定义
kafka是一个分布式的基于发布/订阅模式的消息队列(message queue),主要应用于大数据的实时处理领域
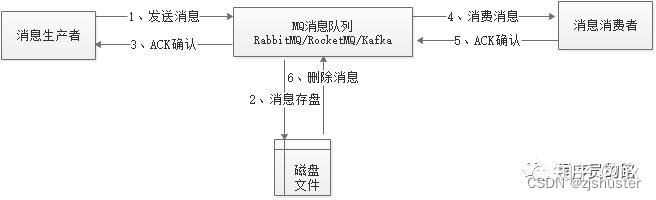
消息队列工作原理
kafka的组成结构
kafka的基础架构主要有broker、生产者、消费者组构成,还包括zookeeper.
生产者负责发送消息
broker负责缓冲 消息,存储在磁盘的,所以数据不易丢失,broker中可以创建topic,每个topic又有partition和replication的概念
消费者组负责处理 消息,同一个消费者组的中消费者不能消费同一个partition中的数据
Kakfa如果要组件集群,则只需要注册到一个zk中就可以了,zk中还保留消息消费的进度或者说偏移量或者消费位置
工作流程
1)主线程首先将业务数据封装成ProducerRecord对象
2)调用send方法将消息放入消息收集器RecordAccumlator中暂存
3)Sender线程将消息信息构成请求
4)执行网络IO的线程从RecordAccumlator中将消息取出并批量发送出去
5)Kafka消费者从属于消费者组。消费者组内的消费者订阅的是相同主题,每个消费者接收主题的一部分分区的消息。
常见问题
1:kafka如何保证消息的顺序性?
Kafka 保证消息顺序性是指在单个分区内消息是有序的,即消费者从一个分区中读取消息时,这些消息是按照生产者发送的顺序来消费的。
为了保证消息的顺序性,你需要确保以下几点:
生产者将消息发送到同一个分区 。
不要并发写入同一个分区,否则可能会导致消息乱序。
消费者从分区中读取消息是按按顺序的并按顺序处理,保证了消息的顺序性。
2:kafka 生产者发送消息时如何来提高发送速率
要提高Kafka生产者的发送速率,可以调整Kafka生产者客户端的几个关键配置参数:
batch.size: 控制生产者一起发送数据的大小,默认是16KB。增加这个值可以批量发送更多的消息,从而提高发送速率。
linger.ms: 控制生产者发送数据之前等待更多消息加入到batch中的时间。降低这个值可以更快地发送小批量消息,默认值为0毫秒)。
max.request.size: 控制生产者能发送的最大消息大小。如果消息大小超过这个值,消息将会被截断。
buffer.memory: 控制生产者可以用来缓存消息的内存大小。增加这个值可以缓存更多的消息。
compression.type: 控制消息被压缩的方式,可以选择压缩类型来减少发送的数据量。