司法阅读理解
1 任务目标
1.1 任务说明
裁判文书中包含了丰富的案件信息,比如时间、地点、人物关系等等,通过机器智能化地阅读理解裁判文书,可以更快速、便捷地辅助法官、律师以及普通大众获取所需信息。
本次任务覆盖多种法律文书类型,包括民事、刑事、行政,问题类型为多步推理,即对于给定问题,只通过单句文本很难得出正确回答,模型需要结合多句话通过推理得出答案。
1.2 评分要求
分数由两部分组成。首先,读懂已有代码并添加适量注释。使用已有代码在训练数据上进行训练,并且完成开发集评测,这部分占60%,评分依据为模型的开发集性能和报告,报告主要包括对于模型基本原理的介绍,需要同学阅读代码进行学习。
第二部分,进行进一步的探索和尝试,我们将在下一小节介绍可能的尝试,并在报告中汇报尝试的方法以及结果,这部分占40%。同学需要提交代码和报告,在报告中对于两部分的实验都进行介绍。
1.3 探索和尝试
- 使用2019年的阅读理解数据集(CJRC)作为辅助数据集,帮助模型提高阅读理解能力
- 使用别的预训练语言模型完成该实验,例如THUNLP提供的司法BERT
- 对于新的模型架构进行探索,例如加入图神经网络(GNN)来加强模型的推理能力
1.4 参考资料
NLP_Novice/5.司法阅读理解(CAIL 2020) (github.com)(https://github.com/yingcongshaw/NLP_Novice/tree/529278f3afb89947b4e657973618fb73c5ec2d45/5.司法阅读理解(CAIL 2020))
2 数据集
2.1 数据说明
本任务数据集包括约5100个问答对,其中民事、刑事、行政各约1700个问答对,均为需要多步推理的问题类型。为了进行评测,按照9:1的划分,数据集分为了训练集和测试集。注意 该数据仅用于本课程的学习,请勿进行传播。
发放的文件为train.json和dev.json,为字典列表,字典包含字段为:
_id:案例的唯一标识符。context:案例内容,抽取自裁判文书的事实描述部分。数据格式与HotpotQA数据格式一致,不过只包含一个篇章,篇章包括标题(第一句话)和切割后的句子列表。question:针对案例提出的问题,每个案例只标注一个问题。answer:问题的回答,包括片段、YES/NO、据答几种类型,对于拒答类,答案应该是"unknown"。supporting_facts:回答问题的依据,是个列表,每个元素包括标题(第一句话)和句子编号(从0开始)。
同学们需根据案例描述和问题,给出答案及答案依据,最终会综合两部分的效果并作为评判依据,评价方法与HotpotQA一致。
我们提供基础的模型代码在baseline目录下
2.2 数据处理代码
本案例通过 data_process.py 对数据进行处理,该代码主要功能是读取问答数据文件,解析并转换数据为适合BERT模型输入的格式,并保存处理后的数据。通过定义Example和InputFeatures类,代码能够有效地组织和处理问答样本的数据。下面对该代码进行解释。
-
导入必要的库:
argparse:用于解析命令行参数。json:用于解析JSON格式的数据。gzip和pickle:用于数据的压缩和序列化。tqdm:用于显示处理进度。BertTokenizer:来自transformers库,用于文本的分词处理。os:用于操作文件和目录。
-
定义数据模型类:
-
Example:用于存储单个问答样本的原始数据,包括问题ID、类型、文档标记、问题文本等信息。pyclass Example(object): def __init__(self, qas_id, qas_type, doc_tokens, question_text, sent_num, sent_names, sup_fact_id, para_start_end_position, sent_start_end_position, entity_start_end_position, orig_answer_text=None, start_position=None, end_position=None): # 初始化问答样本的数据 -
InputFeatures:用于存储转换后的特征数据,这些特征将用于模型的输入,包括经过分词处理的文档和问题、输入ID、掩码和段落ID等。pyclass InputFeatures(object): def __init__(self, qas_id, doc_tokens, doc_input_ids, doc_input_mask, doc_segment_ids, query_tokens, query_input_ids, query_input_mask, query_segment_ids, sent_spans, sup_fact_ids, ans_type, token_to_orig_map, start_position=None, end_position=None): # 初始化转换后的特征数据
