目录
[1.1 Redis是什么?](#1.1 Redis是什么?)
[1.2 Redis的特性](#1.2 Redis的特性)
[1.2.1 速度快](#1.2.1 速度快)
[1.2.2 基于键值对的数据结构服务器](#1.2.2 基于键值对的数据结构服务器)
[1.2.3 丰富的功能](#1.2.3 丰富的功能)
[1.2.4 简单稳定](#1.2.4 简单稳定)
[1.2.5 持久化](#1.2.5 持久化)
[1.2.6 主从复制](#1.2.6 主从复制)
[1.2.7 高可用和分布式](#1.2.7 高可用和分布式)
[1.3 Redis的使用场景](#1.3 Redis的使用场景)
[1.3.1 缓存](#1.3.1 缓存)
[1.3.2 排行榜系统](#1.3.2 排行榜系统)
[1.3.3 计数器应用](#1.3.3 计数器应用)
[1.3.4 社交网络](#1.3.4 社交网络)
[1.3.5 消息队列](#1.3.5 消息队列)
[2.1 基本全局命令](#2.1 基本全局命令)
[2.1.1 KEYS](#2.1.1 KEYS)
[2.1.2 EXISTS](#2.1.2 EXISTS)
[2.1.3 DEL](#2.1.3 DEL)
[2.1.4 EXPIRE](#2.1.4 EXPIRE)
[2.1.5 TTL](#2.1.5 TTL)
[2.1.6 TYPE](#2.1.6 TYPE)
[2.2 数据结构和内部编码](#2.2 数据结构和内部编码)
1.初识Redis
1.1 Redis是什么?
Redis是一个在内存中存储数据的中间件,用于作为数据库,用于作为数据缓存,在分布式系统中有很大的用处,由于Redis将所有的数据存储在内存中,所以Redis的读写性能非常高效
1.2 Redis的特性
1.2.1 速度快
1)Redis数据存储在内存中,所以就比访问硬盘的数据库快很多
2)Redis的核心功能都是比较简单的操作内存的数据结构
3)从网络的角读看,Redis使用了IO多路复用的方式,一个线程管理多个socket
4)Redis使用了单线程模型,减少了不必要的线程之间的竞争开销
1.2.2 基于键值对的数据结构服务器
Redis是一种基于键值对的NoSQL数据库,与很多键值对数据库不同的是,Redis中的值可以是由String、hash、list、set、zset(有序集合)、Bitmaps(位图)等多种数据结构和算法组成,因此Redis可以满足很多的应用场景
1.2.3 丰富的功能
除了5中数据结构,Redis海提供了许多额外的功能:
1)提供了键过期功能,可以用来实现缓存
2)提供了发布订阅功能,可以用来实现消息系统
3)支持Lua脚本功能,可以利用Lua创建出新的Redis命令
4)提供了简单的事务功能,能在一定程度上保证事务特性
5)提供了流水线功能,客户端能将一批命令一次性传到Redis,减少了网络的开销
1.2.4 简单稳定
Redis的简单主要表现在三个方面,首先,Redis的源码很少,相对于很多NoSQL数据库来说代码量相对要少很多。其次,Redis使用单线程模型,使得Redis服务端处理模型变得简单。最后,Redis不需要依赖其他操作系统中的类库,自己实现了事件处理的相关功能
1.2.5 持久化
通常看,将数据放在内存中不安全,一旦发生断电,重要的数据可能就会丢失,因此Redis提供了两种持久化的方式:RDB和AOF,使用两种策略将内存的数据保存到硬盘中,这样就保证了数据的可持久化
1.2.6 主从复制
Redis提供了复制功能,实现了多个相同的Redis副本,复制功能是分布式Redis的基础
1.2.7 高可用和分布式
Redis提供了高可用实现的Redis哨兵(Redis Sentinel),能够保证Redis结点的故障发现和故障自动转移,也提供了Redis集群(Redis Cluster),是真正的分布式实现,提供了高可用、读写和容量的扩展性
1.3 Redis的使用场景
1.3.1 缓存
缓存机制几乎在所有的网站都有使用,合理的使用缓存可以加速数据的访问速度,Redis提供了键值对过期时间设置,并且也提供了灵活控制最大内存和内存溢出后的淘汰策略
1.3.2 排行榜系统
Redis提供了列表和有序集合的结构,合理地使用这些数据结构可以很方便地构建各种排行榜系统
1.3.3 计数器应用
在视频网站中,每播放一次视频播放量就加1,如果并发量很大对于传统关系型数据的性能是⼀种挑战,Redis天然支持计数功能而且计数的性能也非常好,可以说是计数器系统的重要选择
1.3.4 社交网络
由于社交网站访问量通常比较大,而且传统的关系型数据不太合适保存这种类型的数据,Redis提供的数据结构可以相对比较容易地实现这些功能
1.3.5 消息队列
消息队列系统可以说是一个大型网站的必备基础组件,因为其具有业务解耦、非实时业务削峰等特性。Redis提供了发布订阅功能和阻塞队列的功能,对于一般的消息队列功能基本可以满足
2.Redis常见的数据类型
2.1 基本全局命令
Redis由5中数据结构,它们都是键值对中的值,对于键来说有一些通用的命令
2.1.1 KEYS
返回所有满足样式的key,例如
h?llo匹配hello,hallo和hxllo,?匹配任意一个字符
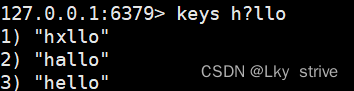
h*llo匹配hllo,hello,heeeello,*匹配0个或者多个任意字符
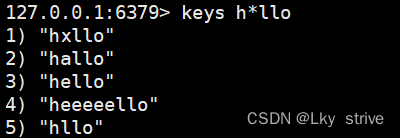
haello匹配hello和hallo,ae只能匹配a和e

