian
,yeshu
,dingjia
,detail
from 8dd17_xiaoshuoxinxi
where(not exists (select
laiyuan
,fengmian
,xiaoshuoming
,zuozhe
,chubanshe
,chupinfang
,pingfen
,chubannian
,yeshu
,dingjia
,detail
from xiaoshuoxinxi where
xiaoshuoxinxi.laiyuan=8dd17_xiaoshuoxinxi.laiyuan
and xiaoshuoxinxi.fengmian=8dd17_xiaoshuoxinxi.fengmian
and xiaoshuoxinxi.xiaoshuoming=8dd17_xiaoshuoxinxi.xiaoshuoming
and xiaoshuoxinxi.zuozhe=8dd17_xiaoshuoxinxi.zuozhe
and xiaoshuoxinxi.chubanshe=8dd17_xiaoshuoxinxi.chubanshe
and xiaoshuoxinxi.chupinfang=8dd17_xiaoshuoxinxi.chupinfang
and xiaoshuoxinxi.pingfen=8dd17_xiaoshuoxinxi.pingfen
and xiaoshuoxinxi.chubannian=8dd17_xiaoshuoxinxi.chubannian
and xiaoshuoxinxi.yeshu=8dd17_xiaoshuoxinxi.yeshu
and xiaoshuoxinxi.dingjia=8dd17_xiaoshuoxinxi.dingjia
and xiaoshuoxinxi.detail=8dd17_xiaoshuoxinxi.detail
))
limit {0}
'''.format(random.randint(20,30))
cursor.execute(sql)
connect.commit()
connect.close()系统测试
白盒测试,主要使用代码检查方法,由测试人员根据业务需求对系统批量程序的代码或脚本进行检查,较容易发现一些直观的问题,比如判断条件中的比较符号写反、判断条件的遗漏、边界值的遗漏等。此外,代码检查有助于加深测试人员对数据处理功能的理解,进行黑盒测试案例设计时更有针对性。
黑盒测试,即运行批量程序,在运行过程中检查是否出现报错信息与中断,运行结束后对生成的数据表或数据文件,即目标表检查。目标表检查是数据处理类系统测试最主要的内容,通过检查间接验证系统实现的加工逻辑是否正确满足业务需求。目标表检查一般是通过编写SQL语句查询的方式实现。
结论
系统在功能实现上主要包括对个人中心、用户管理、书籍分类管理、热门书籍管理、公告栏管理、小说信息管理、在线反馈、系统管理等功能进行管理。在项目开发方面,采用django框架集和mysql数据库进行开发,使系统开发更加稳定、易于维护。在使用方面,该系统节省了大量的人力和物力,具有响应速度快、页面美观等优点。
作为一个个性化书籍推荐系统,该系统具有简单、方便、易于管理的优点。由于对框架和技术语言的掌握不够,系统只能实现基本功能,不能突破创新。希望我的技术能够得到改进和创新,从而完善和创个性化书籍推荐信息管理体制。