-
-
数据读取函数 (
read_examples):pydef read_examples(full_file): # 打开并读取输入文件(JSON 格式) with open(full_file, 'r', encoding='utf-8') as reader: full_data = json.load(reader) ... return examples # 返回所有样本列表- 读取JSON格式的HotpotQA数据文件。
- 处理每个问题案例,包括分词、标注支持事实、确定答案位置等。
- 创建
Example对象的列表。
-
特征转换函数 (
convert_examples_to_features):pydef convert_examples_to_features(examples, tokenizer, max_seq_length, max_query_length): # max_query_length = 50 features = [] for (example_index, example) in enumerate(tqdm(examples)): ... features.append(InputFeatures(...)) return features # 返回所有转换后的特征- 将
Example对象转换为InputFeatures对象,包括使用Bert分词器处理文档和问题文本。 - 处理答案文本,将字符位置转换为分词后的标记位置。
- 创建句子跨度、支持事实ID等特征。
- 对特征数据进行填充,以满足模型输入的序列长度要求。
- 将
-
辅助函数:
check_in_full_paras:检查答案是否在段落中。_largest_valid_index:获取有效的最大索引。get_valid_spans:获取有效的跨度列表。_improve_answer_span:改进答案的标记跨度,以更好地匹配注释答案。
-
主函数 (
if __name__ == '__main__':):- 解析命令行参数,包括输出文件路径、是否进行小写处理、序列最大长度等。
- 加载Bert分词器。
- 读取并处理数据,将原始数据转换为模型输入所需的特征数据。
- 序列化特征数据并保存到文件。
2.3 数据处理
-
下载Bert
首先需要下载合适的分词器模型,如
chinese_bert_wwm,下载链接。 -
训练数据预处理
执行以下命令,运行
data_process.py对训练数据进行数据处理,得到train_example.pkl.gz与train_feature.pkl.gz。-
--example_output将原始数据处理为示例数据,存储在Example对象中。 -
--feature_output将示例数据转换为模型可以直接使用的特征数据,存储在InputFeatures对象中。!python baseline/data_process.py
--tokenizer_path ./models/chinese_bert_wwm
--full_data ./data/train.json
--example_output ./output/data/chinese-bert-wwm/train_example.pkl.gz
--feature_output ./output/data/chinese-bert-wwm/train_feature.pkl.gz
-
-
测试数据预处理
执行以下命令,运行
data_process.py对测试数据进行数据处理,得到dev_example.pkl.gz与dev_feature.pkl.gz。!python baseline/data_process.py \ --tokenizer_path ./models/chinese_bert_wwm \ --full_data ./data/dev.json \ --example_output ./output/data/chinese-bert-wwm/dev_example.pkl.gz \ --feature_output ./output/data/chinese-bert-wwm/dev_feature.pkl.gz
3 模型训练
3.1 中文预训练的模型
本实验需要通过自己寻找一个比较好的中文预训练模型用于训练数据,通过寻找找到了以下中文预训练模型。
-
Chinese-BERT-wwm