h\^e匹配hallo,hxllo,\^e排除e,其他都能匹配

ha-bllo匹配hallo和hbllo,只匹配a-b之间的范围,包含两侧边界

keys的时间复杂度是O(N),其中keys *(查询redis中的所有key)
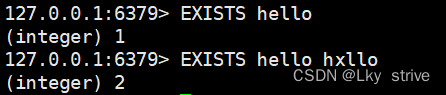
2.1.2 EXISTS
判断某个key是否存在
时间复杂度:O(1)
返回值:key存在的个数
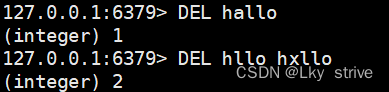
2.1.3 DEL
删除指定的key
时间复杂度:O(1)
返回值:删除掉key的个数
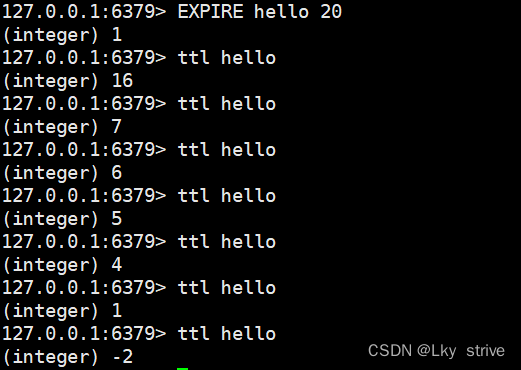
2.1.4 EXPIRE
为指定的key添加秒级的过期时间,key存活时间超过指定的值就会被自动删除
时间复杂度:O(1)
返回值:1表示设置成功,0表示设置失败


2.1.5 TTL
获取指定key的过期时间,秒级
时间复杂度:O(1)
返回值:剩余时间。-1表示没有关联过期时间,-2表示key不存在
2.1.6 TYPE
返回key对应的数据类型,Redis的所有key都是String,key对应的value可能会存在多种类型
时间复杂度:O(1)
返回值:none,string,list,set,zset,hash,stream

