摘要 :本文简要描述了Vulkan渲染一个3D模型需要做的事情,不会对太细节的内容进行深究。
关键字:Vulkan,Render,3D
1 简介
1.1 Vulkan简介
Vulkan是一个低开销、跨平台的二维、三维图形与计算的应用程序接口(API),最早由科纳斯组织在2015年游戏开发者大会(GDC)上发表。与OpenGL类似,Vulkan针对全平台即时3D图形程序(如电子游戏和交互媒体)而设计,并提供高性能与更均衡的CPU与GPU占用,这也是Direct3D 12和AMD的Mantle的目标。与Direct3D(12版之前)和OpenGL的其他主要区别是,Vulkan是一个底层API,而且能执行并行任务。除此之外,Vulkan还能更好地分配多个CPU核心的使用。
1.2 OpenGL vs Vulkan
| OpenGL | Vulkan |
|---|---|
| 单一的全局状态机 | 基于对象,无全局状态 |
| 状态与单一上下文绑定 | 所有状态概念都本地化到命令缓冲区 |
| 操作只能按顺序执行 | 允许多线程编程 |
| GPU内存和同步通常是隐藏的 | 显式控制内存管理和同步 |
| 广泛的错误检查 | Vulkan驱动在运行时不进行错误检查,提供了开发者使用的验证层 |
相比于传统的OpenGL,Vulkan API的设计更加贴近硬件。传统API比如OpenGL内部维护一个单一全局的状态机,这就意味着需要通过一个主线程来处理所有的绘图命令,即便驱动内部能够保证渲染足够高校,但是由于外部提交指令的方式是单线程的容易导致多核CPU的利用率不高。而Vulkan从设计上就考虑了多线程编程,允许开发者在多个线程中并行执行绘图命令和资源管理操作。这样可以大幅提升渲染性能,并使应用程序更具响应性。
另外,传统的API对开发者屏蔽了很多内部细节,这样做的好处是开发者使用起来比较简单,反之缺点是开发者只能通过较高层次的接口进行操作,无法对底层资源进行精细控制,这样可能会导致不必要的性能开销。Vulkan提供了更细粒度的资源管理接口,开发者可以精确控制资源的分配、释放和使用。这样可以减少不必要的资源开销,并允许更高级的优化操作。由于传统API将很多操作限制在了驱动层,驱动程序需要做大量的工作来优化和处理绘图命令,可能带来额外的性能开销。Vulkan通过简化驱动设计,使得驱动更轻量。Vulkan将很多工作(如资源管理和同步)交给开发者处理,这样驱动程序的开销更低,更易于调试和优化。
Vulkan具有更好的扩展性,支持最新的图形硬件特性。Vulkan的设计使得它可以更快速地集成和利用新硬件的功能,这样开发者可以更快地使用新硬件的特性来优化应用程序。由于Vulkan提供更加贴近硬件的API,虽然提升了性能,但是也意味着对开发者要求更高。
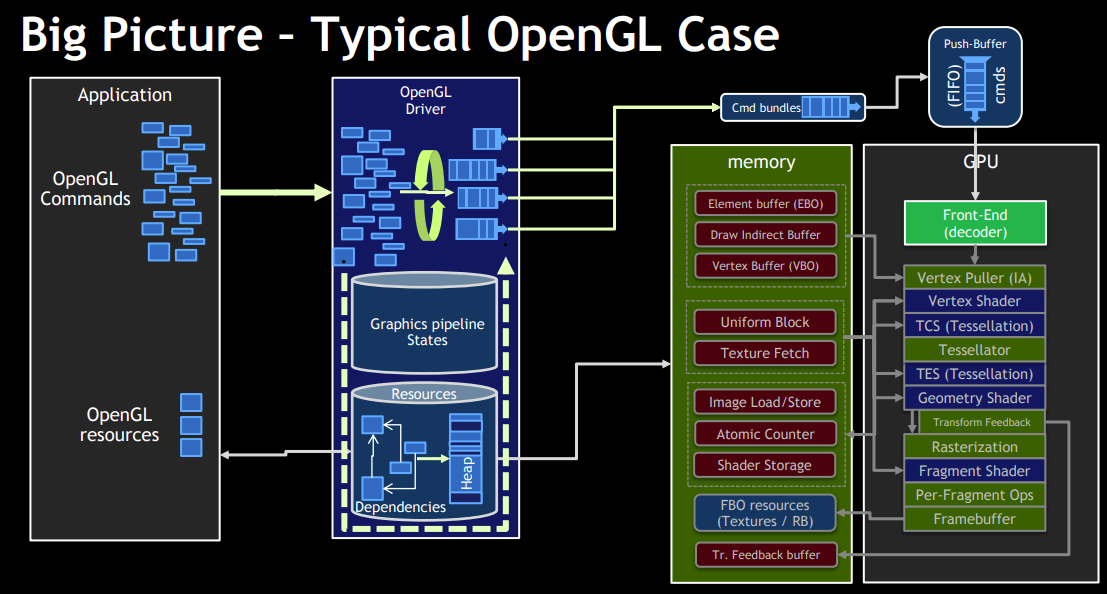
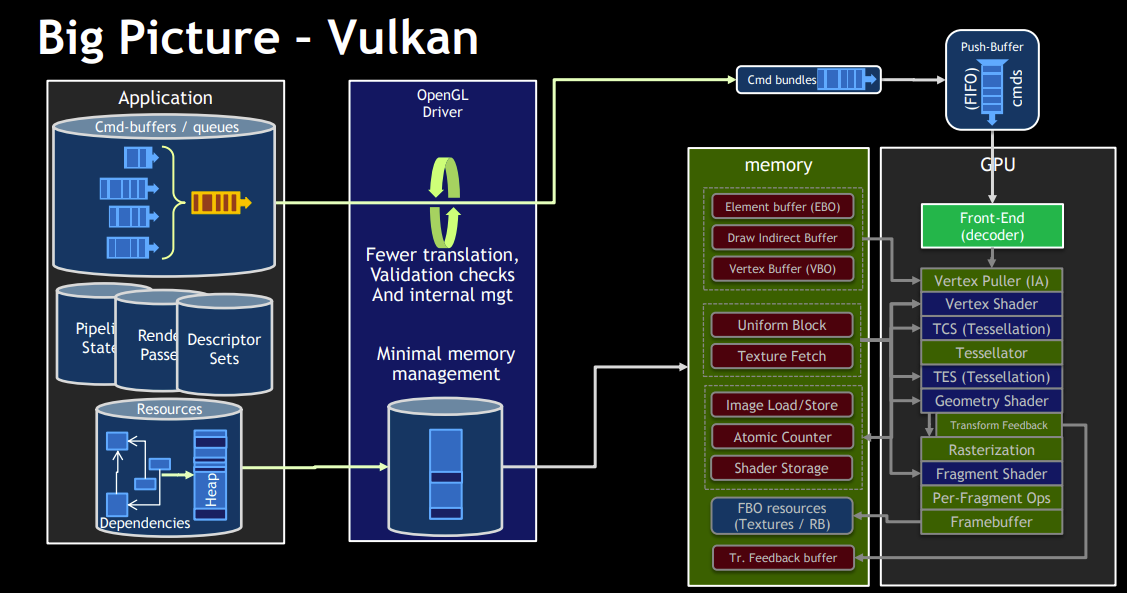
从上面的图片可以看出来Vulkan的驱动曾月层要更薄一些。
2 Vulkan
2.1 Instance
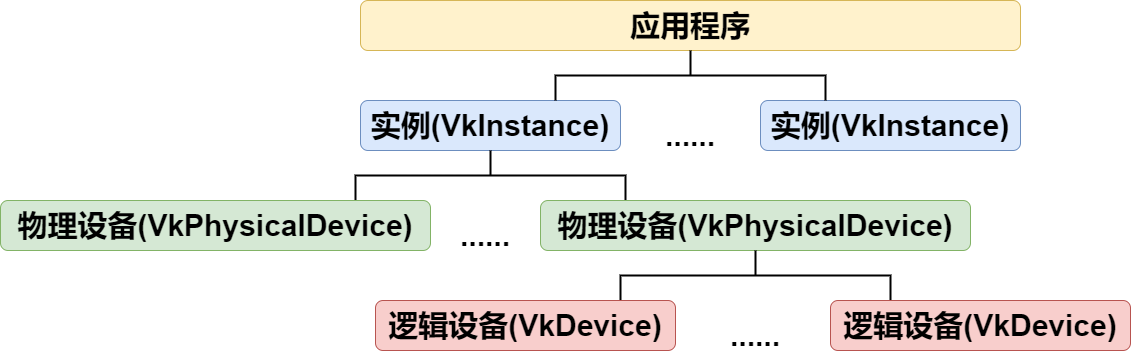
Instance是当前渲染环境的上下文,初始化Instance会加载Vulkan驱动程序。一般情况下,一个Vulkan应用程序只需要一个Instance,但在某些特定的场景下多个场景需要独立的渲染上下文时,需要创建多个Instance。比如独立的渲染上下文、不同设备或平台测试、调试和验证、插件或模块系统、多线程初始化以及虚拟化或容器化环境。根据具体需求选择合适的实例创建策略,可以更好地满足应用程序的功能和性能要求。
cpp
vk::ApplicationInfo appInfo = {
"Hello Vulkan",
VK_MAKE_VERSION(1, 0, 0),
"Everything but engine",
VK_MAKE_VERSION(1, 0, 0),
VK_API_VERSION_1_0 };
auto glfwExts = Vulkan::QueryGlfwExtension();
vk::InstanceCreateInfo createInfo = {
vk::InstanceCreateFlags{},
&appInfo,
0,
nullptr,
(uint32_t)glfwExts.size(),
glfwExts.data()
};
if(gEnableValidationLayer){
createInfo.enabledLayerCount = kValidationLayers.size();
createInfo.ppEnabledLayerNames = kValidationLayers.data();
vk::DebugUtilsMessengerCreateInfoEXT debugInfo = {};
debugInfo.messageSeverity = vk::DebugUtilsMessageSeverityFlagBitsEXT::eInfo
| vk::DebugUtilsMessageSeverityFlagBitsEXT::eError
| vk::DebugUtilsMessageSeverityFlagBitsEXT::eWarning;
debugInfo.messageType = vk::DebugUtilsMessageTypeFlagBitsEXT::eGeneral | vk::DebugUtilsMessageTypeFlagBitsEXT::ePerformance;
debugInfo.pfnUserCallback = DebugCallback;
createInfo.pNext = (VkDebugUtilsMessengerCreateInfoEXT*)&DebugCallback;
}
_instance = vk::createInstanceUnique(createInfo, nullptr);在创建Instance时可以指定期望开启的扩展,毕竟并不是所有的硬件都具有相同的硬件能力,比如只有Nvidia RTX系列有光追能力。下面是我本地机器支持的扩展状态:
cpp
The 0 extension,version:1, name:VK_KHR_device_group_creation
The 1 extension,version:23, name:VK_KHR_display
The 2 extension,version:1, name:VK_KHR_external_fence_capabilities
The 3 extension,version:1, name:VK_KHR_external_memory_capabilities
The 4 extension,version:1, name:VK_KHR_external_semaphore_capabilities
The 5 extension,version:1, name:VK_KHR_get_display_properties2
The 6 extension,version:2, name:VK_KHR_get_physical_device_properties2
The 7 extension,version:1, name:VK_KHR_get_surface_capabilities2
The 8 extension,version:25, name:VK_KHR_surface
The 9 extension,version:1, name:VK_KHR_surface_protected_capabilities
The 10 extension,version:6, name:VK_KHR_wayland_surface
