在上一章中罗列了对RAG准确度的几个重要关键点,主要包括2方面,这一章就针对其中一方面,来做详细的讲解以及其解决方案。
目录
- [1 文档解析](#1 文档解析)
-
- [1.1 文档解析工具](#1.1 文档解析工具)
- [1.2 实战经验](#1.2 实战经验)
- [1.3 代码演示](#1.3 代码演示)
- [2 文档分块](#2 文档分块)
-
- [2.1 分块算法](#2.1 分块算法)
- [2.2 实战经验](#2.2 实战经验)
- [2.3 代码演示](#2.3 代码演示)
- [3 文档embedding](#3 文档embedding)
-
- [3.1 实战经验](#3.1 实战经验)
- [3.2 代码演示](#3.2 代码演示)
- [4 向量数据库](#4 向量数据库)
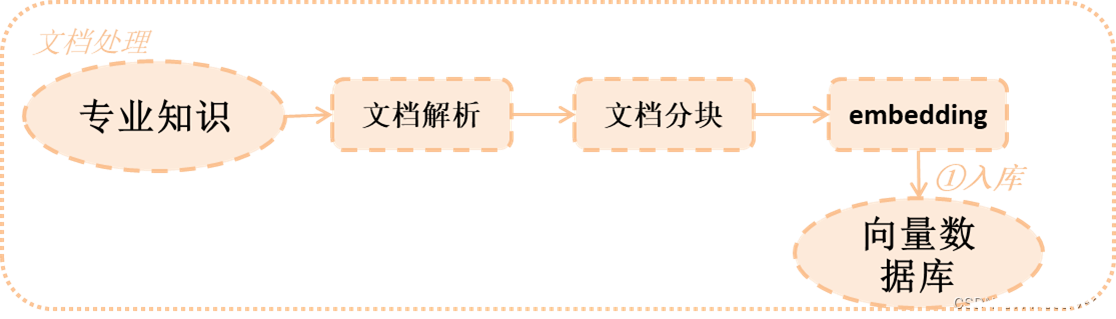
1 文档解析
对于我们来说,查询的文档可能包括pdf、Excel、图片等等各种各样的内容,而这些内容中包括很多不同的格式,比如pdf中可能还包括表格和图片,因此选择哪些文档解析工具非常重要。
1.1 文档解析工具
在市面上有很多各种各样的解析工具,不同解析工具有着不同的解析方法,在langchain中已经集成了很多针对不同类型文档的解析,可供大家选择。(注意:其中有(非)标志代表没有集成在langchain中,另外还有其它的就没有一一罗列了)
| 文档类型 | 解析工具 |
|---|---|
| txt | TextLoader、unstructured |
| unstructured、pypdf、pdfplumer、pdfminer、Camelot(非)、pymupdf(非)、LlamaParse (非) | |
| word | unstructured |
| PPT | unstructured |
| html | unstructured、Firecrawl(非) |
| json | JSONLoader |
| 图片 | unstructured |
| Excel | CSVLoader |
| markdown | unstructured |
| unstructured | |
| arxiv | ArxivLoader |
1.2 实战经验
其实不同文件的读取无非就是想看看能否很好的将文件内容解析出来,而解析的好与坏其实跟你要解析的文档息息相关。以下是常见几个考察点:
- 文本不丢失
- 语言支持情况(中文、英文等)
- 段落信息是否能解析(段落其实是一个很重要却容易被忽视的考察点,因为模型是理解文本,因此段落有助于更好的理解文档的语义)
- 标题是否能识别
- 表格,图片信息能否读取
- 针对不同文档类型的细节(比如pdf的页头、页尾、分栏等细节)
下面以pdf为例,简述一下pdf各类工具的优缺点:
| 工具 | 语言支持 | 段落信息 | 表格图片 | 细节 |
|---|---|---|---|---|
| pypdf | 英文支持较好 | 段落支持一般 | 表格图片差 | 分栏 |
| pdfplumer | 中文支持好 | 段落支持好 | 表格读取好 | 分栏效果不好 |
| pdfminer | 中文支持好 | 段落支持好 | 表格图片一般 | 分栏 |
| pymupdf(非) | 中午支持较好 | 段落支持好 | 表格图片一般 | 分栏 |
| Camelot(非) | 中文支持好 | 段落支持一般 | 表格图片好 | 分栏 |
| LlamaParse (非) | 中午支持较好 | 段落支持好 | 表格图片好 | 分栏 |
1.3 代码演示
以下以PyPDF和PDFMiner为例子给大家演示一下代码
python
# 1 PyPDF演示,安装pypdf:pip install pypdf
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("data/demo.pdf")
pages = loader.load()
# 读取后pages长度=6,说明按照每一页读取的
print(len(pages))
# 段落,我们可以看到其中文本:ABSTRACT 的前面的换行与其它换行并不没有不同,因此识别段落一般
print(pages[0].page_content[300:400])
# 表格,之所以选取第4页,是该页有表格,可以看到表格内容已经被解析出来
print(pages[3].page_content)
# 图片,之所以选取第3页,是该页有图片(可以看到图片不能解析,需要配合rapidocr-onnxruntime,后续有例子)
print(pages[2].page_content)
