文章目录
一、准备工作
①在pycharm和jupyter上,检查当前系统是否支持使用 NVIDIA 的 CUDA 加速计算
python
import torch
print(torch.cuda.is_available()) # True②学习pytorch常用的一些方法:
dir():查看对象有什么属性
help():查看对象帮助文档
在pycharm中,可以按ctrl,鼠标点击对象,查询对象帮助文档。
在jupyter中,可以如下格式查询对象文档:对象??
ctrl + p 点击函数的括号,可以显示参数
③加载数据基础
常用两种类:
Dateset: 提供一种方式去获取数据及其label,并对数据编号,
主要实现功能:获取每一个数据及其label。告诉我们总共有多少的数据,
目录结构:
test.py代码:
python
from torch.utils.data import Dataset
from PIL import Image
import os
class MyDate(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx): # Dateset类规定的,必须重写此方法
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyDate(root_dir, ants_label_dir)
bees_dataset = MyDate(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset # 将两个数据集合并
data,label = ants_dataset.__getitem__(0)
print(ants_dataset.img_path)
print(label) # ants
data.show() # 显示图像Dateloader: 为后面的网络提供不同的数据形式。
python
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
# batch_size是每次从数据集取的数据单元数量
# shuffle=True 表示每轮(epoch)选取数据单元时,是否打乱顺序
# num_workers表示执行程序的进程数量。在windows中,多进程执行容易报错。num_workers=0表示只有一个主进程
# drop_last=True 表示最后一组batch数量小于batch_size,则丢弃
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("Epoch:{}".format(epoch),
imgs, step)
step = step + 1
writer.close()二、tensorboard的使用
tensorboard一个是可视化工具
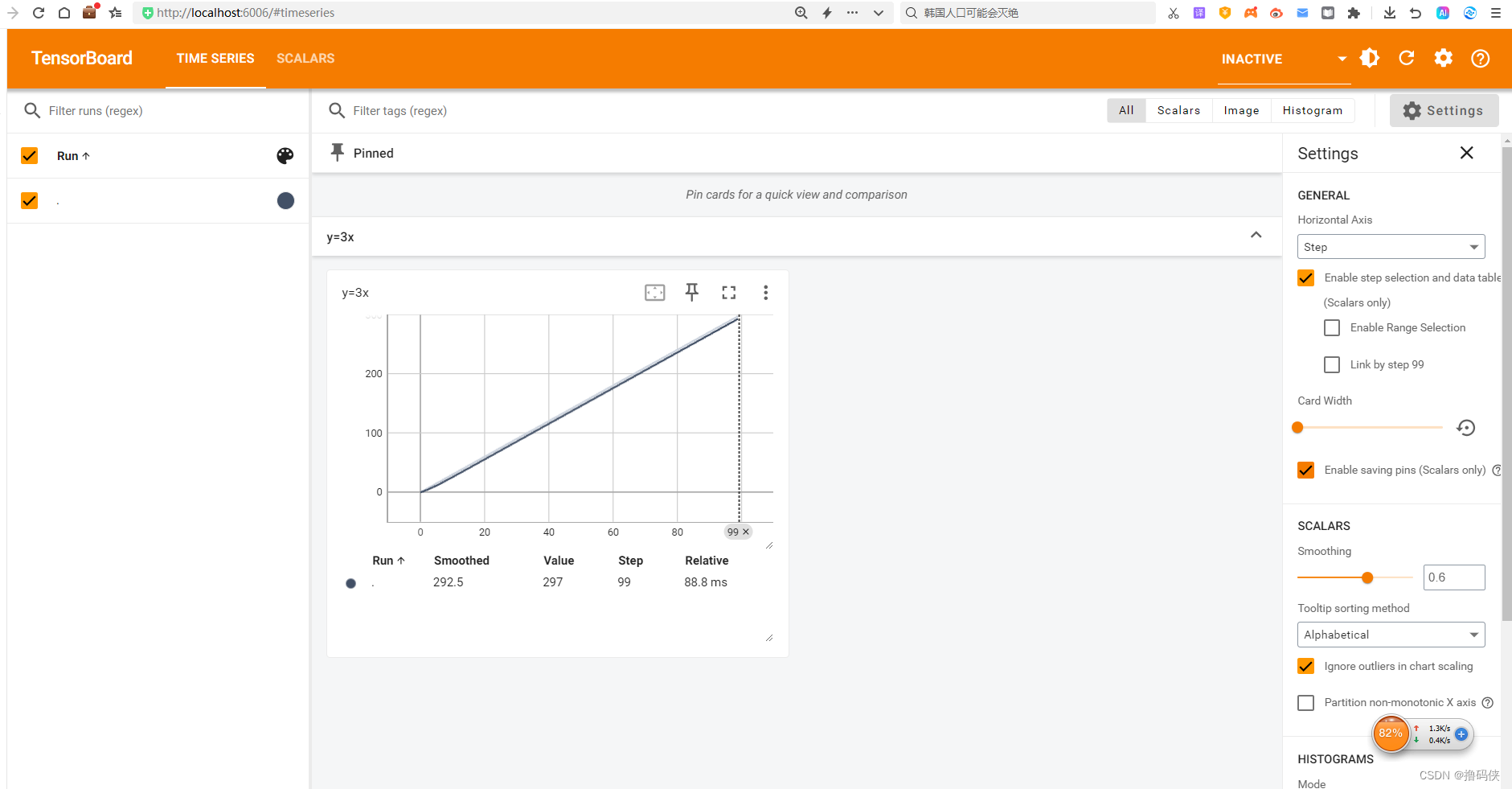
1、add_scalar()方法
python
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
# logs为事件文件所在文件夹
for i in range(100):
writer.add_scalar("y=3x",3*i,i) # scalar为标量
writer.close()先运行上述代码,再在Terminal中执行如下指令:
tensorboard --logdir=logs
出现如下链接:

点击链接,弹出网页:
另外,还可以自定义端口,例:
tensorboard --logdir=logs --port=6007
2、add_image()方法
python
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = "dataset/train/bees/2227611847_ec72d40403.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL) # 将img_PIL转化为numpy数组
print(type(img_array)) # <class 'numpy.ndarray'>
print(img_array.shape) # (450, 500, 3)
writer.add_image("train", img_array, 2, dataformats='HWC')
# HWC分别表示图像的高度、宽度、通道
writer.close()注:运行上述代码,报错AttributeError: module 'PIL.Image' has no attribute 'ANTIALIAS'。解决方法: pip install pillow==9.5.0
三、transforms的使用
transforms主要用来对图片进行一些变化,即:
图片 → transforms的方法 → 结果
1、ToTensor()类
因为tensor方法包含神经网络使用的常用数据,所以常用ToTensor()类进行转换。