Chinese-BERT-wwm (Whole Word Masking BERT for Chinese) 是一种基于 BERT 的中文预训练模型,专门针对中文文本进行了优化,仓库为 ymcui/Chinese-BERT-wwm: Pre-Training with Whole Word Masking for Chinese BERT(中文BERT-wwm系列模型) (github.com)。该模型的主要特点是采用了全词掩码策略,即在训练过程中掩码的是整个词而不是单个汉字。这种策略有助于模型更好地理解词汇级别的信息,而不仅仅是字符级别的信息。
模型特点:
- Whole Word Masking:在训练时,将整个词作为一个单元进行掩码,提高模型对词汇的理解能力。
- 适用领域:适用于各种中文自然语言处理任务,如文本分类、问答系统、文本生成等。
- 使用场景:适合需要精确理解中文词汇语义的任务。
-
Chinese-RoBERTa-wwm-ext
Chinese-RoBERTa-wwm-ext 是在
Chinese-BERT-wwm基础上进一步优化的模型。RoBERTa(Robustly optimized BERT approach) 是 BERT 的改进版,仓库为 ymcui/Chinese-BERT-wwm: Pre-Training with Whole Word Masking for Chinese BERT(中文BERT-wwm系列模型) (github.com)。该模型通过更大的数据集和更长时间的训练,提高了模型的性能。Chinese-RoBERTa-wwm-ext继承了这些改进,并结合了全词掩码策略。模型特点:
- Robustly Optimized:优化了训练过程和超参数,增强了模型的鲁棒性和性能。
- Whole Word Masking:继续采用全词掩码策略,提高中文词汇理解。
- Extended Dataset:使用了更大规模的数据集进行训练,提高了模型的泛化能力。
- 使用场景:适合更高精度要求的中文自然语言处理任务。
-
thunlp_ms
thunlp_ms 是由清华大学自然语言处理与社会人文计算实验室 (THUNLP) 提供的一个民事文书BERT预训练模型。数据来源为全部民事文书,训练数据大小有2654万篇文书,词表大小22554,模型大小370MB。仓库为thunlp/OpenCLaP: Open Chinese Language Pre-trained Model Zoo (github.com),下载链接 https://thunlp.oss-cn-qingdao.aliyuncs.com/bert/ms.zip 。
-
thunlp_xs
thunlp_xs 是由清华大学自然语言处理与社会人文计算实验室 (THUNLP) 提供的一个刑事文书BERT预训练模型。数据来源为全部刑事文书,训练数据大小有663万篇文书,词表大小22554,模型大小370MB。仓库为thunlp/OpenCLaP: Open Chinese Language Pre-trained Model Zoo (github.com),下载链接 https://thunlp.oss-cn-qingdao.aliyuncs.com/bert/xs.zip 。
3.2 模型训练代码
本案例通过 run_cail.py 训练和评估基于BERT模型的问答系统。以下是对代码中关键功能的详细介绍:
-
导入必要的库和模块
-
argparse用于解析命令行参数。 -
os.path.join用于路径拼接。 -
tqdm用于显示进度条。 -
transformers.BertModel和transformers.BertConfig用于加载和配置BERT模型。 -
transformers.optimization.AdamW和transformers.optimization.get_linear_schedule_with_warmup用于优化和学习率调度。 -
torch和torch.nn为PyTorch库,用于构建和训练神经网络。
-
-
全局配置和辅助函数
set_seed函数设置随机种子,确保实验可复现。
-
数据处理和分发函数
dispatch函数将数据分发到GPU。
-
损失计算函数
compute_loss函数计算模型的损失值,包括起始位置、结束位置、类型预测和支持段落的损失。
-
预测函数
predict函数在模型评估阶段运行,使用模型对数据进行预测,并生成预测结果的字典。
-
训练函数
-
train_epoch函数执行一个训练周期,调用train_batch函数处理每个批次的数据。 -
train_batch函数处理单个批次的数据,执行前向传播、损失计算、反向传播和优化器步骤。
-
-
主函数
在