# 读取图片,需要安装rapidocr-onnxruntime:pip install rapidocr-onnxruntime
loader = PyPDFLoader("data/demo.pdf", extract_images=True)
pages = loader.load()
print(pages[2].page_content)
# 2 演示PDFMiner,提前安装pdfminer.six:pip install pdfminer.six
from langchain.document_loaders import PDFMinerLoader
loader = PDFMinerLoader("data/demo.pdf")
pages = loader.load()
# 读取后pages长度=1,说明将文档按照一页读取
print(len(pages))
# 段落,我们可以看到其中文本:ABSTRACT 的前面的换行与其它换行不同,因此很好的识别段落
print(pages[0].page_content[400:600])
# 表格和图片,我们可以找一些大概第3页的图片能够被解析出来,第4页表格内容也能够被解析出来
print(pages[0].page_content)从上面代码可以看出,我们分析了几个要素
- 段落:很明显PDFMiner能够识别更好的段落,即大标题这些可以有2个换行符合,而PyPDF并不能
- 图片和表格:PyPDF增加插件也能识别
- 分页:为什么要列分页,因为这样省的你去讲每一页都手动连接在一起
- 换行:这里还有一个细节,就是事实上pdf中的换行并不是内容真正换行,大家可以尝试一下unstructured,实际上会将不是真正换行的拼接在一起,这样可以让模型理解语义更加容易
因此对于不同文件类型,选型非常重要,特别是对你的业务文档类型以及文档中包含的内容,都是一种考察需求。
2 文档分块
前文已经讲了之所以要分块是因为2个原因:
- 因为大模型有token长度限制
- 过长的token其实对于大模型的理解和推理会变慢或者不准确。
那么文档分块如何分,怎么分才是最佳的,下面通过2个方面讲述一下
2.1 分块算法
文本分块的的分割流程如下:
- 1)将文本拆分为小的、语义上有意义的块(通常是句子)。
- 2)将这些小块组合成较大的块,直到达到某个大小(即你设定的大小,通常有一个函数测量)。
- 3)一旦达到该大小,将该块作为自己的文本片段,然后开始创建一个具有一定重叠的新文本块(以保持块之间的上下文)。
分块流程如上,那么这意味着有3个方面将影响你的分块:
- 文本如何拆分
- 块大小如何测量
- 重叠块大小
下表就是按照不同分块逻辑,罗列出目前的分块算法,其应用也在描述中体现出来,大家可以按照自身文档的内容选取不同的分块算法:
| 方法 | 分块符号 | 是否加入metadata | 描述 |
|---|---|---|---|
| Character | 用户自定义字符 | 基于用户定义的字符拆分文本。一种更简单的方法。 | |
| Recursive | 用户自定义字符的列表 | 递归拆分文本。递归分割文本的目的是试图将相关的文本片段保持在一起。这是开始拆分文本的推荐方式。 | |
| Markdown | Markdown 特定字符 | √ | 基于特定于Markdown的字符拆分文本。值得注意的是,这增加了关于该块来自哪里的相关信息(基于降价) |
| HTML | HTML特定字符 | √ | 基于特定于HTML的字符拆分文本。值得注意的是,这添加了关于该块来自何处的相关信息(基于HTML) |
| Code | Code (Python, JS) 特定字符 | 基于特定于编码语言的字符拆分文本。有15种不同的语言可供选择。 | |
| Token | Tokens | 拆分令牌上的文本。有几种不同的方法来衡量token。 | |
| Semantic Chunker | 句子或语义 | 首先对句子进行拆分。然后,如果它们在语义上足够相似,就将它们组合在一起。 |
2.2 实战经验
如何选择符合自身业务的分块,这里有一些准则可供大家参考:
- 分块算法:不同业务类型,对应不同的分块算法,在2.1中的表格可以供大家选择。
- 块的大小:这一部分可能没有统一标准说到底多大合适,一般都需要通过实验验证。比如你使用什么模型,其token限制是多少,然后在此基础上,可以按照128、256、512、1024等等不同分块方式去测试比如:响应时间、正确率、关联度等指标。
- 重叠部分:至于需要重叠多少,这个也是没有统一标准,按照块的大小的方式去测试。
2.3 代码演示
下面例子,选择Recursive分块算法,来说明一下分块时需要注意的问题:
