本期直播我们邀请到 KaiwuDB 高级研发工程师冯友旭为大家分享《KWDB 分布式架构探究------数据分布与特性》,点击下方视频观看完整版回放 ↓↓↓
KWDB 分布式架构探究------数据分布与特性
📌以下为重点内容节选,点击上方视频查看完整版内容。
背景介绍
数据分布在数据库中的作用至关重要,它直接影响到数据库系统的性能、可扩展性、可用性、管理效率和成本。特别是在处理海量数据和高并发请求的现代应用中,合理的数据分布策略是数据库架构设计的核心。本期直播重点讲解了数据分布在分布式数据库中的重要性、 KWDB 数据库分布式架构设计方案、特性及具体实践案例。
1. 数据分布概述
1.1 为什么考虑数据分布?
1.2 数据分布概述------分区方式
- Hash 适合预分片,系统会更具确定性;Range 更依赖调度系统
- Range 对范围查询很友好,Hash 范围查询基本等价于全表扫描
- Range 对前缀查询很友好,实际上属于一种范围查询
-
Range 分区与 Hash 分区都能很好的解决数据分布热点问题
-
Range 在自增序列、时间等字段的写入容易导致热点,但可通过使用不自增的序列等方法规避
2. KWDB 数据分布概念及特性
2.1 KWDB 数据分布架构
-
无中心透明式分布式
-
分布式线性扩展
-
一致性及可靠性保障
-
多模数据分布(关系数据按 Range 进行分片;时序数据按时间戳 Hash 分布)
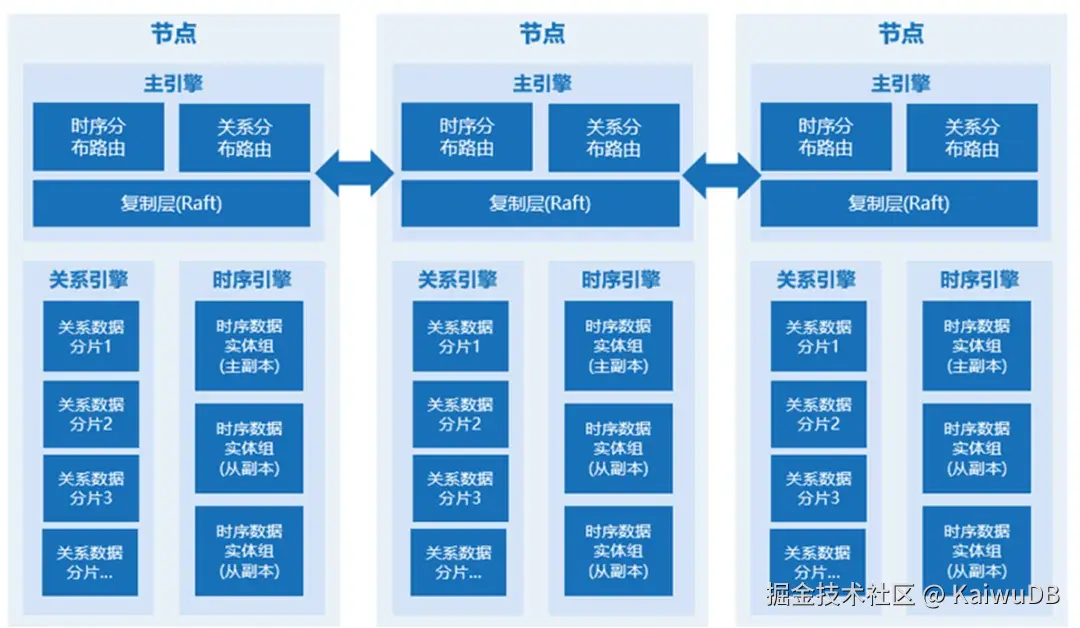
KWDB 数据分布架构图
2.2 KWDB 数据分布------数据分片 Range
数据分片 Range 的逻辑概念是数据的子集,代表数据分片/迁移及高可用操作的最小单元。
- 分片的均衡情况影响查询&写入性能
- 分片大小均衡粒度
- 分片数量决定副本层并发
2.3 KWDB 数据分布------关系数据与时序数据
关系数据:按照 Key 进行的 Range 分布。
- Key 由表 ID/主键(索引)进行构成
- 使用 rocksdb 进行存储
- 支持指定 Range 大小
- 支持 Range 的 Split/Merge
- 支持指定 Range 对应的副本数
时序数据:按照按照设备 Hash 进行的 Range 分布。
- Key 由表 ID/设备/时间戳进行构成
- 使用特殊的时序存储引擎进行存储
- 支持指定 Range 大小以及 Range 的 Split/Merge,但在达到最大 HashPoint 或时间间隔后不再分裂