if __name__ == "__main__":块中,脚本执行以下操作:-
解析命令行参数。
-
设置GPU数量和随机种子。
-
初始化数据加载器和数据集。
-
加载或配置BERT模型。
-
初始化优化器、学习率调度器和损失函数。
-
执行训练循环,包括训练和评估阶段。
-
-
训练和评估循环
-
训练循环包括多次迭代(由
args.epochs指定),每个迭代都会遍历训练数据集。 -
在训练过程中,如果设置了
predict_during_train,则在每个epoch的指定步骤进行评估。 -
训练结束后,保存模型的状态字典,并记录训练和评估的损失。
-
-
混合精度训练
- 如果
args.fp16为真,则使用Apex库的自动混合精度(AMP)功能来加速训练并减少内存使用。
- 如果
-
数据并行
- 使用
torch.nn.DataParallel实现模型的数据并行,可以在多个GPU上同时训练模型。
- 使用
-
日志记录
- 训练过程中,通过打印语句记录损失和其他统计信息。
-
结束训练
- 当达到最大epoch数或满足其他退出条件时,脚本将停止训练。
3.3 模型训练
-
训练指令
输入以下命令进行模型训练,本实验分别对以上4个中文预训练模型进行训练。
py!python baseline/run_cail.py \ --name chinese-bert-wwm \ --bert_model ./models/chinese_bert_wwm \ --data_dir ./output/data/chinese-bert-wwm \ --batch_size 2 \ --eval_batch_size 32 \ --lr 1e-5 \ --gradient_accumulation_steps 4 \ --seed 56 \ --epochs 25 其中参数含义如下:
--name chinese-bert-wwm:--name指定了运行此次实验的名称或标识,这里设置为chinese-bert-wwm。--bert_model ./models/chinese_bert_wwm: 指定BERT模型的路径。--data_dir ./output/data/chinese-bert-wwm: 指定存放数据的目录,数据可能包括预处理后的训练集、验证集等。--batch_size 2: 设置训练时每个batch的大小为2。--eval_batch_size 32: 设置评估时每个batch的大小为32。--lr 1e-5: 设置学习率为1e-5,即0.00001。--gradient_accumulation_steps 4: 设置梯度累积的步数为4,这意味着每4个batch执行一次优化器更新。--seed 56: 设置随机种子为56,以确保结果的可复现性。--epochs 25: 设置训练的总周期数为25。
-
训练结果
训练结束后,得到了每个epoch的
.pth的checkpoints文件与.json的submissions文件,用于后续模型测试。
4 模型测试
4.1 模型测试指标
在自然语言处理(NLP)和信息检索领域,EM、F1、Prec和Recall是几个关键的性能评估指标,它们用于衡量模型预测结果的质量。以下是每个指标的详细介绍:
-
Exact Match (EM) - 精确匹配:
- 精确匹配是衡量预测答案是否与真实答案完全一致的指标。如果两个答案的文本完全相同,那么它们被认为是精确匹配的。
- 例如,如果真实答案是 "New York",预测答案也是 "New York",则EM为1(或100%);如果预测答案是 "New york" 或 "纽约",则EM为0,因为它们与真实答案不完全相同。
-
F1 Score (F1) - F1 分数:
- F1分数是精确度(Precision)和召回率(Recall)的调和平均数,用于衡量模型的准确性和完整性的平衡。F1分数的范围是0到1,1表示完美的预测,0表示最差的预测。
- 公式为:
F 1 = 2 × ( Precision × Recall Precision + Recall ) F1 = 2 \times \left(\frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}}\right) F1=2×(Precision+RecallPrecision×Recall) - F1分数特别适用于处理不平衡的数据集,其中某些类别的样本可能比其他类别多得多。
-
Precision (Prec) - 精确度:
- 精确度是指预测为正类别中实际为正类别的比例。换句话说,它衡量了所有被模型预测为正确答案中,实际上也是正确答案的比例。
- 公式为:
