-
Deep Crossing模型(微软,搜索引擎,广告推荐)
前置知识:推荐算法学习笔记1.3:传统推荐算法-逻辑回归算法,推荐算法学习笔记1.4:传统推荐算法-自动特征的交叉解决方案:FM→FFM
本文含残差块反向传播梯度推导 (最后附录)背景概述:用户搜索关键词 → 返回搜索结果以及相关广告。
导出问题:如何提高广告的点击率?
输入:混合类型(类别型,数值型)特征。
输出:点击概率。

细化问题:
①如何解决类别型特征进行one-hot或multi-hot编码后的稀疏问题?
②如何进行自动特征组合?
③如何将得到理想的输出?
解决方案:

①对类别型特征进行嵌入表示(引入了Embedding层)。
②通过Stacking层将多个特征进行堆叠(concatenate),利用神经网络的非线性特征组合能力进行自动特征组合(Multiple Residual Units层, 残差结构)。
③通过Scoring层输出点击概率(分类层)。
附录:
附1:残差结构
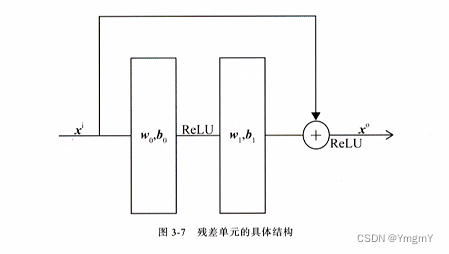
残差结构通过让模型拟合残差而不是映射从而减少网络过拟合的现象发生。即前向传播如下
h ( i + 1 ) = h ( i ) + σ i + 1 ( W i + 1 h ( i ) + b i + 1 ) \mathbf{h}^{(i+1)} = \mathbf{h}^{(i)}+\sigma^{i+1}(\mathbf{W}^{i+1}\mathbf{h}^{(i)}+b^{i+1}) h(i+1)=h(i)+σi+1(Wi+1h(i)+bi+1)
其中假设 h ( i ) = σ i ( W i h ( i − 1 ) + b i ) \mathbf{h}^{(i)} = \sigma^{i}(\mathbf{W}^{i}\mathbf{h}^{(i-1)}+b^{i}) h(i)=σi(Wih(i−1)+bi),则 W i \mathbf{W}^i Wi的反向传播如下
∂ L o s s ∂ W i = ∂ L o s s ∂ h i + 1 ( ∂ h i ∂ W i + ∂ σ i + 1 ∂ ( W i + 1 h ( i ) + b i + 1 ) ( W i + 1 ) T ∂ h i ∂ W i ) = ∂ L o s s ∂ h i + 1 ∂ h i ∂ W i + ∂ L o s s ∂ h i + 1 ∂ σ i + 1 ∂ ( W i + 1 h ( i ) + b i + 1 ) ( W i + 1 ) T ∂ h i ∂ W i \frac{\partial Loss}{\partial \mathbf{W}^i}= \frac{\partial Loss}{\partial \mathbf{h}^{i+1}} (\frac{\partial \mathbf{h}^{i}}{\partial \mathbf{W}^i}+\frac{\partial \sigma^{i+1}}{\partial (\mathbf{W}^{i+1}\mathbf{h}^{(i)}+b^{i+1})}(\mathbf{W}^{i+1})^T\frac{\partial \mathbf{h}^{i}}{\partial \mathbf{W}^i}) \\ =\frac{\partial Loss}{\partial \mathbf{h}^{i+1}} \frac{\partial \mathbf{h}^{i}}{\partial \mathbf{W}^i}+\frac{\partial Loss}{\partial \mathbf{h}^{i+1}} \frac{\partial \sigma^{i+1}}{\partial (\mathbf{W}^{i+1}\mathbf{h}^{(i)}+b^{i+1})}(\mathbf{W}^{i+1})^T\frac{\partial \mathbf{h}^{i}}{\partial \mathbf{W}^i} ∂Wi∂Loss=∂hi+1∂Loss(∂Wi∂hi+∂(Wi+1h(i)+bi+1)∂σi+1(Wi+1)T∂Wi∂hi)=∂hi+1∂Loss∂Wi∂hi+∂hi+1∂Loss∂(Wi+1h(i)+bi+1)∂σi+1(Wi+1)T∂Wi∂hi
从反向传播过程可以看出 W i \mathbf{W}^i Wi的梯度中第一项不会引入后续的参数矩阵 W i + 1 \mathbf{W}^{i+1} Wi+1,所以在一定程度避免了梯度消失的产生。
推荐算法学习笔记2.2:基于深度学习的推荐算法-基于特征交叉组合+逻辑回归思路的深度推荐算法-Deep Crossing模型
YmgmY2024-07-02 13:31
相关推荐
YM52e26 分钟前
鸿蒙 Flutter 渐变效果详解:LinearGradient、RadialGradient、SweepGradient左左右右左右摇晃27 分钟前
手写Tomcat原理整理YM52e28 分钟前
鸿蒙 Flutter BoxDecoration装饰:打造精美UI效果承渊政道1 小时前
【Python学习】(了解使用库、标准库、第三方库以及综合案例实操).Hypocritical.1 小时前
Maven笔记——2乐橙开放平台1 小时前
养殖 SaaS 笔记:乐橙 IoT 物模型管环境,视频 OpenAPI 管回看YM52e2 小时前
鸿蒙Flutter Card组件:Material设计风格卡片YangYang9YangYan3 小时前
2026通信工程专业学生无项目经验学习数据分析的价值与路径love530love10 小时前
【笔记】AutoClaw NSIS 安装器卡死、进程杀不掉、目录删不了?我是这么解决的谙弆悕博士12 小时前
系统集成项目管理工程师教程(第3版)笔记——第2章:信息技术发展