python
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path = "dataset//train//bees//17209602_fe5a5a746f.jpg"
img = Image.open(img_path) # 以PIL Image类型打开图片
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img) # 参数img需要PIL Image or numpy.ndarray类型
print(type(tensor_img)) # <class 'torch.Tensor'>
writer = SummaryWriter("logs")
writer.add_image("Tensor_img", tensor_img)
writer.close()opencv是将图片以numpy.ndarray类型打开
python
import cv2
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
img_path = "dataset//train//bees//17209602_fe5a5a746f.jpg"
img = cv2.imread(img_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
print(type(tensor_img)) # <class 'torch.Tensor'>
writer = SummaryWriter("logs")
writer.add_image("Tensor_img2", tensor_img)
writer.close()2、常见transforms的类
python
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset//train//ants//0013035.jpg")
print(img)
# TOTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5, 0.5, 0.5],[0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
# Resize
print(img.size)
trans_resize = transforms.Resize((512,512))
img_resize = trans_resize(img)
print(img_resize)
img_resize = trans_totensor(img_resize)
writer.add_image("Resize",img_resize,0)
# compose()中的参数需要一个列表,列表元素是transforms类型对象
# 输入数据从第一个列表元素开始,顺序执行。
# 前一个列表元素的输出结果,为后一个元素的输入数据
trans_resize_2 = transforms.Resize(100)
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2,1)
# RandomCrop 随机裁剪
trans_random = transforms.RandomCrop(512)
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(9):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
writer.close()三、torchvision中的数据集使用
以CIFAR10数据集为例:
python
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
# root:数据集存放位置。 train:是否为训练集。 download:是否下载数据集,建议设置为True,这样即使下载了,也不会再下载
# 也可以提前把数据集下载到指定目录,下述代码不变,可以自动解压数据集
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
# print(test_set[0])
# print(test_set.classes)
# img, target = test_set[0] # target为label
# print(test_set.classes[target])
# print(img.shape) # torch.Size([3, 32, 32])
# to_pil = transforms.ToPILImage()
# pil_image = to_pil(img)
# pil_image.show()
writer = SummaryWriter("logs")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()