Precision = T P T P + F P \text{Precision} = \frac{TP}{TP + FP} Precision=TP+FPTP - 其中TP(真正例)是正确预测为正的样本数量,FP(假正例)是错误预测为正的样本数量。
-
Recall (Recall) - 召回率:
- 召回率也称为真正率或灵敏度,它衡量了所有实际正类别中被模型正确预测为正类别的比例。
- 公式为:
Recall = T P T P + F N \text{Recall} = \frac{TP}{TP + FN} Recall=TP+FNTP - 其中FN(假负例)是被错误预测为负的正样本数量。
-
SP (Supporting Facts) 结果:
- 支持事实是指那些直接支撑或解释答案的文本段落或句子。在多跳问答(multi-hop QA)中,答案通常需要依据文档中的多个不同部分进行推理得出,这些不同的部分即为支持事实。
- 在评估脚本中,
update_sp函数用于计算模型预测的支持事实与真实支持事实之间的匹配程度,包括精确度(Precision)、召回率(Recall)和F1分数。
-
Joint 结果:
- Joint评估考虑了答案的准确性以及支持事实的准确性。在这种评估方式中,只有当模型同时正确预测了答案以及所有相关的支持事实时,才认为该问题是完全正确的。
- 例如,在
eval函数中,计算联合精确度(joint EM)时,仅当答案的精确匹配(EM)和支持事实的精确匹配(sp_EM)同时为真时,联合精确度才计为1,这反映了模型在整体任务上的表现。
4.2 模型测试代码
本案例没有提供模型测试代码,通过 CAIL2020------阅读理解 得到测试代码 evaluate.py 。evalutae.py 是一个用于评估问答系统性能的Python脚本,主要用于计算精确匹配(Exact Match, EM)、F1分数以及其他相关指标。以下是对脚本中关键功能的详细介绍:
-
导入模块
-
sys: 用于访问与Python解释器密切相关的变量和函数。 -
ujson: 一个用于解析和生成JSON的库,比标准的json库更快。 -
re: 正则表达式库,用于文本匹配。 -
string: 包含字符串常量和字符串相关的函数。 -
collections.Counter: 用于计数的容器,方便统计元素出现次数。 -
pickle: 用于序列化和反序列化Python对象。
-
-
答案标准化函数
normalize_answer(s): 将答案文本进行标准化处理,包括去除文章(a, an, the)、替换空白字符、去除标点符号和转换为小写。
-
评估函数
-
f1_score(prediction, ground_truth): 计算预测答案和真实答案之间的F1分数,包括精确度(Precision)、召回率(Recall)和F1分数本身。 -
exact_match_score(prediction, ground_truth): 计算预测答案和真实答案是否完全匹配。 -
update_answer(metrics, prediction, gold): 更新答案评估指标,包括精确匹配、F1分数、精确度和召回率。
-
-
支持事实评估函数
update_sp(metrics, prediction, gold): 更新支持事实(Supporting Facts, SP)的评估指标,包括精确匹配、F1分数、精确度和召回率。
-
主评估函数
eval(prediction_file, gold_file): 读取预测结果文件和真实结果文件,然后对每个问题的答案和支持事实进行评估,计算整体的评估指标。
-
联合评估
- 脚本还计算了答案和支持事实的联合评估指标,即在答案精确匹配的情况下,支持事实也精确匹配的情况。
-
主函数
if __name__ == '__main__':块是脚本的入口点,它使用命令行参数指定的预测结果文件和真实结果文件进行评估,并打印出评估结果。
4.3 模型测试
输入以下指令进行模型测试,得到每个epoch的测试结果。
for i in range(1,26):
!python baseline/evaluate.py ./output/submissions/chinese-bert-wwm/pred_seed_56_epoch_{i}_99999.json ./data/dev.json 测试结果如下:
