大家好,我是带我去滑雪!
东方财富网是中国领先的金融服务网站之一,以提供全面的金融市场数据、资讯和交易工具而闻名。其受欢迎的"股吧"论坛特别适合爬取股票评论,东方财富网的股吧聚集了大量投资者和金融分析师,他们经常在此分享投资观点、分析报告和市场动态。这些内容对于进行市场情绪分析、投资策略研究或金融模型训练非常有价值。此外,东方财富网的用户基础庞大且活跃,每日都有大量的新帖子和评论产生。这种活跃的讨论环境可以提供实时的市场反馈和投资者情绪的动态变化。相比于其他金融网站,东方财富网的股吧系统更加集中和规范,容易进行数据爬取和分析。每个股票的讨论都有其专属的页面和结构化的评论区,便于自动化工具识别和抽取数据。
在2022年的时候,我就尝试爬取了东方财富网的股吧评论,链接如下:http://t.csdnimg.cn/F45MZ。但是最近做文本的情感分析时,需要最新的上证指数评论时,再次运行代码,出现了爬取列表为空的问题,后面我查看了东方财富网的网页结构,发现结构已经变化。基于此,本文应运而生,主要解决爬取上证指数股吧评论问题,后续可能会对评论进行数据处理和情感分析。下面开始代码实战。
目录
(1)页面爬取
python
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import random
import pandas as pd
import os
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from mongodb import MongoAPI
from parser import PostParser
from parser import CommentParser
class PostCrawler(object):
def __init__(self, stock_symbol: str):
self.browser = None
self.symbol = stock_symbol
self.start = time.time()
def create_webdriver(self):
options = webdriver.ChromeOptions()
options.add_argument('lang=zh_CN.UTF-8')
options.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/111.0.0.0 Safari/537.36"')
self.browser = webdriver.Chrome(options=options)
current_dir = os.path.dirname(os.path.abspath(__file__))
js_file_path = os.path.join(current_dir, 'stealth.min.js')
with open(js_file_path) as f:
js = f.read()
self.browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
def get_page_num(self):
self.browser.get(f'http://guba.eastmoney.com/list,{self.symbol},f_1.html')
page_element = self.browser.find_element(By.CSS_SELECTOR, 'ul.paging > li:nth-child(7) > a > span')
return int(page_element.text)
def crawl_post_info(self, page1: int, page2: int):
self.create_webdriver()
max_page = self.get_page_num()
current_page = page1
stop_page = min(page2, max_page)
parser = PostParser()
postdb = MongoAPI('post_info', f'post_{self.symbol}')
while current_page <= stop_page:
time.sleep(abs(random.normalvariate(0, 0.1)))
url = f'http://guba.eastmoney.com/list,{self.symbol},f_{current_page}.html'
try:
self.browser.get(url)
dic_list = []
list_item = self.browser.find_elements(By.CSS_SELECTOR, '.listitem')
for li in list_item:
dic = parser.parse_post_info(li)
if 'guba.eastmoney.com' in dic['post_url']:
dic_list.append(dic)
postdb.insert_many(dic_list)
print(f'{self.symbol}: 已经成功爬取第 {current_page} 页帖子基本信息,'
f'进度 {(current_page - page1 + 1)*100/(stop_page - page1 + 1):.2f}%')
current_page += 1