The 11 extension,version:6, name:VK_KHR_xcb_surface
The 12 extension,version:6, name:VK_KHR_xlib_surface
The 13 extension,version:1, name:VK_EXT_acquire_drm_display
The 14 extension,version:1, name:VK_EXT_acquire_xlib_display
The 15 extension,version:10, name:VK_EXT_debug_report
The 16 extension,version:2, name:VK_EXT_debug_utils
The 17 extension,version:1, name:VK_EXT_direct_mode_display
The 18 extension,version:1, name:VK_EXT_display_surface_counter
The 19 extension,version:4, name:VK_EXT_swapchain_colorspace
The 20 extension,version:1, name:VK_EXT_surface_maintenance1
The 21 extension,version:1, name:VK_KHR_portability_enumeration
The 22 extension,version:1, name:VK_LUNARG_direct_driver_loading2.2 校验层
校验层是一个调试工具,用于帮助开发者在开发阶段捕获错误和潜在问题。校验层通过在API调用时执行额外的检查和验证,确保应用程序符合Vulkan规范,并提供有用的调试信息。校验层的启用比较简单,如上面创建Instance时的代码,指定相应参数即可。
2.3 Surface
Surface用于展示画面,虽然主流的渲染都需要显示,但是并不是所有的在渲染都需要在本机器的屏幕上显示,因此Vulkan提供了Surface对应的扩展VK_KHR_surface。SurfaceKHR(通常简称为Surface)是一个抽象层,用于表示一个窗口系统的表面(Surface),它是Vulkan与窗口系统之间的桥梁。Surface使得Vulkan能够与操作系统的窗口系统交互,从而进行图形渲染。Surface的创建比较简单直接调用Instance的createDisplayPlaneSurfaceKHR即可,我这里直接使用的GLFW创建的Surface:
cpp
void VulkanInstance::createSurface(GLFWwindow *window){
VkSurfaceKHR surface{};
if(VK_SUCCESS != glfwCreateWindowSurface(*_instance, window, nullptr, &surface)){
throw std::runtime_error("Failed to create window surface");
}
_surface = surface;
}2.3 设备
Vulkan支持多GPU设备渲染,因此需要我们选择进行渲染硬件设备,而实际使用时并不会直接使用该硬件设备,而是在其基础上创建逻辑设备来使用。通过将逻辑设备和物理设备分开,Vulkan提供了更高级别的抽象和灵活性,使得开发者可以根据具体需求选择和管理硬件资源。逻辑设备负责管理和操作与硬件相关的细节,而物理设备则表示实际的硬件设备。在一个应用程序中,可以创建多个实例(VkInstance),每个实例可以使用多个物理设备(VkPhysicalDevice),基于每个物理设备可以创建多个设备(VkDevice). 目前我们使用的是最为简单的组合:一个实例+一个物理设备+一个设备。
创建物理设备比较简单,首先枚举当前机器中的图形设备,然后根据自己的需求进行筛选:
cpp
void VulkanInstance::SelectRunningDevice(){
auto devices = _instance->enumeratePhysicalDevices();
if(devices.empty()){
throw std::runtime_error("No Physical Device found");
}
for(auto &&device : devices){
//LOGI("The {}th device is {}", i, devices[i].)
if(CheckDeviceSuitable(device, _surface)){
_phyDevice = device;
_msaaSamples = GetMaxUsableSampleCount(_phyDevice);
break;//only find one device;
}
}
if(!_phyDevice){
throw std::runtime_error("The device is nullptr, can not find any suitable device");
}
auto phyDevicePro = _phyDevice.getProperties();
LOGI("Select Device Id {} Device name {}", phyDevicePro.deviceID, std::string(phyDevicePro.deviceName));
}逻辑设备创建过程类似于实例创建过程,并描述期望使用的功能。同时Vulkan设备内部的Queue由驱动层管理,上层只能获取对应的Queue来提交指令,如果期望使用多设备处理,比如一个设备进行计算,另一个设备显示,则可以从不同的设备创建逻辑设备并拿到对应的Queue,分别在对应的Queue上提交指令。下面的实现中PreseneQueue和GraphicsQueue虽然在同一个设备上,但是道理是一样的。
cpp
void VulkanInstance::createLogicDevice(){
float priority = 1.0;
auto indics = Utils::Vulkan::QueryQueueFamilyIndices(_phyDevice, _surface);
std::vector<vk::DeviceQueueCreateInfo> queueCreateInfos{};
std::set<uint32_t> queueFamilies = { indics.graphics.value(), indics.present.value() };
for(auto fam : queueFamilies){
queueCreateInfos.emplace_back(
vk::DeviceQueueCreateFlags(),
fam,
1,
&priority);
}
auto deviceFeat = vk::PhysicalDeviceFeatures();
deviceFeat.samplerAnisotropy = vk::True;
auto createInfo = vk::DeviceCreateInfo(
vk::DeviceCreateFlags(),
queueCreateInfos.size(),
queueCreateInfos.data()
);
createInfo.pEnabledFeatures = &deviceFeat;
createInfo.enabledExtensionCount = kDeviceExtensions.size();
createInfo.ppEnabledExtensionNames = kDeviceExtensions.data();
if(gEnableValidationLayer){
