每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

OpenAI推出基于GPT-4的新模型CriticGPT,用于捕捉ChatGPT代码输出中的错误。研究表明,当用户在CriticGPT的帮助下审查ChatGPT代码时,60%的情况下其表现优于没有帮助的用户。OpenAI正着手将类似CriticGPT的模型整合到RLHF(从人类反馈中强化学习)标签管道中,为训练师提供明确的AI辅助。这是迈向能够评估高级AI系统输出的一步,因为这些系统的输出难以仅依靠人类工具进行评估。
GPT-4系列模型通过RLHF使ChatGPT变得更加有用和互动。RLHF的重要部分是收集人类AI训练师对不同ChatGPT响应的比较和评分。然而,随着推理和模型行为的进步,ChatGPT变得更加准确,其错误也变得更加隐蔽。这使得AI训练师难以发现错误,从而使RLHF的比较任务更加困难。这是RLHF的一个基本限制,随着模型变得比任何提供反馈的人类更有知识,问题可能会变得越来越严重。

为了应对这一挑战,OpenAI训练了CriticGPT,使其能够撰写批评意见,突出ChatGPT回答中的不准确之处。虽然CriticGPT的建议并不总是正确的,但研究发现它能帮助训练师发现更多的问题。此外,当人们使用CriticGPT时,AI增强了他们的技能,导致批评意见比单独工作时更全面,同时比仅靠模型工作时产生更少的幻觉错误。在实验中,随机选择的第二名训练师更喜欢Human+CriticGPT团队的批评意见,而不是未受辅助的人的批评意见,超过60%的时间。
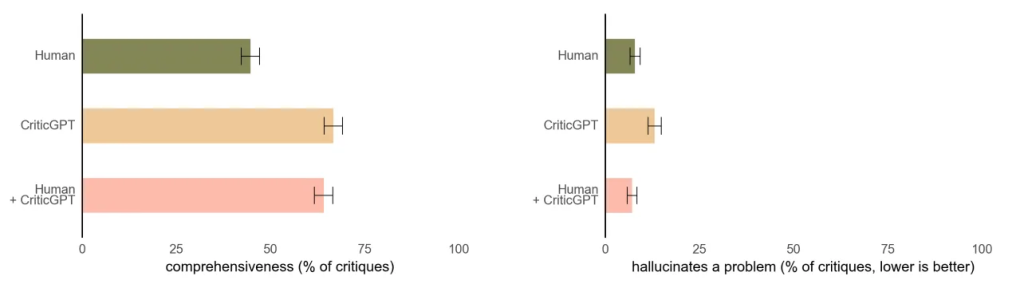
CriticGPT同样通过RLHF进行训练,但不同于ChatGPT,它接收了大量包含错误的输入,并需要对这些错误进行批评。OpenAI要求AI训练师手动将这些错误插入ChatGPT编写的代码中,然后撰写反馈示例,仿佛他们发现了自己插入的错误。同一人然后比较多种对修改后代码的批评意见,以便轻松判断哪个批评意见发现了他们插入的错误。研究表明,在63%的情况下,训练师更喜欢CriticGPT的批评意见,因为新模型产生的"小问题"(不太有帮助的抱怨)更少,并且更少出现幻觉问题。
研究还发现,通过针对批评奖励模型的额外测试时间搜索,可以生成更长且更全面的批评意见。这种搜索程序使得我们能够平衡对代码问题的积极寻找程度,并在幻觉和检测到的错误数量之间配置精确度和召回率的权衡。这样就可以生成对RLHF尽可能有帮助的批评意见。
尽管取得了这些进展,CriticGPT仍有一些局限性。它主要训练于较短的ChatGPT回答,对于监督未来的代理,需要开发能够帮助训练师理解长篇复杂任务的方法。此外,模型仍会产生幻觉,训练师在看到这些幻觉后有时也会犯标签错误。有时,现实世界的错误可能分散在答案的多个部分,而当前的工作主要关注能够在一个地方指出的错误,未来需要处理分散的错误。
为了对齐越来越复杂的AI系统,需要更好的工具。研究表明,将RLHF应用于GPT-4有望帮助人类生成更好的RLHF数据。OpenAI计划进一步扩展这项工作并付诸实践。