except Exception as e:
print(f'{self.symbol}: 第 {current_page} 页出现了错误 {e}')
time.sleep(0.01)
self.browser.refresh()
self.browser.delete_all_cookies()
self.browser.quit()
self.create_webdriver()
end = time.time()
time_cost = end - self.start
start_date = postdb.find_last()['post_date']
end_date = postdb.find_first()['post_date']
row_count = postdb.count_documents()
self.browser.quit()
print(f'成功爬取 {self.symbol}股吧共 {stop_page - page1 + 1} 页帖子,总计 {row_count} 条,花费 {time_cost/60:.2f} 分钟')
print(f'帖子的时间范围从 {start_date} 到 {end_date}')
class CommentCrawler(object):
def __init__(self, stock_symbol: str):
self.browser = None
self.symbol = stock_symbol
self.start = time.time()
self.post_df = None
self.current_num = 0
def create_webdriver(self):
options = webdriver.ChromeOptions()
options.add_argument('lang=zh_CN.UTF-8')
options.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/111.0.0.0 Safari/537.36"')
self.browser = webdriver.Chrome(options=options)
current_dir = os.path.dirname(os.path.abspath(__file__))
js_file_path = os.path.join(current_dir, 'stealth.min.js')
with open(js_file_path) as f:
js = f.read()
self.browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": js
})
def find_by_date(self, start_date, end_date):
"""
:param start_date: '2003-07-21' 字符串格式 ≥
:param end_date: '2024-07-21' 字符串格式 ≤
"""
postdb = MongoAPI('post_info', f'post_{self.symbol}')
time_query = {
'post_date': {'$gte': start_date, '$lte': end_date},
'comment_num': {'$ne': 0}
}
post_info = postdb.find(time_query, {'_id': 1, 'post_url': 1}) # , 'post_date': 1
self.post_df = pd.DataFrame(post_info)
def find_by_id(self, start_id: int, end_id: int):
"""
:param start_id: 721 整数 ≥
:param end_id: 2003 整数 ≤
"""
postdb = MongoAPI('post_info', f'post_{self.symbol}')
id_query = {
'_id': {'$gte': start_id, '$lte': end_id},
'comment_num': {'$ne': 0}
}
post_info = postdb.find(id_query, {'_id': 1, 'post_url': 1})
self.post_df = pd.DataFrame(post_info)
def crawl_comment_info(self):
url_df = self.post_df['post_url']
id_df = self.post_df['_id']
total_num = self.post_df.shape[0]
self.create_webdriver()
parser = CommentParser()
commentdb = MongoAPI('comment_info', f'comment_{self.symbol}')
for url in url_df:
try:
time.sleep(abs(random.normalvariate(0.03, 0.01)))
try:
self.browser.get(url)
WebDriverWait(self.browser, 0.2, poll_frequency=0.1).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'div.reply_item.cl')))
