「kafka设计思想」
一个最基本的架构是生产者发布一个消息到Kafka的一个Topic ,该Topic的消息存放于的Broker中,消费者订阅这个Topic,然后从Broker中消费消息,下面这个图可以更直观的描述这个场景:
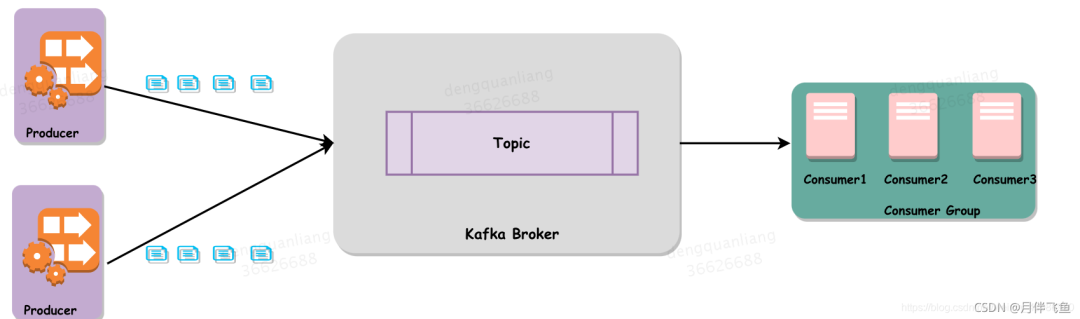
**「消息状态:」**在Kafka中,消息是否被消费的状态保存在Consumer中,Broker不会关心消息是否被消费或被谁消费,Consumer会记录一个offset值(指向partition中下一条将要被消费的消息位置),如果offset被错误设置可能导致同一条消息被多次消费或者消息丢失。
**「消息持久化:」**Kafka会把消息持久化到本地文件系统中,并且具有极高的性能。
**「批量发送:」**Kafka支持以消息集合为单位进行批量发送,以提高效率。
**「Push-and-Pull:」**Kafka中的Producer和Consumer采用的是Push-and-Pull模式,即Producer向Broker Push消息,Consumer从Broker Pull消息。
**「分区机制(Partition):」**Kafka的Broker端支持消息分区,Producer可以决定把消息发到哪个Partition,在一个Partition中消息的顺序就是Producer发送消息的顺序,一个Topic中的Partition数是可配置的,Partition是Kafka高吞吐量的重要保证。
「系统架构」
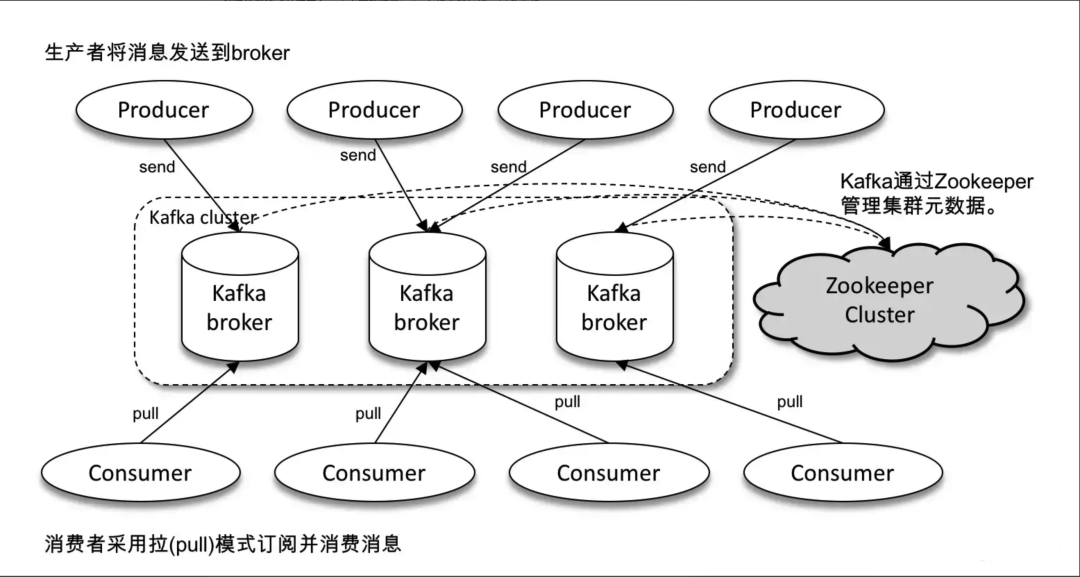
通常情况下,一个kafka体系架构包括**「多个Producer」、 「多个Consumer」、 「多个broker」以及「一个Zookeeper集群」**。
「Producer」:生产者,负责将消息发送到kafka中。
「Consumer」:消费者,负责从kafka中拉取消息进行消费。
「Broker」:Kafka服务节点,一个或多个Broker组成了一个Kafka集群
「Zookeeper集群」:负责管理kafka集群元数据以及控制器选举等。