{'em': 0.125, 'f1': 0.19567546419134832, 'prec': 0.2086390213622355, 'recall': 0.19941998427586816, 'sp_em': 0.15079365079365079, 'sp_f1': 0.25401549508692367, 'sp_prec': 0.3197751322751322, 'sp_recall': 0.22890211640211638, 'joint_em': 0.001984126984126984, 'joint_f1': 0.03492904180069224, 'joint_prec': 0.05480599647266315, 'joint_recall': 0.028516452877447276}
{'em': 0.45634920634920634, 'f1': 0.5561908302303119, 'prec': 0.5700169126508411, 'recall': 0.5635363963342302, 'sp_em': 0.15674603174603174, 'sp_f1': 0.43485764676240873, 'sp_prec': 0.5851851851851851, 'sp_recall': 0.3772156084656083, 'joint_em': 0.05952380952380952, 'joint_f1': 0.25640473686157556, 'joint_prec': 0.3713905252595728, 'joint_recall': 0.2208404364186486}
{'em': 0.49404761904761907, 'f1': 0.580694477531037, 'prec': 0.5979415040426944, 'recall': 0.5836045772516851, 'sp_em': 0.23015873015873015, 'sp_f1': 0.589451630820679, 'sp_prec': 0.6803791887125223, 'sp_recall': 0.5631283068783066, 'joint_em': 0.12103174603174603, 'joint_f1': 0.3814845473719221, 'joint_prec': 0.4563021126066761, 'joint_recall': 0.36503795669254235}
... 分别对4个中文预训练模型进行测试,结果如下。
-
chinese-bert-wwm
-
基础结果
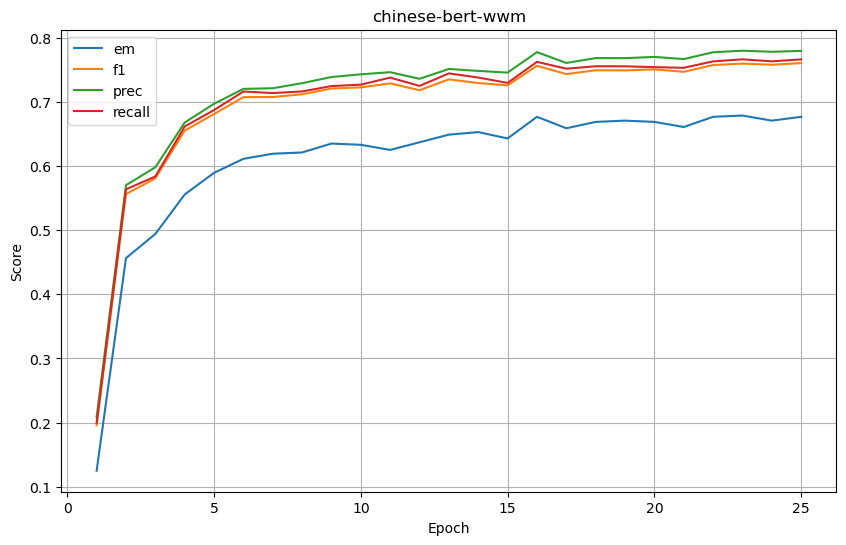
-
SP (Supporting Facts) 结果
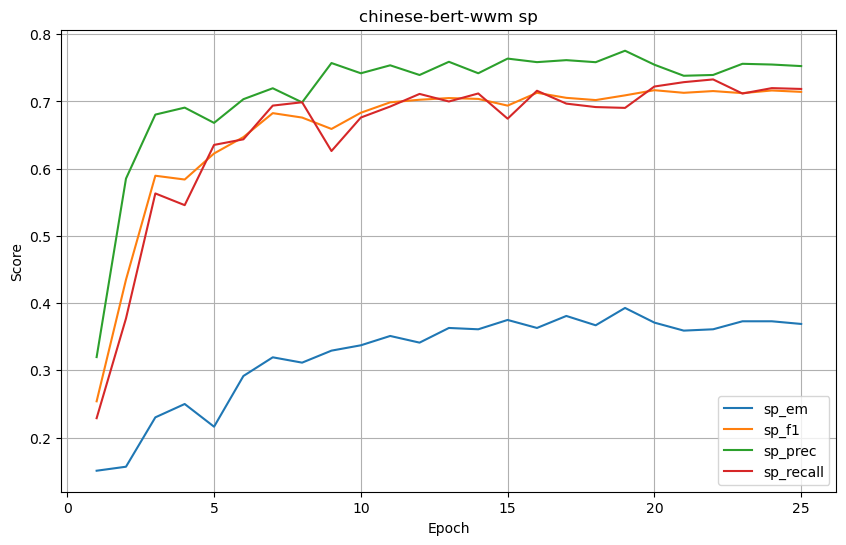
-
joint 结果
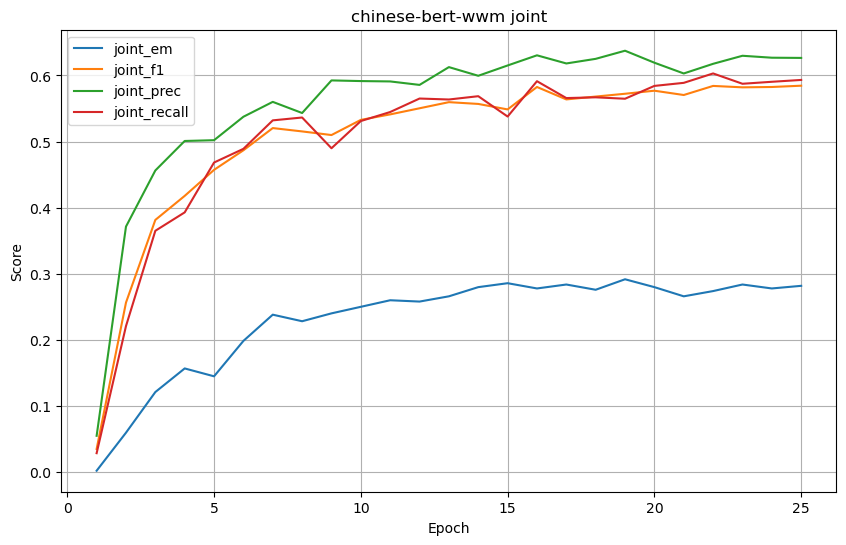
-
-
chinese_roberta_wwm_ext
-
基础结果
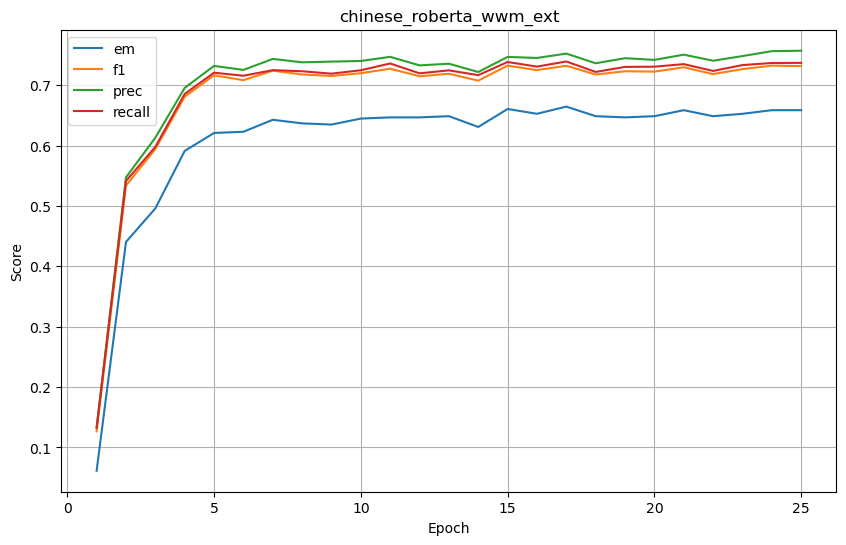
-
SP (Supporting Facts) 结果
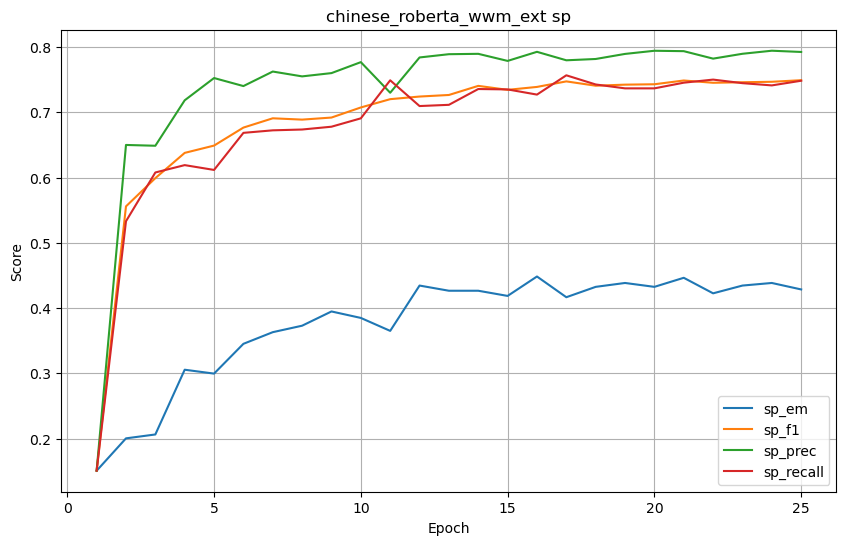
-
joint 结果
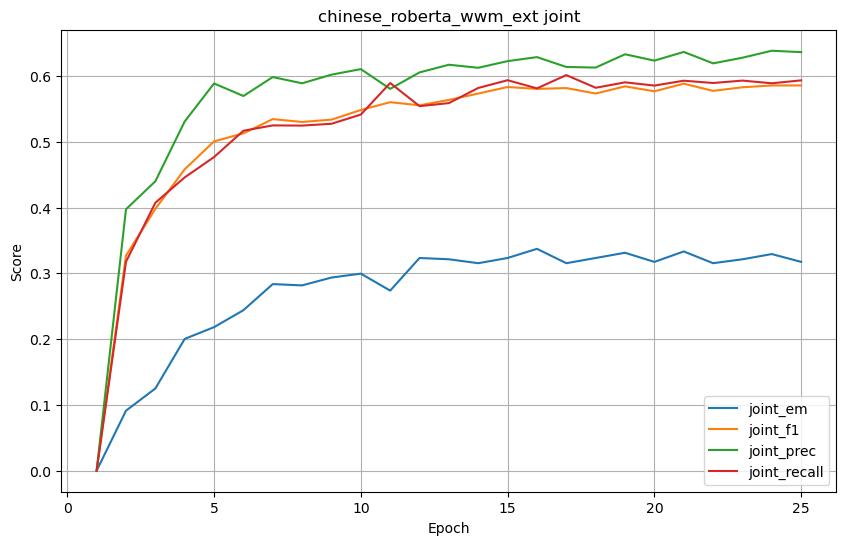
-
-
thunlp_ms
-
基础结果
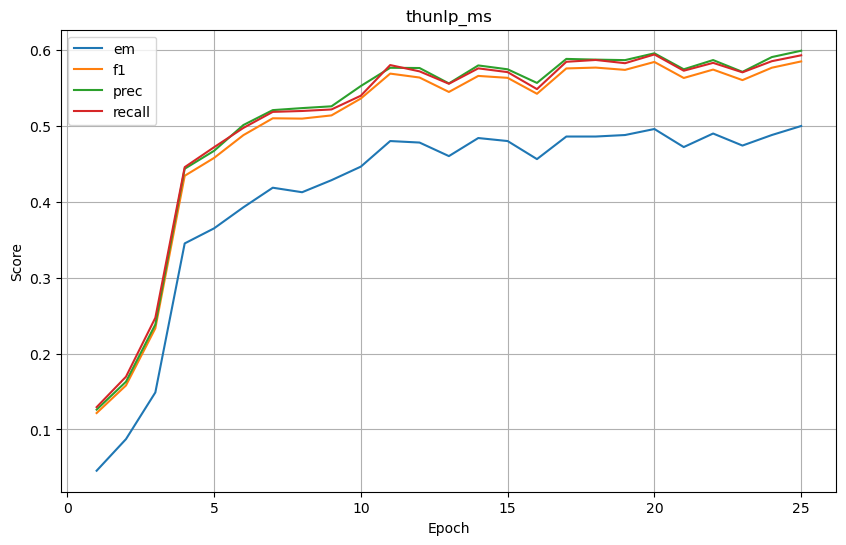
-
SP (Supporting Facts) 结果

-
joint 结果

-
-
thunlp_xs
-
基础结果
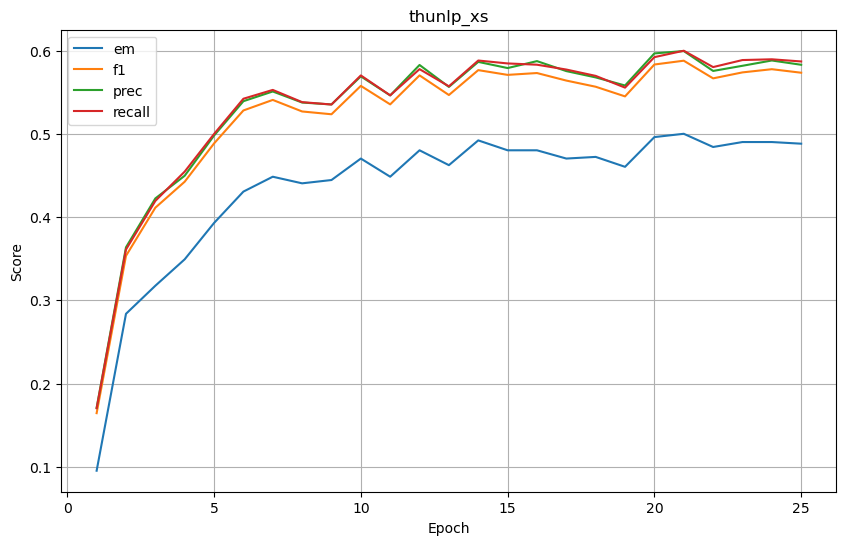
-
SP (Supporting Facts) 结果
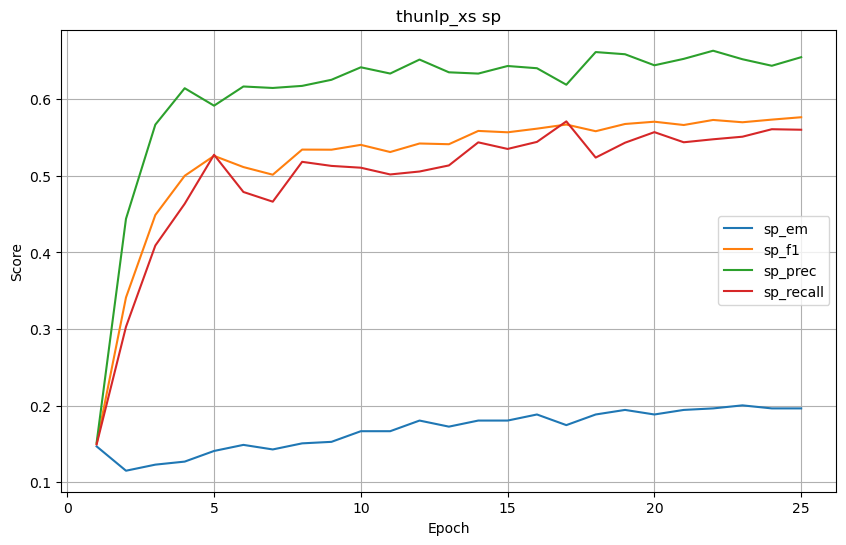
-
joint 结果
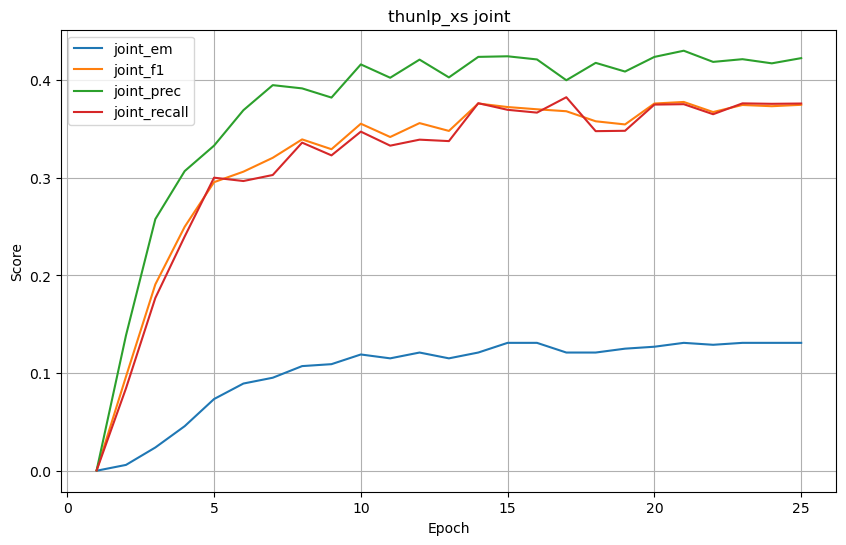
-
将 4 个预训练模型训练25轮后的结果列成表格,结果如下。
| 模型/指标 | em | f1 | prec | recall | sp_em | sp_f1 | sp_prec | sp_recall | joint_em | joint_f1 | joint_prec | joint_recall |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| chinese-bert-wwm | 0.676587 | 0.760272 | 0.779338 | 0.766072 | 0.369048 | 0.714164 | 0.752504 | 0.718518 | 0.281746 | 0.584557 | 0.626606 | 0.593274 |