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
text = '''ChatGLM-6B
是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客。欢迎通过 chatglm.cn 体验更大规模的 ChatGLM 模型。
为了方便下游开发者针对自己的应用场景定制模型,我们同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
ChatGLM-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。'''
# 1.按照300进行分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=0,
length_function=len
)
chunks = text_splitter.split_text(text)
print(len(chunks))
# 我们可以看到其分割为3段,长度分别是10、292、136.其实他默认的分隔符就是换行
for chunk in chunks:
print(len(chunk))
# 2.按照200进行分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=0,
length_function=len
)
chunks = text_splitter.split_text(text)
print(len(chunks))
# 我们可以看到其分割为4段,长度分别是10、169、122、136。其中第二段被分了2段。因为原来第二段不符合200.
for chunk in chunks:
print(len(chunk))
# 但是这里有个问题,可以打印第二段,发现其分割有点随机,把我们有语义关联的一句话分开掉。
print(chunks[1])
# 3.解决分割不符合语义,通过separators传入分割符合,会按照分割符合顺序进行分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=0,
length_function=len,
separators=["\n", "。", ","],
keep_separator=True
)
chunks = text_splitter.split_text(text)
print(len(chunks))
# 我们可以看到其分割为4段,长度分别是10、162、130、136。
for chunk in chunks:
print(len(chunk))
# 这里就解决了分割
print(chunks[1])从上面代码可以看到
- 分块的逻辑:是先按照一个大的分隔符进行分割,默认是换行符,然后再将较小的合并到符合长度之下。也就是前面所说的分割流程
- 分块分隔符:当默认的时,有可能没有次级的分块分隔符,那么会随机切断,所以使用separators参数传入,可以更好分割
3 文档embedding
文档最终是通过embedding向量化后存入向量数据库,而选择不同embedding对于最终查询来说非常重要(这里大家可以自行补一下embedding基础,这里就不讲embedding原理)。如果embedding做得不好,导致查询的结果与答案不一致,那么如何选对embedding也是对于RAG的准确度至关重要。
这里需要注意的是embedding也是一个训练好的模型,目前大部分开源的embedding模型都是使用Sentence Bert。这里不详细讲述,大家有兴趣可以去了解其论文。这个主要给大家讲述几个重要选择embedding模型的实战参考。
3.1 实战经验
对于我们如何选择一个embedding,我根据一些实战中的经验总结如下:
- 排行榜:首先要知道有哪些embedding模型,一般我们去hugging face的排行版上找:https://huggingface.co/spaces/mteb/leaderboard
- 语言:在排行榜中,你可以根据你的业务选择语言
- embedding维度:这个需要根据你的业务,如果你业务语义丰富,那么选择维度更高更好,如果语义不丰富,其实选择维度更低会更好。
- sequence length:不同embedding模型支持不同sequence length,因此需要根据你的业务选择不同的模型
- 模型大小:这个会根据实际你有多少资源作为选择标准
- 业务效果:以上几个标准可能只是基本维度,最终还是需要看看业务效果,因此你可能需要选择几个比较合适的模型,然后再逐一的去测试一下其效果相对于你的业务结果如何
3.2 代码演示
