1-爬虫基础知识(6节课学会爬虫)
1.什么是爬虫
爬虫:通俗的说爬虫就是通过一定的规则策略,自动抓取、下载互联网上网页,在按照某些规则算法对这些网页进行数据抽取、 索引。 像百度、谷歌、今日头条、包括各类新闻站都是通过爬虫来抓取数据。
2.爬取的数据去哪了
呈现:展示在网页上,或者是展示在app上
分析:从数据中寻找一些规律
搜索:微博等是有用户进行内容发布,数据发布的
预测:数据可以进行后续的预测
3.需要的软件和环境
Python3:
(1)基础语法,要有(字符串、列表、字典、判断和循环)
(2)函数(函数的创建和调用)
(3)面向对象(如何创建一个类,如何使用一个类即可)
Pycharm:Python编辑器,Python的官网可以下载
Chrome浏览器:分析网络请求用的,在network有url地址
4.浏览器的请求
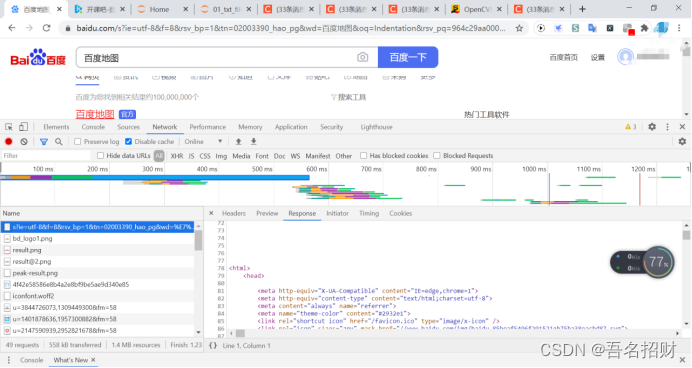
(1)Url
在Chrome中右击检查,点到network
Url-请求的协议+网站的域名+资源路径+参数
后续一旦看到url中出现百分号,进行url解码(在百度搜索在线解码),可以看到文字内容
在Chrome中会出现很多的url地址,有很多额外的url地址的请求,如css和图片等地址
Elements中的内容就是网页的所有内容
(2)浏览器请求url地址
当前url对应的响应+js+css+图片 ---》elements中的内容
爬虫请求url对应的响应
Elements的内容和爬虫获取到的url地址的响应不同,需要爬虫以当前url地址对应的响应为准提取数据。而不能以elements为准,elements中的内容不准
在network中的response中可以看到准确的内容-当前的url响应
(3)url地址对应的响应
从network中找到当前的url地址,点击response
在网页右键显示源码,也可以当前url响应
爬虫得到的url响应是不会主动加载js+css等图片的,要以当前url响应为准
有些贴吧会刷新页面,重新显示网页源码,会导致下次内容和之前内容不同,但框架相同,只是填入的数据不同
很多请求是,如数据变化
爬虫模拟请求,可以给人投票
5.认识HTTP/HTTPS
http:超文本传输协议,以明文的形式传输,效率更高,但是不安全
https:HTTP+SSL(安全套接字层), 传输之前先加密,之后解密获取内容,效率较低,但是安全
5.1 http协议之请求
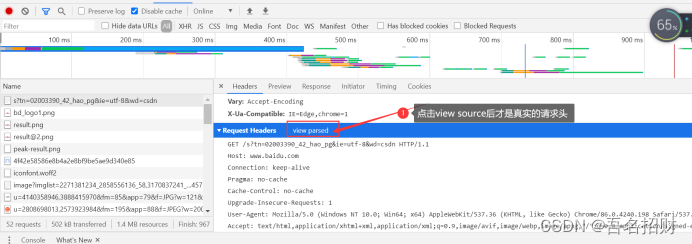
(1)请求行
协议 url地址,请求协议名及版本号
(2)请求头
host:域名
connection:支持转换成长链接
cache-control:缓存控制
user-agent:(重要)用户代理(身份标识),对方服务器能通过user-agent判断
我们可以在Chrome浏览器模拟手机版发送请求,对应需要将user-agent改成手机版浏览器
Upgrade-insecure-requests:将不安全的http请求转换成https请求
Accept-encoding:接收什么类型的数据
Accept-language:接收什么语言的数据
Cookie:(重要),用来存储用户信息,最终每次请求会被携带上发送给对方服务器
要获取登录后才能访问的页面,对方的服务器会通过cookie判断我们是一个爬虫,为什么对方服务器知道你登录了,下次打开访问网站,要请求
(3)请求体
携带数据
Get请求没有请求体(参数放在url中)
Post请求有请求体(数据放在请求体中,常用于登录注册,传输大文本(携带的数据量很大))
5.2 HTTP协议之响应
(1)响应头
Set-cookie:对方服务器通过该字段可以设置cookie到本地
(2)响应体
Url地址对应的响应
Cookie中重点关注name和value字段,
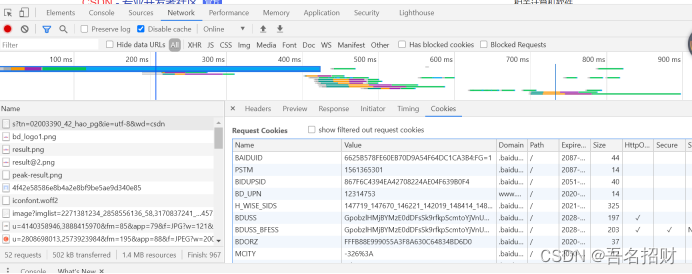
后面写爬虫的时候,要用到的基本讲完
在network中重新请求地址就有请求了,这就是抓包(看浏览器发了多少请求)
当我们只用user-agent一个字段无法获取数据时,要考虑是否将其他的字段都带上,一般user-agent和cookie就够了,或者refer等