| chinese_roberta_wwm_ext | 0.658730 | 0.731837 | 0.757250 | 0.737134 | 0.428571 | 0.749191 | 0.792477 | 0.748380 | 0.317460 | 0.585685 | 0.636313 | 0.593407 |
| thunlp_ms | 0.500000 | 0.585127 | 0.599209 | 0.593184 | 0.259921 | 0.611662 | 0.697354 | 0.591038 | 0.168651 | 0.395291 | 0.456952 | 0.387666 |
| thunlp_xs | 0.488095 | 0.573347 | 0.582891 | 0.586875 | 0.196429 | 0.576492 | 0.654889 | 0.560185 | 0.130952 | 0.374735 | 0.422532 | 0.376051 |
5 探索和尝试
本章使用2019年的阅读理解数据集(CJRC)作为辅助数据集,帮助模型提高阅读理解能力。
-
转换数据集
2019年的阅读理解数据集(CJRC)格式与本实验用的数据集格式不同,需要先将格式转换为2020年的数据集,然后将2个数据集融合。
pydef convert_context_to_2020(context_2019): ''' 把2019年案例内容根据标点符号分句,构造成2020年的原始标准格式 ''' context_2020=[] pattern = r',|\.|\:|;|!|\?|:|,|。|:|;|!|?' result_list = re.split(pattern, context_2019) context_2020.append(result_list[0]) context_2020.append(result_list) return [context_2020] def get_supporting_facts_sen_id(context_2019, answer_start, answer_text): ''' 把2019年案例的回答依据,构造成2020年的格式。 ''' pattern = r',|\.|\:|;|!|\?|:|,|。|:|;|!|?' sen_list = re.split(pattern, context_2019) answer_index = 0 sen_id = {} for i, sen in enumerate(sen_list): # 在分句后的案例内容中查找行号 index = sen.find(answer_text) if index >=0 : sen_id[i] = abs(answer_start - answer_index - index) answer_index += len(sen) supporting_fact = [] supporting_fact.append(sen_list[0]) if len(sen_id) ==0 : supporting_fact.append(-1) else: supporting_fact.append( min(sen_id, key=sen_id.get)) return [supporting_fact] train_2019 = [] for i, case_2019 in enumerate(full_data_2019['data']): case_2020= {} # 遍历qas, question_2019 = {} # 先取question_2019为true for qa in case_2019['paragraphs'][0]['qas']: # 过滤answers为空的question if qa['is_impossible']=='true' and len(qa['answers']) > 0 and qa['answers'][0]['answer_start'] !=-1: question_2019=qa break if len(question_2019)==0: for qa in case_2019['paragraphs'][0]['qas']: # 过滤answers为空的question if qa['is_impossible']=='false' and len(qa['answers']) > 0 and qa['answers'][0]['answer_start'] !