createInfo.enabledLayerCount = kValidationLayers.size();
createInfo.ppEnabledLayerNames = kValidationLayers.data();
}
_logicDevice = _phyDevice.createDeviceUnique(createInfo);
_graphicsQueue = _logicDevice->getQueue(indics.graphics.value(), 0);
_presentQueue = _logicDevice->getQueue(indics.present.value(), 0);
}2.4 SwapChain
Vulkan 没有"默认帧缓冲区"的概念,因此它需要一个基础架构,该基础架构将拥有将要渲染的缓冲区,然后才能将它们可视化到屏幕上。这个基础架构称为交换链,必须在 Vulkan 中明确创建。交换链本质上是一个等待呈现到屏幕上的图像队列。应用程序将获取这样的图像来绘制到它上面,然后将其返回到队列。队列的具体工作方式以及从队列呈现图像的条件取决于交换链的设置方式,但交换链的一般目的是将图像的呈现与屏幕的刷新率同步。Swapchain是Vulkan中负责管理窗口系统中图像显示的重要机制,通过它可以实现平滑的图像呈现和防止撕裂现象。它定义了图像的格式、呈现模式和交换链属性,使得应用程序可以与窗口系统集成,并有效地显示渲染结果。通过正确配置和使用Swapchain,应用程序可以实现高效的图形渲染和交互。交换链和Surface相同不都是以扩展的方式体同支持的。
SwapChain的创建和Instance创建差不多。
cpp
void VulkanInstance::createSwapChain(){
VKSwapChainSupportStatus status = Utils::Vulkan::QuerySwapChainStatus(_phyDevice, _surface);
auto format = ChooseSwapSurfaceFormat(status.formats);
auto mode = ChooseSwapPresentMode(status.modes);
auto extent = ChooseSwapExtend(status.capas, _width, _height);
uint32_t imgCount = status.capas.minImageCount + 1;
if(status.capas.maxImageCount > 0 && imgCount > status.capas.maxImageCount){
imgCount = status.capas.maxImageCount;
}
vk::SwapchainCreateInfoKHR createInfo{
vk::SwapchainCreateFlagsKHR(),
_surface,
imgCount,
format.format,
format.colorSpace,
extent,
1,
vk::ImageUsageFlagBits::eColorAttachment
};
auto indics = QueryQueueFamilyIndices(_phyDevice, _surface);
uint32_t famIndics[] = { indics.graphics.value(), indics.present.value()};
if(indics.graphics != indics.present){
createInfo.imageSharingMode = vk::SharingMode::eConcurrent;
createInfo.queueFamilyIndexCount = 2;
createInfo.pQueueFamilyIndices = famIndics;
}else{
createInfo.imageSharingMode = vk::SharingMode::eExclusive;
}
createInfo.preTransform = status.capas.currentTransform;
createInfo.compositeAlpha = vk::CompositeAlphaFlagBitsKHR::eOpaque;
createInfo.presentMode = mode;
createInfo.clipped = VK_TRUE;
//createInfo.oldSwapchain = vk::SwapchainKHR(nullptr);
_swapChain = _logicDevice->createSwapchainKHR(createInfo);
_swapImages = _logicDevice->getSwapchainImagesKHR(_swapChain);
_swapForamt = format.format;
_swapExtent = extent;
}Vulkan中的图像(vk::Image)是用于存储像素数据的对象,而ImageView提供了对这些像素数据的访问方式。它描述了如何将图像的某个特定部分映射到着色器或其他Vulkan操作中,包括图像的格式、范围和用途。因此我们为了和SwapChain的交互需要创建ImageView,然后将ImageView绑定到FrameBufer上。
cpp
void VulkanInstance::createImageViews(){
_swapChainImageViews.resize(_swapImages.size());
for (size_t i = 0; i < _swapImages.size(); i++) {
_swapChainImageViews[i] = CreateImageView(*_logicDevice, _swapImages[i], {_swapForamt, vk::ImageAspectFlagBits::eColor, 1});
}
}Framebuffer(帧缓冲)是用于渲染操作的重要对象,它定义了渲染操作的目标,即将渲染的图像附件。Framebuffer通常用于将渲染操作的输出存储到一个或多个附加的图像或者深度/模板缓冲区中。
cpp
void VulkanInstance::createFrameBuffers(){
_framebuffers.resize(_swapChainImageViews.size());
for (size_t i = 0; i < _swapChainImageViews.size(); i++) {
std::array<vk::ImageView, 3> attachments = {
_colorImageView,
_depthImageView,
_swapChainImageViews[i]
};
vk::FramebufferCreateInfo framebufferInfo = {};
framebufferInfo.renderPass = _renderPass;
framebufferInfo.attachmentCount = attachments.size();
framebufferInfo.pAttachments = attachments.data();
framebufferInfo.width = _swapExtent.width;
framebufferInfo.height = _swapExtent.height;
framebufferInfo.layers = 1;
_framebuffers[i] = _logicDevice->createFramebuffer(framebufferInfo);
}
}2.5 Pipeline