except TimeoutException:
self.browser.refresh()
print('------------ refresh ------------')
finally:
reply_items = self.browser.find_elements(By.CSS_SELECTOR, 'div.allReplyList > div.replylist_content > div.reply_item.cl') # some have hot reply list avoid fetching twice
dic_list = []
for item in reply_items:
dic = parser.parse_comment_info(item, id_df.iloc[self.current_num].item())
dic_list.append(dic)
if parser.judge_sub_comment(item):
sub_reply_items = item.find_elements(By.CSS_SELECTOR, 'li.reply_item_l2')
for subitem in sub_reply_items:
dic = parser.parse_comment_info(subitem, id_df.iloc[self.current_num].item(), True)
dic_list.append(dic)
commentdb.insert_many(dic_list)
self.current_num += 1
print(f'{self.symbol}: 已成功爬取 {self.current_num} 页评论信息,进度 {self.current_num*100/total_num:.3f}%')
except TypeError as e:
self.current_num += 1
print(f'{self.symbol}: 第 {self.current_num} 页出现了错误 {e} ({url})') # maybe the invisible comments
print(f'应爬取的id范围是 {id_df.iloc[0]} 到 {id_df.iloc[-1]}, id {id_df.iloc[self.current_num - 1]} 出现了错误')
self.browser.delete_all_cookies()
self.browser.refresh()
self.browser.quit()
self.create_webdriver()
end = time.time()
time_cost = end - self.start
row_count = commentdb.count_documents()
self.browser.quit()
print(f'成功爬取 {self.symbol}股吧 {self.current_num} 页评论,共 {row_count} 条,花费 {time_cost/60:.2f}分钟')(2)解析评论信息
python
from selenium.webdriver.common.by import By
from selenium import webdriver
class PostParser(object):
def __init__(self):
self.year = None
self.month = 13
self.id = 0
@staticmethod
def parse_post_title(html):
title_element = html.find_element(By.CSS_SELECTOR, 'td:nth-child(3) > div')
return title_element.text
@staticmethod
def parse_post_view(html):
view_element = html.find_element(By.CSS_SELECTOR, 'td > div')
return view_element.text
@staticmethod
def parse_comment_num(html):
num_element = html.find_element(By.CSS_SELECTOR, 'td:nth-child(2) > div')
return int(num_element.text)
@staticmethod
def parse_post_url(html):
url_element = html.find_element(By.CSS_SELECTOR, 'td:nth-child(3) > div > a')
return url_element.get_attribute('href')
def get_post_year(self, html):
driver = webdriver.Chrome()
driver.get(self.parse_post_url(html))
date_str = driver.find_element(By.CSS_SELECTOR, 'div.newsauthor > div.author-info.cl > div.time').text
self.year = int(date_str[:4])
driver.quit()
@staticmethod
def judge_post_date(html):