- 支持指定 Range 对应的副本数
2.4 KWDB 时序数据分片------按照 Hash 环并引入时间分片
支持历史 Range 的 Merge 规则,通过 alter merge day 进行设置。
优势:
- 保证 Range 数量控制在一定范围内,元数据可控
- 历史 Range 大,但活跃 Range 分片小,更容易解决时序场景下的数据迁移和写热点问题
- 支持冷热数据分片和分级存储
2.5 KWDB 时序数据写入流程
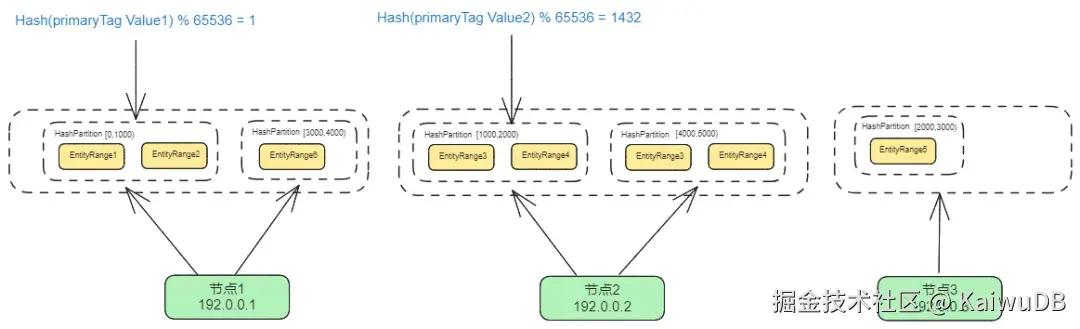
KWDB 时序数据写入流程
Hashpoint:根据 primaryTag 或 primaryTag/TimeStamp,通过 Hash (key)%HashNum 所计算出来的 Hash 值。
-
- 保证设备均匀打散
-
- 扩缩容和迁移场景避免重 Hash 过程
2.6 KWDB 数据分布特性------数据均衡(手动/自动)
sql
ALTER {RANGE DEFAULT | DATABASE db_name | TABLE tb_name} CONFIGURE ZONE USING rebalance;作用范围:
-
RANGE DEFAULT:全局时序表均衡
-
DATABASE:库级时序表均衡
-
TABLE:单表级均衡
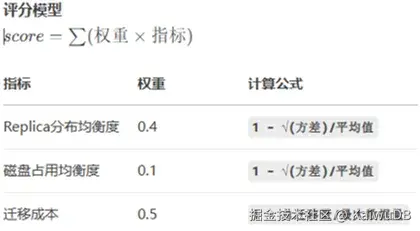
KWDB 评分模型

KWDB 数据均衡方案
3. KWDB 数据分布实践
3.1 HashNum 及 Range Size
考虑元数据的膨胀系数以及集群的读写性能的稳定性。
建议:16C/32G 3 节点集群 Range 总数量不超过 1000 ,5 节点集群 Range 总数量不超过 3000,增加一个节点增加 Range 数量不超过 500。
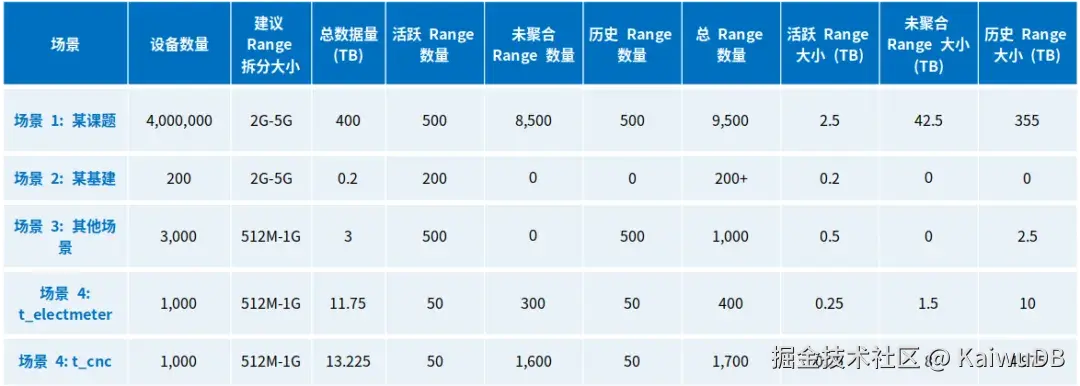
KWDB 业务场景 HashNum 及 Range Size 计算示例
3.2 热点 Range 分析
优化策略:
-
热点 Range Follower 查询,定义时序查询允许走 Follower Read
-
支持手动 Range Split/Merge
-
修改 Range 分区方案
-
自定义数据固定
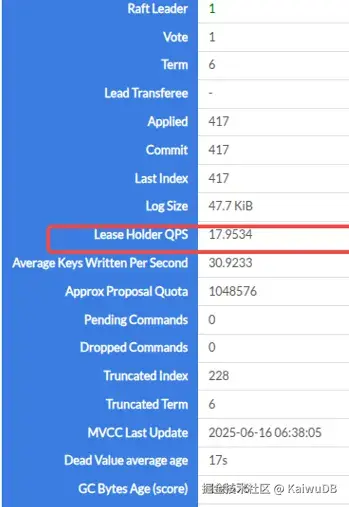
Range 统计 QPS/TPS