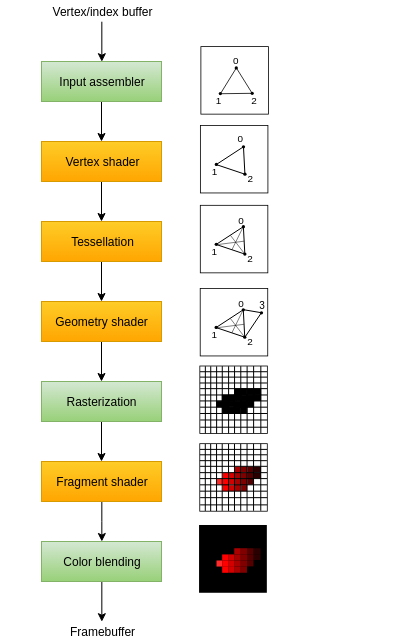
光栅化渲染管线的流程如下,输入组装器从您指定的缓冲区收集原始顶点数据,还可以使用索引缓冲区重复某些元素,而无需复制顶点数据本身。顶点着色器针对每个顶点运行,通常会应用变换将顶点位置从模型空间转换为屏幕空间。它还会将每个顶点的数据传递到管道中。曲面细分着色器允许根据某些规则细分几何体以提高网格质量。这通常用于使砖墙和楼梯等表面在附近时看起来不那么平坦。几何着色器在每个图元(三角形、线、点)上运行,并且可以丢弃它或输出比输入更多的图元。这类似于镶嵌着色器,但更加灵活。光栅化阶段将图元离散化为片段。这些是它们在帧缓冲区上填充的像素元素。任何超出屏幕的片段都将被丢弃,顶点着色器输出的属性将在片段之间进行插值,如图所示。通常,由于深度测试,位于其他图元片段后面的片段也会在此处被丢弃。片段着色器会针对每个幸存的片段调用,并确定将片段写入哪个帧缓冲区以及使用哪些颜色和深度值。它可以使用来自顶点着色器的插值数据来执行此操作,其中可能包括纹理坐标和照明法线等内容。颜色混合阶段应用操作来混合映射到帧缓冲区中同一像素的不同片段。片段可以简单地相互覆盖、相加或基于透明度进行混合。
绿色阶段称为固定功能阶段。橙色的阶段表示programmable。虽然绿色部分时固定的但是Vulkan允许我们对该阶段进行配置。
cpp
void VulkanInstance::createGraphicsPipeline(){
auto vertShaderStr = Utils::FileSystem::ReadFile(FileSystem::PathJoin(kShaderPath, "vert.spv"));
auto fragShaderStr = Utils::FileSystem::ReadFile(FileSystem::PathJoin(kShaderPath, "frag.spv"));
LOGD("Vertex Shader:{}", vertShaderStr.size());
LOGD("Fragment Shader:{}", fragShaderStr.size());
auto vertModule = CreateShaderModule(*_logicDevice, vertShaderStr);
auto fragModule = CreateShaderModule(*_logicDevice, fragShaderStr);
vk::PipelineShaderStageCreateInfo shaderStages[] = {
{
vk::PipelineShaderStageCreateFlags(),
vk::ShaderStageFlagBits::eVertex,
*vertModule,
"main"
},
{
vk::PipelineShaderStageCreateFlags(),
vk::ShaderStageFlagBits::eFragment,
*fragModule,
"main"
}
};
vk::PipelineVertexInputStateCreateInfo vertexInputInfo = {};
vertexInputInfo.vertexBindingDescriptionCount = 0;
vertexInputInfo.vertexAttributeDescriptionCount = 0;
auto bindDesc = Vertex::getBindingDesc();
auto attDesc = Vertex::getAttributeDesc();
vertexInputInfo.vertexBindingDescriptionCount = 1;
vertexInputInfo.pVertexBindingDescriptions = &bindDesc;
vertexInputInfo.vertexAttributeDescriptionCount = attDesc.size();
vertexInputInfo.pVertexAttributeDescriptions = attDesc.data();
vk::PipelineInputAssemblyStateCreateInfo inputAssembly = {};
inputAssembly.topology = vk::PrimitiveTopology::eTriangleList;
inputAssembly.primitiveRestartEnable = VK_FALSE;
vk::Viewport viewport = {};
viewport.x = 0.0f;
viewport.y = 0.0f;
viewport.width = (float)_swapExtent.width;
viewport.height = (float)_swapExtent.height;
viewport.minDepth = 0.0f;
viewport.maxDepth = 1.0f;
vk::Rect2D scissor = {};
scissor.offset = vk::Offset2D{0, 0};
scissor.extent = _swapExtent;
vk::PipelineViewportStateCreateInfo viewportState = {};
viewportState.viewportCount = 1;
viewportState.pViewports = &viewport;
viewportState.scissorCount = 1;
viewportState.pScissors = &scissor;
vk::PipelineRasterizationStateCreateInfo rasterizer = {};
rasterizer.depthClampEnable = VK_FALSE;
rasterizer.rasterizerDiscardEnable = VK_FALSE;
rasterizer.polygonMode = vk::PolygonMode::eFill;
rasterizer.lineWidth = 1.0f;
rasterizer.cullMode = vk::CullModeFlagBits::eBack;
rasterizer.frontFace = vk::FrontFace::eCounterClockwise;
rasterizer.depthBiasEnable = VK_FALSE;
//mass采样,并不是必须阿的
vk::PipelineMultisampleStateCreateInfo multisampling = {};
multisampling.sampleShadingEnable = VK_FALSE;
multisampling.rasterizationSamples = _msaaSamples;
vk::PipelineDepthStencilStateCreateInfo depthStencil{};
depthStencil.depthTestEnable = VK_TRUE;
depthStencil.depthWriteEnable = VK_TRUE;
depthStencil.depthCompareOp = vk::CompareOp::eLess;
depthStencil.depthBoundsTestEnable = VK_FALSE;
depthStencil.stencilTestEnable = VK_FALSE;
vk::PipelineColorBlendAttachmentState colorBlendAttachment = {};