try:
judge_element = html.find_element(By.CSS_SELECTOR, 'td:nth-child(3) > div > span')
if judge_element.text == '问董秘':
return False
except:
return True
def parse_post_date(self, html):
time_element = html.find_element(By.CSS_SELECTOR, 'div.update.pub_time')
time_str = time_element.text
month, day = map(int, time_str.split(' ')[0].split('-'))
if self.judge_post_date(html):
if self.month < month == 12:
self.year -= 1
self.month = month
if self.id == 1:
self.get_post_year(html)
date = f'{self.year}-{month:02d}-{day:02d}'
time = time_str.split(' ')[1]
return date, time
def parse_post_info(self, html):
self.id += 1
title = self.parse_post_title(html)
view = self.parse_post_view(html)
num = self.parse_comment_num(html)
url = self.parse_post_url(html)
date, time = self.parse_post_date(html)
post_info = {
'_id': self.id,
'post_title': title,
'post_view': view,
'comment_num': num,
'post_url': url,
'post_date': date,
'post_time': time,
}
return post_info
class CommentParser(object):
@staticmethod
def judge_sub_comment(html):
sub = html.find_elements(By.CSS_SELECTOR, 'ul.replyListL2') # must use '_elements' instead of '_element'
return bool(sub)
@staticmethod
def parse_comment_content(html, sub_bool):
if sub_bool:
content_element = html.find_element(By.CSS_SELECTOR, 'div.reply_title > span')
else:
content_element = html.find_element(By.CSS_SELECTOR, 'div.recont_right.fl > div.reply_title > span')
return content_element.text
@staticmethod
def parse_comment_like(html, sub_bool):
if sub_bool:
like_element = html.find_element(By.CSS_SELECTOR, 'span.likemodule')
else:
like_element = html.find_element(By.CSS_SELECTOR, 'ul.bottomright > li:nth-child(4) > span')
if like_element.text == '点赞': # website display text instead of '0'
return 0
else:
return int(like_element.text)
@staticmethod
def parse_comment_date(html, sub_bool):
if sub_bool: # situation to deal with sub-comments
date_element = html.find_element(By.CSS_SELECTOR, 'span.pubtime')
else:
date_element = html.find_element(By.CSS_SELECTOR, 'div.publishtime > span.pubtime')
date_str = date_element.text
date = date_str.split(' ')[0]
time = date_str.split(' ')[1][:5]
return date, time
def parse_comment_info(self, html, post_id, sub_bool: bool = False): # sub_pool is used to distinguish sub-comments
content = self.parse_comment_content(html, sub_bool)
like = self.parse_comment_like(html, sub_bool)