总结:
keys:用来查看匹配规则的key
exists:用来判定指定key是否存在
del:删除指定的key
expire:给key设置过期时间
ttl:查询key的过期时间
type:查询key对应的value的类型
2.2 数据结构和内部编码
type命令实际返回的就是当前键的数据结构类型,它们分别是:String、list、hash、set、zest,这些只是Redis对外的数据结构
Redis数据结构和内部编码
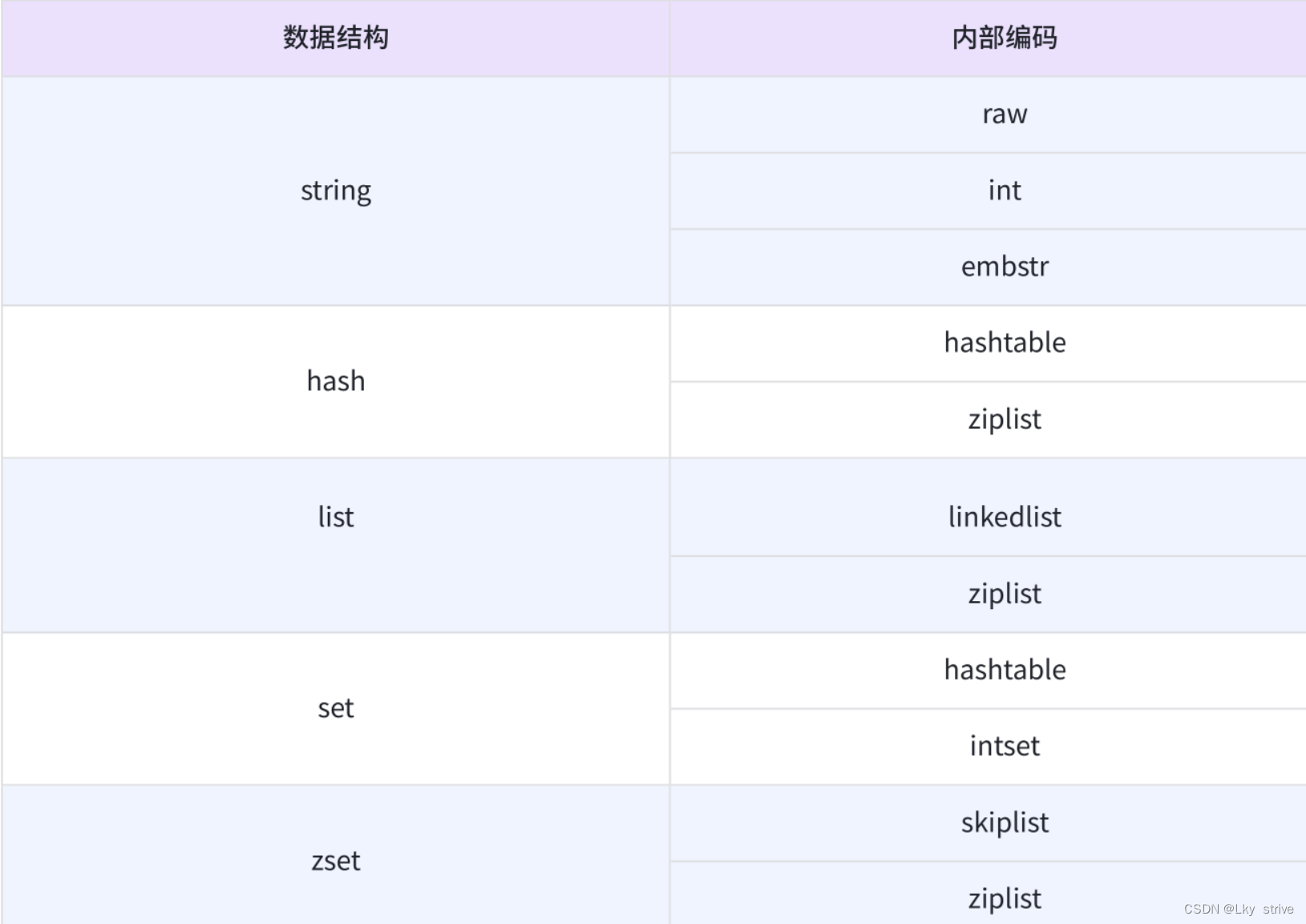
String
raw:最基本的字符串
int:redis通常也可以用来实现一些"计数"功能,当value是一个整数的时候,此时可能redis会直接使用int来保存
embstr:针对短字符串进行的特殊优化
hash
hashtable:最基本的哈希表
ziplist:压缩列表,当哈希表里面的元素比较少时,可能就优化成ziplist,从而节省空间
list
linkedlist:链表
ziplist:压缩列表
从Redis3.2开始,引入新的实现方式quicklist,它同时兼顾了linkedlist和ziplist的优点,其中quicklist就是一个链表,每个元素又是一个ziplist,兼顾到时间和空间
set
intset:集合中存的都是整数
zset
skiplist:跳表
上述每种数据结构都有至少两种以上的内部编码实现,其中可以通过object encoding命令来查询内部编码
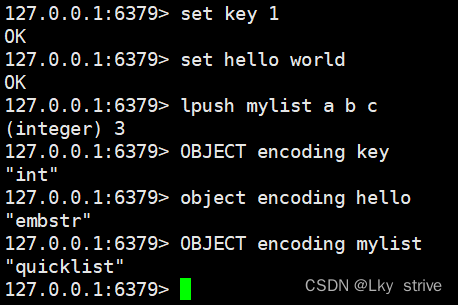
hello对应值的内部编码时embstr,mylist对应值的内部编码时ziplist
Redis这样设计有两个好处:
1)可以改进内部编码,而对外的数据结构和命令没有任何影响,因此一旦开发出更优秀的内部编码,无需改动外部数据结构和命令,形成了高内聚低耦合,例如Redis3.2提供了quicklist,它是结合了ziplist和linkedlist两者的优点,为列表类型提供了一种更为优秀的内部编码实现,用户是感知不到的
2)多种内部编码实现可以在不同场景下发挥各自的优势,例如ziplist比较节省内存,但是在列表元素比较多的情况下,性能会下降,这时候Redis会根据配置选项将列表类型的内部实现转换为
linkedlist,整个过程用户也感知不到