colorBlendAttachment.colorWriteMask = vk::ColorComponentFlagBits::eR | vk::ColorComponentFlagBits::eG | vk::ColorComponentFlagBits::eB | vk::ColorComponentFlagBits::eA;
colorBlendAttachment.blendEnable = VK_FALSE;
vk::PipelineColorBlendStateCreateInfo colorBlending = {};
colorBlending.logicOpEnable = VK_FALSE;
colorBlending.logicOp = vk::LogicOp::eCopy;
colorBlending.attachmentCount = 1;
colorBlending.pAttachments = &colorBlendAttachment;
colorBlending.blendConstants[0] = 0.0f;
colorBlending.blendConstants[1] = 0.0f;
colorBlending.blendConstants[2] = 0.0f;
colorBlending.blendConstants[3] = 0.0f;
vk::PipelineLayoutCreateInfo pipelineLayoutInfo = {};
pipelineLayoutInfo.setLayoutCount = 1;
pipelineLayoutInfo.pSetLayouts = &_descSetLayout;
_renderLayout = _logicDevice->createPipelineLayout(pipelineLayoutInfo);
std::vector<vk::DynamicState> dynamicStates = {
vk::DynamicState::eViewport,
vk::DynamicState::eScissor
};
vk::GraphicsPipelineCreateInfo pipelineInfo = {};
pipelineInfo.stageCount = 2;
pipelineInfo.pStages = shaderStages;
pipelineInfo.pVertexInputState = &vertexInputInfo;
pipelineInfo.pInputAssemblyState = &inputAssembly;
pipelineInfo.pViewportState = &viewportState;
pipelineInfo.pRasterizationState = &rasterizer;
pipelineInfo.pMultisampleState = &multisampling;
pipelineInfo.pColorBlendState = &colorBlending;
pipelineInfo.layout = _renderLayout;
pipelineInfo.renderPass = _renderPass;
pipelineInfo.subpass = 0;
pipelineInfo.basePipelineHandle = nullptr;
pipelineInfo.pDepthStencilState = &depthStencil;
pipelineInfo.pDynamicState = &dynamicState;
_renderPipeline = _logicDevice->createGraphicsPipeline(nullptr, pipelineInfo).value;
}上面创建pipeline需要制定RenderPass,Render Pass定义了渲染操作的结构,包括渲染过程中所使用的所有附件(attachments)及其用法。一个渲染通道可以包括多个子通道(subpasses),每个子通道描述了渲染操作的一部分,如颜色和深度/模板缓冲区的处理方式。一旦创建了Render Pass,它可以被用来执行渲染操作。在渲染过程中,需要使用该Render Pass定义的附件和子通道来记录和执行渲染命令。
cpp
void VulkanInstance::createRenderPass(){
vk::AttachmentDescription colorAttachment = {};
colorAttachment.format = _swapForamt;
colorAttachment.samples = _msaaSamples;
colorAttachment.loadOp = vk::AttachmentLoadOp::eClear;
colorAttachment.storeOp = vk::AttachmentStoreOp::eStore;
colorAttachment.stencilLoadOp = vk::AttachmentLoadOp::eDontCare;
colorAttachment.stencilStoreOp = vk::AttachmentStoreOp::eDontCare;
colorAttachment.initialLayout = vk::ImageLayout::eUndefined;
colorAttachment.finalLayout = vk::ImageLayout::ePresentSrcKHR;
vk::AttachmentDescription depthAttachment{};
depthAttachment.format = FindDepthFormat(_phyDevice);
depthAttachment.samples = _msaaSamples;
depthAttachment.loadOp = vk::AttachmentLoadOp::eClear;
depthAttachment.storeOp = vk::AttachmentStoreOp::eDontCare;
depthAttachment.stencilLoadOp = vk::AttachmentLoadOp::eDontCare;
depthAttachment.stencilStoreOp = vk::AttachmentStoreOp::eDontCare;
depthAttachment.initialLayout = vk::ImageLayout::eUndefined;
depthAttachment.finalLayout = vk::ImageLayout::eDepthStencilAttachmentOptimal;
vk::AttachmentReference colorAttachmentRef = {};
colorAttachmentRef.attachment = 0;
colorAttachmentRef.layout = vk::ImageLayout::eColorAttachmentOptimal;
vk::AttachmentDescription colorAttachmentResolve = {};
colorAttachmentResolve.format = _swapForamt;
colorAttachmentResolve.samples = vk::SampleCountFlagBits::e1;
colorAttachmentResolve.loadOp = vk::AttachmentLoadOp::eDontCare;
colorAttachmentResolve.storeOp = vk::AttachmentStoreOp::eStore;