下面通过m3e-base模型加上TSNE画出相关性,可以直观感受到你的模型是否准确理解句子的语义。
(注明:本例子来自大神的demo代码 :https://github.com/blackinkkkxi/RAG_langchain/blob/main/learn/embedding_model/embedd.ipynb)
python
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('moka-ai/m3e-base')
# 测试句子
sentences =['为什么良好的睡眠对健康至关重要?' ,
'良好的睡眠有助于身体修复自身,增强免疫系统',
'在监督学习中,算法经常需要大量的标记数据来进行有效学习',
'睡眠不足可能导致长期健康问题,如心脏病和糖尿病',
'这种学习方法依赖于数据质量和数量',
'它帮助维持正常的新陈代谢和体重控制',
'睡眠对儿童和青少年的大脑发育和成长尤为重要',
'良好的睡眠有助于提高日间的工作效率和注意力',
'监督学习的成功取决于特征选择和算法的选择',
'量子计算机的发展仍处于早期阶段,面临技术和物理挑战',
'量子计算机与传统计算机不同,后者使用二进制位进行计算',
'机器学习使我睡不着觉',
]
# 通过调用model的encode进行embedding
embeddings = model.encode(sentences)
len(embeddings)
len(embeddings[0])
# 通过TSNE工具画出图表来直观看看相关性
tsne = TSNE(n_components=2 , perplexity=5)
embeddings_2d = tsne.fit_transform(embeddings)
plt.rcParams['font.sans-serif'] = ['Kaitt', 'SimHei']
plt.rcParams['axes.unicode_minus'] = False
color_list = ['black'] * len(embeddings_2d[1:])
color_list.insert(0, 'red')
plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1] , color=color_list )
for i in range(len(embeddings_2d)):
plt.text(embeddings_2d[:,0][i], embeddings_2d[:,1][i]+2, sentences[i] ,color=color_list[i] )
# 显示图表
plt.show()4 向量数据库
向量数据库需要存储向量化后的数据,然后通过问题查询相似度,得到最终相关的几个答案,扔给大模型进行回答。那么向量数据库的存储和相似度查询就可能会影响RAG最终的结果,因此,我们选择哪一种向量数据库,对于我们来说还是比较重要的。(注意:这里可能只从影响RAG准确度来说,真正选择向量数据库可能要考虑的方面还是比较多的,这里就不列举了)
向量数据库中,相似度是我们最看重的指标之一,因为它对于RAG最终的准确度有着很大的影响。以下表格列出几种不同相似度算法及其应用场景(注意也还有不同的算法,这里就不再累述,只是作为说明相似度)
| 算法 | 原理 | 应用场景 | 对应数据库 |
|---|---|---|---|
| 欧氏距离 | 欧几里得空间中,两个点之间的最短直线距离 | 机器学习 :欧氏距离常用于 k 最近邻算法 (KNN) 中,计算样本之间的距离。图像检索 :欧氏距离常用于图像检索中,计算图像之间的相似度。推荐系统:欧氏距离常用于推荐系统中,计算用户之间的相似度 | Chroma、Milvus、Faiss |
| 余弦相似度 | 在向量空间中,两个向量夹角的余弦值 | 文本检索 :余弦相似度常用于文本检索中,计算文本之间的相似度。自然语言处理 :余弦相似度常用于自然语言处理中,计算词语之间的相似度。信息检索:余弦相似度常用于信息检索中,计算文档之间的相似度 | Chroma、Milvus |
| 点积相似度 | 两个向量的点积除以它们的模长的乘积 | 文本检索 :点积相似度常用于文本检索中,计算文本之间的相似度。自然语言处理 :点积相似度常用于自然语言处理中,计算词语之间的相似度。推荐系统:点积相似度常用于推荐系统中,计算用户之间的相似度 | Chroma、Milvus 、Faiss |
| 曼哈顿距离 | 两个向量对应分量差的绝对值的总和 | 图像处理 :曼哈顿距离常用于图像处理中,计算图像之间的差异。机器学习 :曼哈顿距离常用于机器学习中,计算样本之间的距离。数据挖掘:曼哈顿距离常用于数据挖掘中,计算数据点之间的相似度 | Faiss |