date, time = self.parse_comment_date(html, sub_bool)
whether_subcomment = int(sub_bool) # '1' means it is sub-comment, '0' means it is not
comment_info = {
'post_id': post_id,
'comment_content': content,
'comment_like': like,
'comment_date': date,
'comment_time': time,
'sub_comment': whether_subcomment,
}
return comment_info(3)保存数据
python
from pymongo import MongoClient
class MongoAPI(object):
def __init__(self, db_name: str, collection_name: str, host='localhost', port=27017):
self.host = host
self.port = port
self.db_name = db_name
self.collection = collection_name
self.client = MongoClient(host=self.host, port=self.port)
self.database = self.client[self.db_name]
self.collection = self.database[self.collection]
def insert_one(self, kv_dict):
self.collection.insert_one(kv_dict)
def insert_many(self, li_dict): # more efficient
self.collection.insert_many(li_dict)
def find_one(self, query1, query2):
return self.collection.find_one(query1, query2)
def find(self, query1, query2):
return self.collection.find(query1, query2)
def find_first(self):
return self.collection.find_one(sort=[('_id', 1)])
def find_last(self):
return self.collection.find_one(sort=[('_id', -1)])
def count_documents(self):
return self.collection.count_documents({})
def update_one(self, kv_dict):
self.collection.update_one(kv_dict, {'$set': kv_dict}, upsert=True)
def drop(self):
self.collection.drop()(4)主函数
python
from crawler import PostCrawler
from crawler import CommentCrawler
import threading
def post_thread(stock_symbol, start_page, end_page):
post_crawler = PostCrawler(stock_symbol)
post_crawler.crawl_post_info(start_page, end_page)
def comment_thread_date(stock_symbol, start_date, end_date):
comment_crawler.find_by_date(start_date, end_date)
comment_crawler.crawl_comment_info()
def comment_thread_id(stock_symbol, start_id, end_id):
comment_crawler = CommentCrawler(stock_symbol)
comment_crawler.find_by_id(start_id, end_id)
comment_crawler.crawl_comment_info()
if __name__ == "__main__":
thread1 = threading.Thread(target=post_thread, args=('zssh000001', 5835, 5875))
thread1.start()
thread1.join()
print(f"成功爬取评论数据!")输出结果展示:
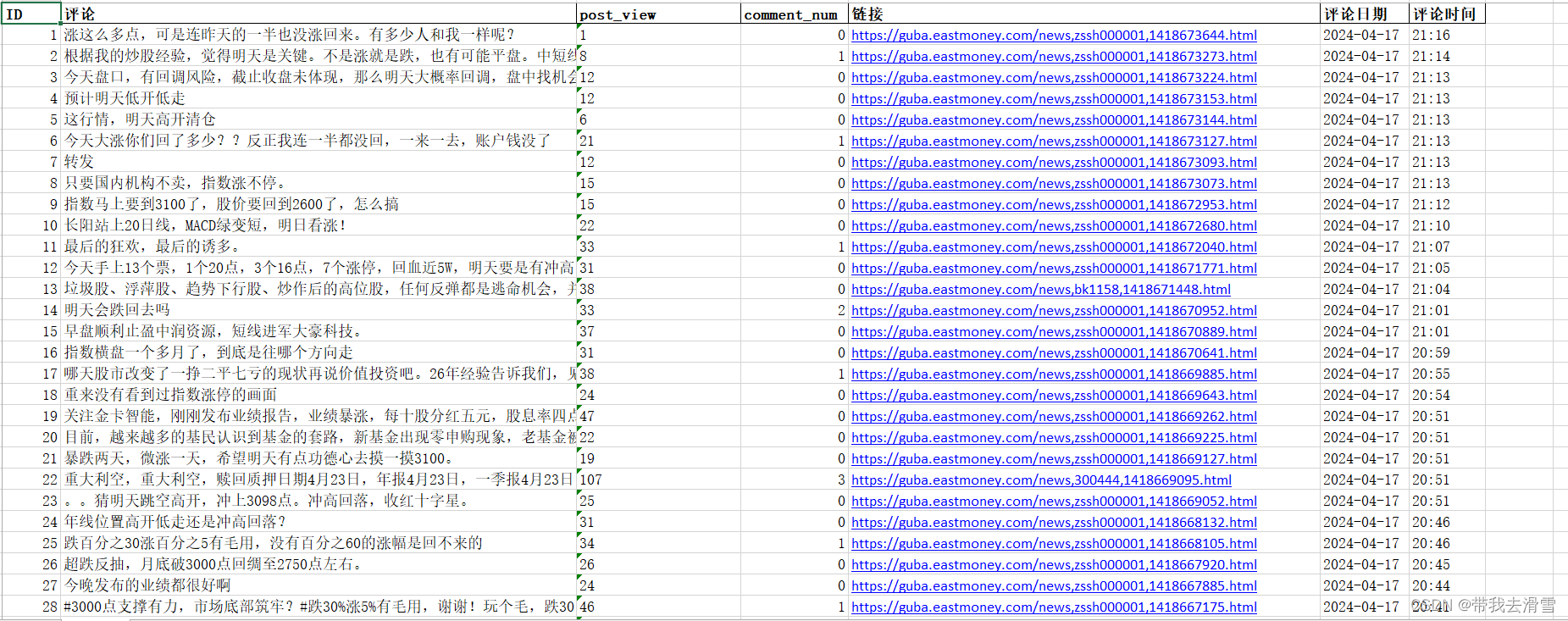
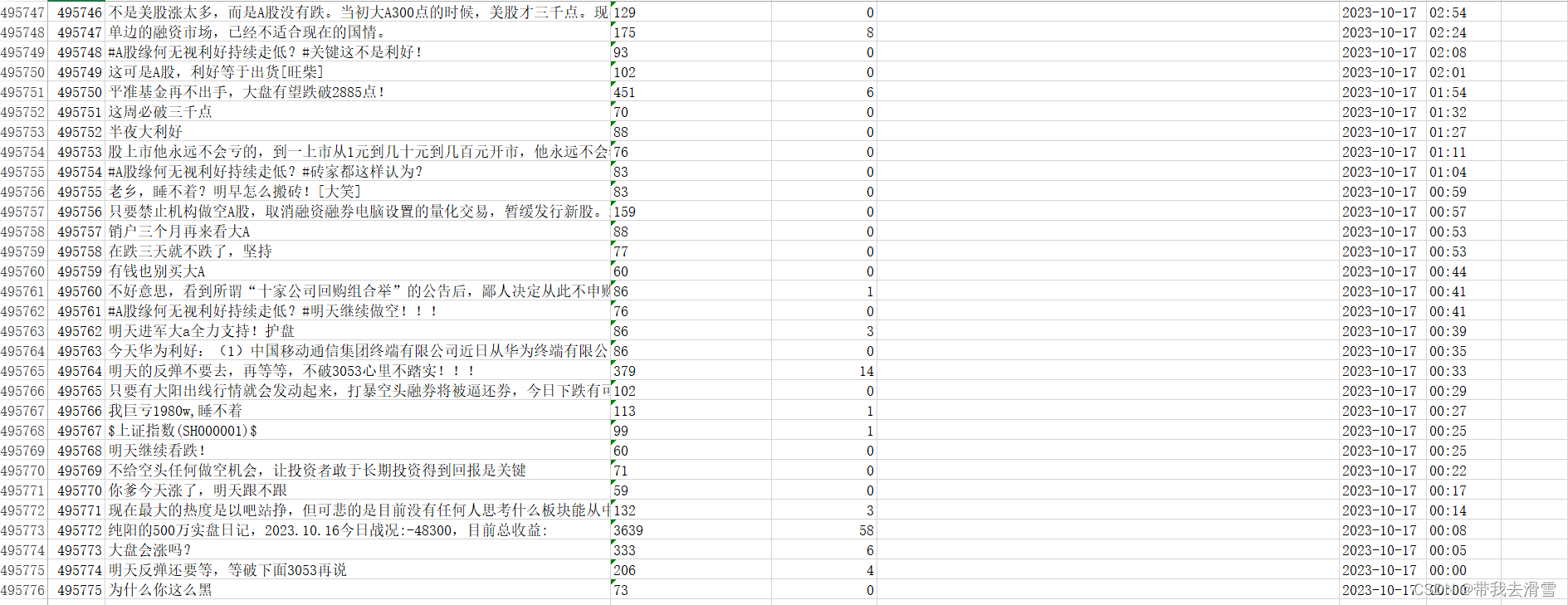
成功爬取了495775条评论数据,运行了14个小时,实属不易。后续将会对这个数据集,进行深度的分析。
需要数据集的家人们可以去百度网盘(永久有效)获取:
链接:https://pan.baidu.com/s/16Pp57kAbC3xAqPylyfQziA?pwd=2138
提取码:2138
更多优质内容持续发布中,请移步主页查看。
点赞+关注,下次不迷路!