colorAttachmentResolve.stencilLoadOp = vk::AttachmentLoadOp::eDontCare;
colorAttachmentResolve.stencilStoreOp = vk::AttachmentStoreOp::eDontCare;
colorAttachmentResolve.initialLayout = vk::ImageLayout::eUndefined;
colorAttachmentResolve.finalLayout = vk::ImageLayout::ePresentSrcKHR;
vk::AttachmentReference depthAttachmentRef = {};
depthAttachmentRef.attachment = 1; // 假设深度附件是第二个附件
depthAttachmentRef.layout = vk::ImageLayout::eDepthStencilAttachmentOptimal;
vk::AttachmentReference colorAttachmentResolveRef{};
colorAttachmentResolveRef.attachment = 2;
colorAttachmentResolveRef.layout = vk::ImageLayout::eColorAttachmentOptimal;
vk::SubpassDescription subpass = {};
subpass.pipelineBindPoint = vk::PipelineBindPoint::eGraphics;
subpass.colorAttachmentCount = 1;
subpass.pColorAttachments = &colorAttachmentRef;
subpass.pDepthStencilAttachment = &depthAttachmentRef;
subpass.pResolveAttachments = &colorAttachmentResolveRef;
vk::SubpassDependency dependency = {};
dependency.srcSubpass = VK_SUBPASS_EXTERNAL;
dependency.dstSubpass = 0;
dependency.srcStageMask = vk::PipelineStageFlagBits::eColorAttachmentOutput | vk::PipelineStageFlagBits::eLateFragmentTests;
dependency.dstStageMask = vk::PipelineStageFlagBits::eColorAttachmentOutput | vk::PipelineStageFlagBits::eEarlyFragmentTests;
dependency.srcAccessMask = vk::AccessFlagBits::eColorAttachmentWrite | vk::AccessFlagBits::eDepthStencilAttachmentWrite;
dependency.dstAccessMask = vk::AccessFlagBits::eColorAttachmentWrite | vk::AccessFlagBits::eDepthStencilAttachmentWrite;
std::array<vk::AttachmentDescription, 3> attachments = {colorAttachment, depthAttachment, colorAttachmentResolve};
vk::RenderPassCreateInfo renderPassInfo = {};
renderPassInfo.attachmentCount = attachments.size();
renderPassInfo.pAttachments = attachments.data();
renderPassInfo.subpassCount = 1;
renderPassInfo.pSubpasses = &subpass;
renderPassInfo.dependencyCount = 1;
renderPassInfo.pDependencies = &dependency;
_renderPass = _logicDevice->createRenderPass(renderPassInfo);
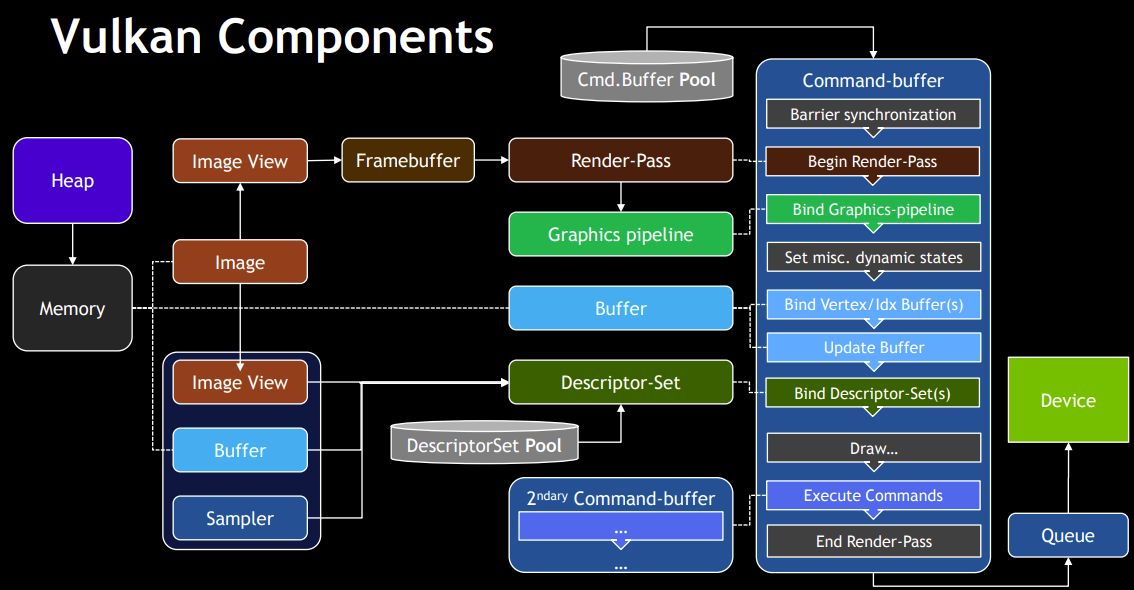
}2.6 CommandPool和CommandBuffer
Vulkan的渲染方式是用户给GPU提交命令来进行渲染的,必须先创建命令池,然后才能创建命令缓冲区。命令池管理用于存储缓冲区的内存,并从中分配命令缓冲区。
cpp
void VulkanInstance::createCommandPool(){
auto queueFamilyIndices = Vulkan::QueryQueueFamilyIndices(_phyDevice, _surface);
vk::CommandPoolCreateInfo poolInfo = {};
poolInfo.queueFamilyIndex = queueFamilyIndices.graphics.value();
poolInfo.flags = vk::CommandPoolCreateFlagBits::eResetCommandBuffer;
_cmdPool = _logicDevice->createCommandPool(poolInfo);
}
cpp
void VulkanInstance::createCommandBuffer(){
_cmdBuffers.resize(_framebuffers.size());
vk::CommandBufferAllocateInfo allocInfo = {};
allocInfo.commandPool = _cmdPool;
allocInfo.level = vk::CommandBufferLevel::ePrimary;
allocInfo.commandBufferCount = (uint32_t)_cmdBuffers.size();
_cmdBuffers = _logicDevice->allocateCommandBuffers(allocInfo);
}2.7 缓冲和纹理
缓冲分为三种:顶点、索引和Uniform缓冲,前两种的创建比较简单直接区别时内存类型不一样。
顶点缓冲(Vertex Buffer)是一种用于存储顶点数据的GPU缓冲区,用于在图形管线中进行渲染操作。顶点缓冲通常包含了顶点的位置、颜色、法线和纹理坐标等信息,这些数据在渲染过程中被传递给着色器程序,用于绘制三维对象的表面。而索引缓存就是描述对应点在顶点缓冲中具体的点的索引,通过索引实现能够降低实际中的内存占用。不然两个不同的模型如果公用相同的点可能需要存储多份,而且有可能出现不同场景计算误差导致模型割裂。
cpp
void VulkanInstance::createVertexBuffer(){
vk::DeviceSize bufferSize = sizeof(_vertices[0]) * _vertices.size();
vk::Buffer stagingBuffer{};
vk::DeviceMemory stagingBufferMemory{};
auto [buffer, bufferMemory] = CreateBuffer(_phyDevice, *_logicDevice, bufferSize, vk::BufferUsageFlagBits::eTransferSrc,