=-1: question_2019=qa answer_txt =qa['answers'][0]['text'] # 取出answers的text为yes或no的第一个question if answer_txt.lower() == 'yes' or answer_txt.lower() == 'no': break case_2020['_id'] = i+5055 case_2020['context'] = convert_context_to_2020(case_2019['paragraphs'][0]['context']) case_2020['question'] = question_2019['question'] case_2020['answer'] = question_2019['answers'][0]['text'] case_2020['supporting_facts'] =get_supporting_facts_sen_id(case_2019['paragraphs'][0]['context'], question_2019['answers'][0]['answer_start'], question_2019['answers'][0]['text']) train_2019.append(case_2020) -
数据训练
!python /home/mw/project/run_cail.py \ --name chinese-bert-wwm \ --bert_model '/home/mw/input/law_QA5449/5 法律智能问答案例/models/chinese_wwm_pytorch' \ --data_dir '/home/mw/input/law_QA5449/chinese-bert-wwm_add2019/chinese-bert-wwm_add2019' \ --prediction_path '/home/mw/work/law_QA/predictions' \ --checkpoint_path '/home/mw/work/law_QA/checkpoints' \ --batch_size 2 \ --eval_batch_size 32 \ --lr 1e-5 \ --gradient_accumulation_steps 4 \ --seed 56 \ --epochs 25 -
模型测试
for i in range(1,26): !python /home/mw/project/evaluate.py /home/mw/work/law_QA/predictions/chinese-bert-wwm/pred_seed_56_epoch_{i}_99999.json '/home/mw/input/law_QA5449/5 法律智能问答案例/data/dev.json'-
基础结果
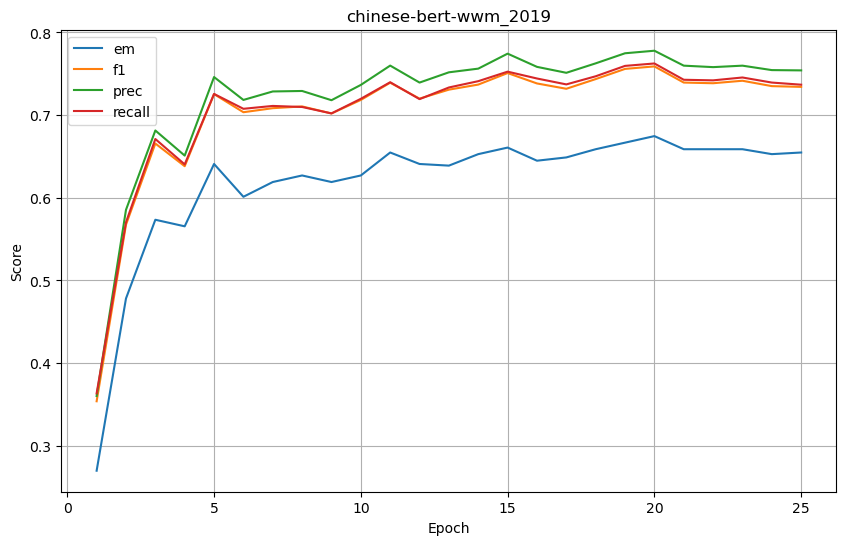
-
SP (Supporting Facts) 结果
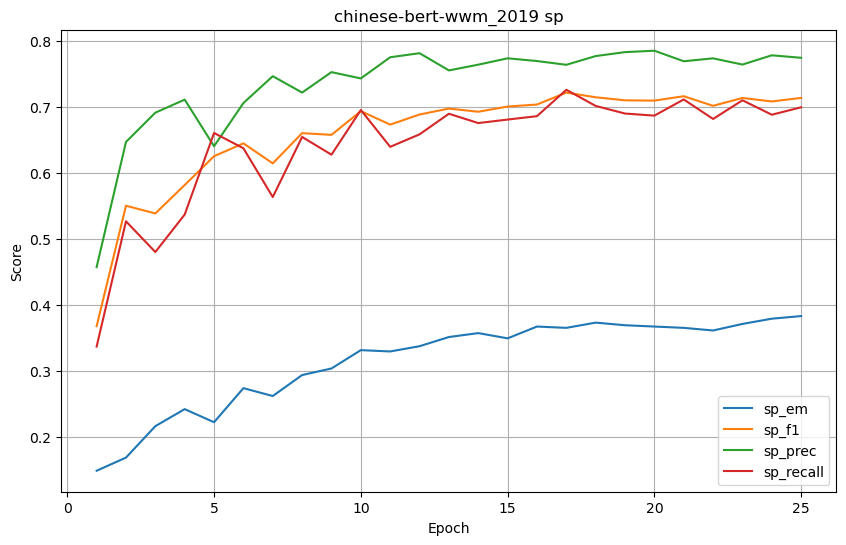
-
joint 结果

-
-
对比数据
模型/指标 em f1 prec recall sp_em sp_f1 sp_prec sp_recall joint_em joint_f1 joint_prec joint_recall chinese-bert-wwm_2019 0.654761 0.734139 0.754081 0.736786 0.382936 0.713156 0.773908 0.699007 0.303571 0.564823 0.624878 0.558694 chinese-bert-wwm 0.676587 0.760272 0.779338 0.766072 0.369048 0.714164 0.752504 0.718518 0.281746 0.584557 0.626606 0.593274 chinese_roberta_wwm_ext 0.658730 0.731837 0.757250 0.737134 0.428571 0.749191 0.792477 0.748380 0.317460 0.585685 0.636313 0.593407 thunlp_ms 0.500000 0.585127 0.599209 0.593184 0.259921 0.611662 0.697354 0.591038 0.168651 0.395291 0.456952 0.387666 thunlp_xs 0.488095 0.573347 0.582891 0.586875 0.196429 0.576492 0.654889 0.560185 0.130952 0.374735 0.422532 0.376051
发现仅在 sp_prec 、joint_em 两个值取得最高值,并没有明显提升。