vk::MemoryPropertyFlagBits::eHostVisible | vk::MemoryPropertyFlagBits::eHostCoherent);
auto data = _logicDevice->mapMemory(bufferMemory, 0, bufferSize);
memcpy(data, _vertices.data(), bufferSize);
_logicDevice->unmapMemory(bufferMemory);
auto [buff, buffMemory] = CreateBuffer(_phyDevice, *_logicDevice, bufferSize, vk::BufferUsageFlagBits::eTransferDst | vk::BufferUsageFlagBits::eVertexBuffer,
vk::MemoryPropertyFlagBits::eDeviceLocal);
_vertexBuffer = buff;
_vertexBufferMemory = buffMemory;
copyBuffer(buffer, _vertexBuffer, bufferSize);
_logicDevice->destroyBuffer(buffer);
_logicDevice->freeMemory(bufferMemory);
}
void VulkanInstance::createIndexBuffer(){
vk::DeviceSize bufferSize = sizeof(_indices[0]) * _indices.size();
vk::Buffer stagingBuffer{};
vk::DeviceMemory stagingBufferMemory{};
auto [buffer, bufferMemory] = CreateBuffer(_phyDevice, *_logicDevice, bufferSize, vk::BufferUsageFlagBits::eTransferDst | vk::BufferUsageFlagBits::eIndexBuffer,
vk::MemoryPropertyFlagBits::eHostVisible | vk::MemoryPropertyFlagBits::eHostCoherent);
auto data = _logicDevice->mapMemory(bufferMemory, 0, bufferSize);
memcpy(data, _indices.data(), bufferSize);
_logicDevice->unmapMemory(bufferMemory);
auto [buff, buffMemory] = CreateBuffer(_phyDevice, *_logicDevice, bufferSize, vk::BufferUsageFlagBits::eTransferDst | vk::BufferUsageFlagBits::eIndexBuffer,
vk::MemoryPropertyFlagBits::eDeviceLocal);
_indexBuffer = buff;
_indexMemory = buffMemory;
copyBuffer(buffer, _indexBuffer, bufferSize);
_logicDevice->destroyBuffer(buffer);
_logicDevice->freeMemory(bufferMemory);
}纹理本身的创建和Buffer的创建类似,区别时需要注意纹理内存的Layout,同时UniformBuffer和纹理类似都需要绑定到具体的DescroptorSet上使用。
cpp
void VulkanInstance::createTextureImage(){
int width, height, channel;
auto pixels = stbi_load(GetImageTexurePath().c_str(), &width, &height, &channel, STBI_rgb_alpha);
if(!pixels){
throw std::runtime_error("Failed to load image");
}
_mipLevels = static_cast<uint32_t>(std::floor(std::log2(std::max(width, height)))) + 1;
const vk::DeviceSize imageSize = width * height * 4;
auto [buffer, memory] = CreateBuffer(_phyDevice, *_logicDevice, imageSize, vk::BufferUsageFlagBits::eTransferSrc, vk::MemoryPropertyFlagBits::eHostVisible | vk::MemoryPropertyFlagBits::eHostCoherent);
void *pdata = _logicDevice->mapMemory(memory, 0, imageSize, {});
memcpy(pdata, pixels, imageSize);
_logicDevice->unmapMemory(memory);
stbi_image_free(pixels);
ImageParam param;
param.format = vk::Format::eR8G8B8A8Srgb;
param.size = Size{(uint32_t)width, (uint32_t)height};
param.tiling = vk::ImageTiling::eOptimal;
param.usage = vk::ImageUsageFlagBits::eTransferDst | vk::ImageUsageFlagBits::eSampled | vk::ImageUsageFlagBits::eTransferSrc;
param.properties = vk::MemoryPropertyFlagBits::eDeviceLocal;
param.mipLevel = _mipLevels;
param.msaaSamples = vk::SampleCountFlagBits::e1;
auto context = CommandContext{_cmdPool,
*_logicDevice,
_graphicsQueue,
_phyDevice};
std::tie(_imageTexture, _imageMemory) = CreateImage(param, context);
TransitionImageLayout(_imageTexture, param.format, vk::ImageLayout::eUndefined, vk::ImageLayout::eTransferDstOptimal, context, _mipLevels);
CopyBuffer2Image(buffer, _imageTexture, param.size, context);
//TransitionImageLayout(_imageTexture, param.format, vk::ImageLayout::eTransferDstOptimal, vk::ImageLayout::eShaderReadOnlyOptimal, context);\
_logicDevice->destroyBuffer(buffer);
_logicDevice->freeMemory(memory);
GenerateMipmaps(_imageTexture, param, context);
}Uniform Buffer在Vulkan中是用于传递常量数据到着色器程序的重要机制,它通过GPU缓冲区提供了高效的数据传输和访问方式。正确创建和更新Uniform Buffer可以有效地优化渲染操作,并支持复杂的图形渲染效果和动态变换。
cpp
void VulkanInstance::createUniformBuffer(){
vk::DeviceSize size = sizeof(MVPUniformMatrix);
_mvpBuffer.resize(MAX_FRAMES_IN_FLIGHT);
_mvpData.resize(MAX_FRAMES_IN_FLIGHT);
_mvpMemory.resize(MAX_FRAMES_IN_FLIGHT);
for(auto i = 0;i < MAX_FRAMES_IN_FLIGHT;i ++){
std::tie(_mvpBuffer[i], _mvpMemory[i]) = CreateBuffer(_phyDevice, _logicDevice.get(), size, vk::BufferUsageFlagBits::eUniformBuffer, vk::MemoryPropertyFlagBits::eHostVisible | vk::MemoryPropertyFlagBits::eHostCoherent);
_mvpData[i] = _logicDevice->mapMemory(_mvpMemory[i], 0, size);
}
}
void VulkanInstance::createDescriptorPool(){
std::array<vk::DescriptorPoolSize, 2> poolSizes{};
poolSizes[0].descriptorCount = static_cast<uint32_t>(MAX_FRAMES_IN_FLIGHT);
poolSizes[1].descriptorCount = static_cast<uint32_t>(MAX_FRAMES_IN_FLIGHT);
poolSizes[0].type = vk::DescriptorType::eUniformBuffer;
poolSizes[1].type = vk::DescriptorType::eCombinedImageSampler;
vk::DescriptorPoolCreateInfo poolInfo{};
poolInfo.poolSizeCount = poolSizes.size();
poolInfo.pPoolSizes = poolSizes.data();
poolInfo.maxSets = static_cast<uint32_t>(MAX_FRAMES_IN_FLIGHT);
_descriptorPool = _logicDevice->createDescriptorPool(poolInfo, nullptr);
}描述符布局作用如其名称,描述了对应资源和Shader如何对应,比如shader中写的binding = 0,和怎么指导在指导具体是指哪个资源,就是通过这种方式配置的。
void VulkanInstance::createDescriptorSets(){
std::vector<vk::DescriptorSetLayout> layouts(MAX_FRAMES_IN_FLIGHT, _descSetLayout);
vk::DescriptorSetAllocateInfo allocInfo{};
allocInfo.descriptorPool = _descriptorPool;
allocInfo.descriptorSetCount = static_cast<uint32_t>(MAX_FRAMES_IN_FLIGHT);
allocInfo.pSetLayouts = layouts.data();
_descriptorSets = _logicDevice->allocateDescriptorSets(allocInfo);
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vk::DescriptorBufferInfo bufferInfo{};
bufferInfo.buffer = _mvpBuffer[i];
bufferInfo.offset = 0;
bufferInfo.range = sizeof(MVPUniformMatrix);
vk::DescriptorImageInfo imageInfo{};
imageInfo.imageLayout = vk::ImageLayout::eShaderReadOnlyOptimal;
imageInfo.imageView = _textureView;
imageInfo.sampler = _textureSampler;
std::array<vk::WriteDescriptorSet, 2> descriptorWrites{};
descriptorWrites[0].dstSet = _descriptorSets[i];
descriptorWrites[0].dstBinding = 0;
descriptorWrites[0].dstArrayElement = 0;
descriptorWrites[0].descriptorType = vk::DescriptorType::eUniformBuffer;
descriptorWrites[0].descriptorCount = 1;
descriptorWrites[0].pBufferInfo = &bufferInfo;
descriptorWrites[1].dstSet = _descriptorSets[i];
descriptorWrites[1].dstBinding = 1;
descriptorWrites[1].dstArrayElement = 0;
descriptorWrites[1].descriptorType = vk::DescriptorType::eCombinedImageSampler;
descriptorWrites[1].descriptorCount = 1;
descriptorWrites[1].pImageInfo = &imageInfo;
_logicDevice->updateDescriptorSets(descriptorWrites.size(), descriptorWrites.data(), 0, nullptr);
}
}2.8 同步
Vulkan 的核心设计理念是 GPU 上的执行同步是明确的。操作顺序由我们使用各种同步原语来定义,这些原语会告诉驱动程序我们希望事物运行的顺序。这意味着许多开始在 GPU 上执行工作的 Vulkan API 调用都是异步的,函数将在操作完成之前返回。
信号量用于在队列操作之间添加顺序。Vulkan 中有两种信号量:二进制信号量和时间线信号量。
栅栏隔离具有类似的用途,即用于同步执行,但它用于对 CPU(也称为主机)上的执行进行排序。简而言之,如果主机需要知道 GPU 何时完成某项操作,我们会使用隔离。与信号量类似,栅栏既可以处于有信号状态,也可以处于无信号状态。每当提交要执行的工作时,都可以向该工作附加一个栅栏。当工作完成时,栅栏将发出信号。然后,可以让主机等待栅栏发出信号,从而保证在主机继续执行之前工作已经完成。
3 渲染效果
一切准备完成之后直接向pipeline提交任务即可。
